2장 파이썬 코딩 기초#
자료 출처: QuantEcon by Thomas J. Sargent and John Stachurski
이 장에서는 파이썬으로 데이터를 분석하는 데 필요한 가장 기초적인 부분에 대해서 배운다. 가령 우리가 엑셀(Excel)을 전혀 모른다고 할 때, 엑셀로 어떤 데이터세트의 평균과 표준편차를 구하고, 산점도(scatterplot)와 같은 그림을 그리기 위해서는 기본적으로 엑셀을 다루는 법부터 배워야 한다. 엑셀에서 어떻게 데이터를 입력하고, 평균과 표준편차를 구하기 위해서는 어떤 함수를 어떤 식으로 사용하고, 산점도와 같은 그림을 그리고 다듬기 위해서는 어떤 절차를 거쳐야 하는지 알아야 한다. 파이썬도 마찬가지로서 이 장에서는 데이터 분석 자체가 아니라 그것을 하기 위해 어떤 코딩과 절차가 필요한지에 대해 가장 기초적인 부분을 배운다.
2.1 기본 명령문#
함수 및 데이터 유형#
파이썬으로 어떤 작업을 실행할 때 여러 가지 함수(function)를 사용한다. 함수의 이름이 가령 funcname이라면 주피터 노트북의 셀에 funcname(input1, input2) 식으로 적는다. 여기서 괄호안의 input은 함수를 작동하는 데 필요한 입력물로서 인수(argument)라고 부른다. 인수는 필요한 만큼 기입하며, 하나도 없을 수도 있다.
가령 숫자로 된 벡터(vector)를 생성해보자. 이를 위해서는 먼저 numpy라는 라이브러리(혹은 모듈)를 실행해야 한다. 이를 불러들이는 명령문은 import numpy as np이다. numpy를 불러들여(즉 import하여), 이를 간단히 np라는 이름으로 저장한다는 의미다.
이렇게 한 다음, 가령 np.array()라는 함수를 사용하면 벡터를 생성할 수 있다. 즉 이 함수의 괄호안에 숫자 리스트(list)를 인수로 기입하면 된다. 리스트(list)(아래 2.4 파이썬 데이터 기본 유형)는 파이썬의 데이터 유형 중의 하나로서 대괄호를 사용한다.
아래 명령문에서 #으로 시작하는 문장은 코멘트이며 파이썬 인터프리터가 이를 읽어들이지 않기 때문에 참고 사항을 적을 때 사용한다.
import numpy as np # numpy 라이브러리(모듈) 불러들여 'np'로 지정하기
x = np.array([1, 6, 2]) # 벡터 x 정의하기
x
array([1, 6, 2])
이제 두 번째 벡터인 y를 다음과 같이 정의해보자.
y = np.array([1, 4, 3])
위에서 정의한 두 개의 벡터를 각 원소끼리 합치려면 벡터의 길이가 동일해야 한다. 벡터의 길이를 확인하는 함수는 len()이다.
len(x), len(y)
(3, 3)
print(x+y) # x+y 실행 결과를 보기를 원하면 print() 함수를 사용하면 된다.
[ 2 10 5]
np.matrix()는 행렬을 만드는 함수다. 행렬을 만들기 위해서는 일련의 리스트들로 이루어진 리스트를 입력하면 되는데, 이때 각 리스트가 행렬의 행(row)이 된다. 가령 [1, 3]과 [2, 4]라는 2개의 리스트로 이루어진 리스트, 즉 [[1, 3], [2, 4]]을 np.matrix() 함수의 인수로 집어넣으면 1행이 [1, 3]이고, 2행이 [2, 4]인 행렬이 만들어진다.
x = np.matrix([[1, 3], [2, 4]])
x
matrix([[1, 3],
[2, 4]])
만약 데이터가 숫자가 아니라 문자(string)라면, 큰따옴표(“”) 또는 작은따옴표(‘ ’)를 사용하여 입력물이 문자라는 것을 알린다. 리스트(list), 문자(string) 등 데이터 유형에 대해서는 아래 2.4 파이썬 데이터 기본 유형에 보다 자세한 설명이 나와 있다.
y = np.matrix([['서울', '부산'], ['대구', '광주']])
y
matrix([['서울', '부산'],
['대구', '광주']], dtype='<U2')
np.sqrt() 함수는 벡터나 행렬의 제곱근을 반환한다. 제곱을 취할 때는 np.power(x, 2)을 사용한다.
np.sqrt(x), np.power(x, 2)
(matrix([[1. , 1.73205081],
[1.41421356, 2. ]]),
matrix([[ 1, 9],
[ 4, 16]], dtype=int32))
np.random.normal()은 정규 분포(normal distribution)를 따르는 확률변수(random variable)의 무작위숫자(random number)를 생성시키는 함수다. 파라미터(parameter)가 3개인데, loc는 정규 분포의 평균, scale은 표준편차, size는 무작위숫자의 개수를 나타낸다.(함수 코딩에서 파라미터는 함수 정의에 사용된 변수를 말하고, 인수는 함수의 파라미터에 제공된 실제값을 말한다.)
인수를 이 순서대로만 입력하면 인수의 이름, 즉 함수 정의에 사용되는 파라미터 이름 loc=, scale=, size=은 생략해도 된다. 또한 loc, scale의 기본값(default)이 각각 0과 1, 즉 표준정규 분포이기 때문에 표준정규 변수를 원할 경우 이들 인수는 생략하고, np.random.normal(size=5) 식으로 적어도 된다. 그런데 이 경우 np.random.normal(5)로 적으면, 괄호안의 인수 5가 무엇을 의미하는지 모르기 때문에 이때는 해당 파라미터 이름을 생략해서는 안 된다.
np.random.normal(loc=0, scale=1, size=5)
array([ 1.60966416, -0.46221052, -1.16324021, 0.84810272, -0.51853005])
np.random.normal(0, 1, 5)
array([ 0.41009283, 0.93422211, -0.47613176, -1.10475492, -0.6031734 ])
np.random.normal(size=5)
array([-1.76151578, -1.15225007, 0.4803744 , -0.6259432 , 1.63904892])
위에서 보는 것처럼 무작위숫자는 생성할 때마다 숫자가 달라진다. 그런데 경우에 따라서는 무작위숫자를 고정시킬 필요가 있다. 그럴 때는 np.random.seed() 함수를 사용하면 된다. 괄호안에 (자신이 선택한) 임의의 숫자를 기입해 놓으면 언제 어디서든 동일한 무작위숫자를 생성시킬 수 있다.
다음은 x와 y라는 두 개의 서로 관련된 시리즈를 생성시킨 다음, np.corrcoef() 함수를 사용하여 둘 사이의 상관계수 행렬을 구한 것이다.
np.random.seed(123)
x = np.random.normal(0, 1, 50)
y = x + np.random.normal(50, 0.1, 50)
np.corrcoef(x, y)
array([[1. , 0.99599876],
[0.99599876, 1. ]])
np.mean()와 np.var()은 평균과 분산을 구하는 함수다. np.var() 결과에 np.sqrt()을 취하면 표준편차를 얻을 수 있다. 또는 np.std()를 취하면 표준편차를 바로 구할 수 있다.
y = np.random.normal(size=100)
np.mean(y), np.var(y), np.sqrt(np.var(y)), np.std(y)
(-0.019535561910146278,
0.9410039645744331,
0.970053588506549,
0.970053588506549)
그래프#
파이썬에서 그래프를 그리기 위해서는 먼저 matplotlib.pyplot 라이브러리(모듈)를 불러들여야 한다. 이를 plt로 지정하기로 한다.
두 변수 x와 y의 산점도(scatterplot)를 그리는 명령어는 plt.plot(x, y, 'o')이다. 괄호안에 다양한 옵션을 사용할 수 있다.(산점도에 대한 보다 자세한 내용은 아래 산점도 설명을 참조할 것)
또한 추가적인 함수를 사용하여 그래프를 다듬을 수 있다. 가령 plt.xlabel() 함수를 사용하면 가로축 제목(레이블)을 기입할 수 있다.
아래의 첫 번째 줄 명령문 %matplotlib inline은 주피터 노트북 사용자가 자신의 웹 애플리케이션(가령, 크롬)에서 도표를 그리기 위한 것이다.
%matplotlib inline
import matplotlib.pyplot as plt
x = np.random.normal(size=100)
y = np.random.normal(size=100)
plt.figure(figsize=(5,3))
plt.plot(x, y, 'o')
plt.show()
plt.figure(figsize=(5,3))
plt.plot(x, y, 'o')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.title('Plot of X vs Y')
plt.show()
그래프에서 한글이 깨지는 것을 막기 위해서는 아래 명령문을 실행해야 한다.
import platform
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
if platform.system() == 'Darwin': # Mac
rc('font', family='AppleGothic')
elif platform.system() == 'Windows': # Windows
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
else: # Linux (Colab 등)
# 별도 폰트 설치 필요
pass
# 축에 마이너스 부호 제대로 나오게 하기
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(5,3))
plt.plot(x, y, 'o')
plt.xlabel('X축')
plt.ylabel('Y축')
plt.title('산점도(X vs Y)')
plt.show()
수열을 생성하는 함수는 np.arange이다. 가령 np.arange(a, b)은 a에서 b까지(단, b는 포함하지 않음)의 정수 벡터를 생성한다. np.arange(a, b, c)는 a에서 b까지(단, b는 포함하지 않음) c의 간격으로 숫자 벡터를 생성한다.
이와 비슷한 함수로 np.linspace(a, b, n)이 있는데, 이것은 a에서 b까지(이 경우 b를 포함함) 동일한 간격으로 c의 개수만큼 숫자 벡터를 생성한다.
np.arange(1, 11)
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
np.arange(1, 11, 2)
array([1, 3, 5, 7, 9])
np.linspace(1, 9, 5)
array([1., 3., 5., 7., 9.])
x = np.linspace(-np.pi, np.pi, 50) # np.pi는 원주율 파이를 가리킴
x
array([-3.14159265, -3.01336438, -2.88513611, -2.75690784, -2.62867957,
-2.5004513 , -2.37222302, -2.24399475, -2.11576648, -1.98753821,
-1.85930994, -1.73108167, -1.60285339, -1.47462512, -1.34639685,
-1.21816858, -1.08994031, -0.96171204, -0.83348377, -0.70525549,
-0.57702722, -0.44879895, -0.32057068, -0.19234241, -0.06411414,
0.06411414, 0.19234241, 0.32057068, 0.44879895, 0.57702722,
0.70525549, 0.83348377, 0.96171204, 1.08994031, 1.21816858,
1.34639685, 1.47462512, 1.60285339, 1.73108167, 1.85930994,
1.98753821, 2.11576648, 2.24399475, 2.37222302, 2.5004513 ,
2.62867957, 2.75690784, 2.88513611, 3.01336438, 3.14159265])
데이터 인덱싱#
데이터의 일부를 지정하거나 따로 떼어내야 하는 경우가 있다. 다음의 행렬 A를 생각해보자. A는 1부터 16까지 정수를 발생시킨 다음 reshape(4,4) 함수를 사용해 (숫자를 순서대로 사용해서) 4행-4열로 변환시킨 것이다. 아래에 다시 나오겠지만, reshape()처럼 어떤 객체에 (점을 찍고) 붙여 사용하는 함수를 메서드(method)라고 부른다.
A = np.arange(1, 17).reshape(4,4)
A # reshape(4,4)은 np.arange(1, 17)의 수열을 (숫자를 순서대로 사용해서) 4행-4열로 변환함
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12],
[13, 14, 15, 16]])
아래는 어떤 행렬의 행과 열을 바꾸는, 즉 전치행렬(tranpose)을 만드는 메서드인 T의 용법을 보여준다.
A = A.T
A
array([[ 1, 5, 9, 13],
[ 2, 6, 10, 14],
[ 3, 7, 11, 15],
[ 4, 8, 12, 16]])
행렬 A가 위와 같이 주어졌을 때, A[1, 2]를 실행해보자. 여기에서 대괄호 안의 첫 번째 숫자가 행(row)이고, 두 번째 숫자가 열(column)을 가리킨다. 그런데 파이썬에서는 첫 번째 행과 열을 가리킬 때 0행, 0열로 표시한다는 점에 유의해야 한다. 따라서 A[1, 2]이면, 행렬 A의 두 번째 행의 세 번째 열에 있는 원소 10을 반환한다.
콜론(:)으로 다수의 행이나 열을 지정할 수도 있다. 이때 유의할 점은, 가령 0:3행으로 표시하는 경우 0행부터 2행까지를 의미하고, 3행은 포함되지 않는다는 점이다. 전체 행, 또는 전체 열을 지정할 때는 행이나 열의 자리에 콜론만 입력하면 된다.
A[1, 2]
10
A[0:3, 1:4] # 0-2행 1-3열
array([[ 5, 9, 13],
[ 6, 10, 14],
[ 7, 11, 15]])
A[:,0:2] # 모든 행 0-1열
array([[1, 5],
[2, 6],
[3, 7],
[4, 8]])
A[0:2, :] # 0-1행 모든 열
array([[ 1, 5, 9, 13],
[ 2, 6, 10, 14]])
np.shape()는 배열 또는 행렬의 행과 열의 개수를 반환한다.
np.shape(A)
(4, 4)
데이터 로딩#
pandas는 파이썬에서 데이터를 로딩할 때 항상 쓰는 유용한 라이브러리다. pandas를 일단 불러들여 pd로 지정한 다음 데이터를 로딩해보자.
먼저 데이터를 직접 입력하는 예로서 8개 나라에 대해 COUNTRY(나라 이름), POP(인구, 100만 명), AREA(면적, 1,000\(km^2\)), GDP(국내총생산, 100만 USD, 2017년 기준), CONT(대륙), IND_DAY(독립일)을 각각 입력하여 판다스의 기본 데이터 구조인 데이터프레임(DataFrame) 형식의 df라는 이름의 객체로 지정한 것이다.
import pandas as pd
data = {
'CHN': {'COUNTRY': 'China', 'POP': 1398.72, 'AREA': 9596.96,
'GDP': 12_234.78, 'CONT': 'Asia', 'IND_DAY': ''},
'IND': {'COUNTRY': 'India', 'POP': 1351.16, 'AREA': 3287.26,
'GDP': 2575.67, 'CONT': 'Asia', 'IND_DAY': '1947-08-15'},
'USA': {'COUNTRY': 'US', 'POP': 329.74, 'AREA': 9833.52,
'GDP': 19485.39, 'CONT': 'N.America', 'IND_DAY': '1776-07-04'},
'RUS': {'COUNTRY': 'Russia', 'POP': 146.79, 'AREA': 17098.25,
'GDP': 1530.75, 'CONT': '?', 'IND_DAY': '1992-06-12'},
'JPN': {'COUNTRY': 'Japan', 'POP': 126.22, 'AREA': 377.97,
'GDP': 4872.42, 'CONT': 'Asia', 'IND_DAY': ''},
'FRA': {'COUNTRY': 'France', 'POP': 67.02, 'AREA': 640.68,
'GDP': 2582.49, 'CONT': 'Europe', 'IND_DAY': '1789-07-14'},
'GBR': {'COUNTRY': 'UK', 'POP': 66.44, 'AREA': 242.50,
'GDP': 2631.23, 'CONT': 'Europe', 'IND_DAY': ''},
'ITA': {'COUNTRY': 'Italy', 'POP': 60.36, 'AREA': 301.34,
'GDP': 1943.84, 'CONT': 'Europe', 'IND_DAY': ''}
}
df = pd.DataFrame(data=data).T
df
| COUNTRY | POP | AREA | GDP | CONT | IND_DAY | |
|---|---|---|---|---|---|---|
| CHN | China | 1398.72 | 9596.96 | 12234.78 | Asia | |
| IND | India | 1351.16 | 3287.26 | 2575.67 | Asia | 1947-08-15 |
| USA | US | 329.74 | 9833.52 | 19485.39 | N.America | 1776-07-04 |
| RUS | Russia | 146.79 | 17098.25 | 1530.75 | ? | 1992-06-12 |
| JPN | Japan | 126.22 | 377.97 | 4872.42 | Asia | |
| FRA | France | 67.02 | 640.68 | 2582.49 | Europe | 1789-07-14 |
| GBR | UK | 66.44 | 242.5 | 2631.23 | Europe | |
| ITA | Italy | 60.36 | 301.34 | 1943.84 | Europe |
데이터세트에는 결측값(missing values)이 있기 마련이다. 위 경우에는 결측값이 물음표(?)나 빈칸으로 기록돼있다. 이때 values라는 명령어를 이용하여 결측값을 지닌 관측(observations)만 따로 뽑을 수 있다. 명령문의 형식은 df[df.values == '?']이다. df라는 데이터프레임에서 데이터 값(df.values)이 물음표(?)로 돼있는 관측만을 반환하라는 의미다.
df[df.values == '?']
| COUNTRY | POP | AREA | GDP | CONT | IND_DAY | |
|---|---|---|---|---|---|---|
| RUS | Russia | 146.79 | 17098.25 | 1530.75 | ? | 1992-06-12 |
메서드#
바로 위에서 values는 함수와 비슷한 기능을 하면서도 일반적인 함수와 달리 어떤 객체에 붙어서 사용된다. 이런 명령어를 메서드(method)라고 부른다. 어떤 객체(object)에 “부착시켜(attached)” 사용하는 함수다. 위 경우에는 df라는 데이터프레임이 객체이지만 리스트, 문자열(string) 등과 같은 파이썬 객체는 모두 각 객체에 포함된 데이터를 조작하는 데 사용되는 메서드를 가지고 있다. 즉, string 객체에는 string 메서드가 있고, list 객체에는 list 메서드가 있다. 메서드도 넓은 의미에서는 함수에 속하기 때문에 이하에서는 “함수”와 “메서드”라는 용어를 엄격히 구별하지 않기로 한다.
한편, df[df.values == '?']에서 등호가 2개인 것에 유의해야 한다. 등호가 1개인 것과 2개인 것의 차이는, 가령 x=3처럼 등호가 1개면 x값을 3으로 지정(assign)”하는 것이다. 이에 반해, x==3처럼 등호가 2개이면 “만약(if) x값이 3인 경우”를 의미한다. 가령 x==''이면 x값이 빈칸인 경우를 의미한다.
df[df.values == '']
| COUNTRY | POP | AREA | GDP | CONT | IND_DAY | |
|---|---|---|---|---|---|---|
| CHN | China | 1398.72 | 9596.96 | 12234.78 | Asia | |
| JPN | Japan | 126.22 | 377.97 | 4872.42 | Asia | |
| GBR | UK | 66.44 | 242.5 | 2631.23 | Europe | |
| ITA | Italy | 60.36 | 301.34 | 1943.84 | Europe |
replace() 함수를 사용해 물음표나 빈칸으로 돼있는 결측값들을 NaN(Not a Number) 표시의 결측값으로 만들 수도 있다.
pd.set_option('future.no_silent_downcasting', True)
df = df.replace('?', np.NaN)
df = df.replace('', np.NaN)
df
| COUNTRY | POP | AREA | GDP | CONT | IND_DAY | |
|---|---|---|---|---|---|---|
| CHN | China | 1398.72 | 9596.96 | 12234.78 | Asia | NaN |
| IND | India | 1351.16 | 3287.26 | 2575.67 | Asia | 1947-08-15 |
| USA | US | 329.74 | 9833.52 | 19485.39 | N.America | 1776-07-04 |
| RUS | Russia | 146.79 | 17098.25 | 1530.75 | NaN | 1992-06-12 |
| JPN | Japan | 126.22 | 377.97 | 4872.42 | Asia | NaN |
| FRA | France | 67.02 | 640.68 | 2582.49 | Europe | 1789-07-14 |
| GBR | UK | 66.44 | 242.5 | 2631.23 | Europe | NaN |
| ITA | Italy | 60.36 | 301.34 | 1943.84 | Europe | NaN |
판다스의 isnull() 메서드를 values와 결합해 사용하면 데이터 값에 NaN이 들어있는 관측만 뽑아낼 수 있다.
df[df.isnull().values]
| COUNTRY | POP | AREA | GDP | CONT | IND_DAY | |
|---|---|---|---|---|---|---|
| CHN | China | 1398.72 | 9596.96 | 12234.78 | Asia | NaN |
| RUS | Russia | 146.79 | 17098.25 | 1530.75 | NaN | 1992-06-12 |
| JPN | Japan | 126.22 | 377.97 | 4872.42 | Asia | NaN |
| GBR | UK | 66.44 | 242.5 | 2631.23 | Europe | NaN |
| ITA | Italy | 60.36 | 301.34 | 1943.84 | Europe | NaN |
df.shape은 데이터프레임 df의 행과 열이 각각 몇 개인지 알려준다. 아래에서 확인할 수 있듯이 df는 8개 나라에 대해 6개 변수가 있다.
df.shape
(8, 6)
df.dropna()를 사용하면 데이터프레임 df에서 결측값을 지닌 관측들을 제거할 수 있다.
df_dropna = df.dropna()
df_dropna
| COUNTRY | POP | AREA | GDP | CONT | IND_DAY | |
|---|---|---|---|---|---|---|
| IND | India | 1351.16 | 3287.26 | 2575.67 | Asia | 1947-08-15 |
| USA | US | 329.74 | 9833.52 | 19485.39 | N.America | 1776-07-04 |
| FRA | France | 67.02 | 640.68 | 2582.49 | Europe | 1789-07-14 |
df.columns는 데이터프레임 df의 열(변수)의 이름들을 알려준다.
df.columns
Index(['COUNTRY', 'POP', 'AREA', 'GDP', 'CONT', 'IND_DAY'], dtype='object')
Pandas는 행 및 열의 구조로 이루어진 DataFrame뿐만 아니라 Series(1차원), MultiIndex(고차원) 등의 데이터 구조를 사용하며, 위에서 본 것처럼 이런 데이터세트 객체에 부착하여 사용할 수 있는 다양한 메서드들을 제공한다.
데이터 로딩#
데이터 파일을 로딩하는 경우, 데이터의 포맷 형식에 따라 로딩 함수가 달라진다. 파일 형식이 csv 파일인 경우 pd.read_csv() 함수를 사용한다. 괄호안에는 데이터 파일이 있는 위치를 입력해야 한다. 인터넷에서 데이터를 불러들일 수도 있는데, 이때는 괄호안에 URL을 기입한다.(해당 주소로 들어갔을 때 해당 파일이 다운로드 되어야 한다.)
다음은 인터넷에서 자동차 연비(mpg) 관련 데이터(csv 형식)를 불러들여 파이썬의 데이터프레임(dataframe) 포맷 형식으로 바꾸어 Auto라는 이름의 객체로 지정한 것이다.(Auto 데이터에 대해서는 아래 2.2.2절에 분석 사례가 소개된다.)
구분 문자(delimiter)를 콤마(,)로 지정했으며, 데이터가 물음표(?)로 입력된 것은 결측값(NaN)으로 처리하도록 했다. 이처럼 데이터를 로딩할 때 아예 물음표를 결측값으로 처리하지 않으면 해당 변수 전체를 숫자가 아니라 문자 변수로 인식하기 때문이다.(Auto 데이터에서는 horsepower 변수의 일부 값에 물음표가 들어있다.)
import pandas as pd
url = 'https://raw.githubusercontent.com/JWarmenhoven/ISLR-python/master/\
Notebooks/Data/Auto.csv' # 바로 윗 줄 마지막의 "\"은 다음 줄 입력이 계속 연결되는 것을 의미함
Auto = pd.read_csv(url, delimiter=',', na_values=['?'])
Auto.head() # head()는 처음 다섯 개 관측을 반환시킴, 마지막 다섯 개는 tail() 메서드를 사용함
| mpg | cylinders | displacement | horsepower | weight | acceleration | year | origin | name | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 18.0 | 8 | 307.0 | 130.0 | 3504 | 12.0 | 70 | 1 | chevrolet chevelle malibu |
| 1 | 15.0 | 8 | 350.0 | 165.0 | 3693 | 11.5 | 70 | 1 | buick skylark 320 |
| 2 | 18.0 | 8 | 318.0 | 150.0 | 3436 | 11.0 | 70 | 1 | plymouth satellite |
| 3 | 16.0 | 8 | 304.0 | 150.0 | 3433 | 12.0 | 70 | 1 | amc rebel sst |
| 4 | 17.0 | 8 | 302.0 | 140.0 | 3449 | 10.5 | 70 | 1 | ford torino |
Auto[Auto.isnull().values]
| mpg | cylinders | displacement | horsepower | weight | acceleration | year | origin | name | |
|---|---|---|---|---|---|---|---|---|---|
| 32 | 25.0 | 4 | 98.0 | NaN | 2046 | 19.0 | 71 | 1 | ford pinto |
| 126 | 21.0 | 6 | 200.0 | NaN | 2875 | 17.0 | 74 | 1 | ford maverick |
| 330 | 40.9 | 4 | 85.0 | NaN | 1835 | 17.3 | 80 | 2 | renault lecar deluxe |
| 336 | 23.6 | 4 | 140.0 | NaN | 2905 | 14.3 | 80 | 1 | ford mustang cobra |
| 354 | 34.5 | 4 | 100.0 | NaN | 2320 | 15.8 | 81 | 2 | renault 18i |
Auto = Auto.dropna()
Auto.shape
(392, 9)
산점도#
판다스의 plot() 메서드를 이용하여 산점도를 그릴 수 있다. 이때의 명령어 문법은 Auto.plot('cylinders', 'mpg', 'scatter')와 같은 식이다. plot()의 객체로서 데이터프레임 이름을 적고, 괄호 안에는 산점도의 x축과 y축에 해당하는 변수 이름을 입력한 다음, 세 번째 인수로 'scatter'를 적으면 된다.
Auto.plot('cylinders', 'mpg', 'scatter', figsize=(5,3))
plt.show()
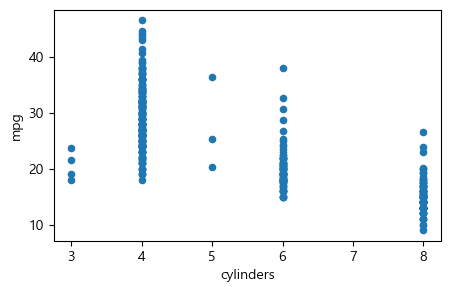
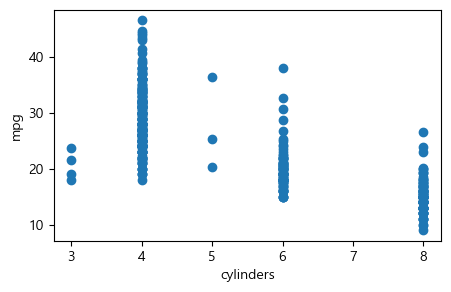
똑같은 산점도를 앞에서 배운 plt.plot(x, y, 'o') 함수로도 그릴 수 있는데, 이때 x와 y에는 아래와 같이 Auto.cylinders와 Auto.mpg를 넣어줘야 한다. 그냥 변수 이름(cylinders, mpg)만 입력하면 그것이 어떤 데이터세트에서 온 것인지 모르기 때문에 에러가 발생한다.
plt.figure(figsize=(5,3))
plt.plot(Auto.cylinders, Auto.mpg, 'o')
plt.xlabel('cylinders')
plt.ylabel('mpg')
plt.show()
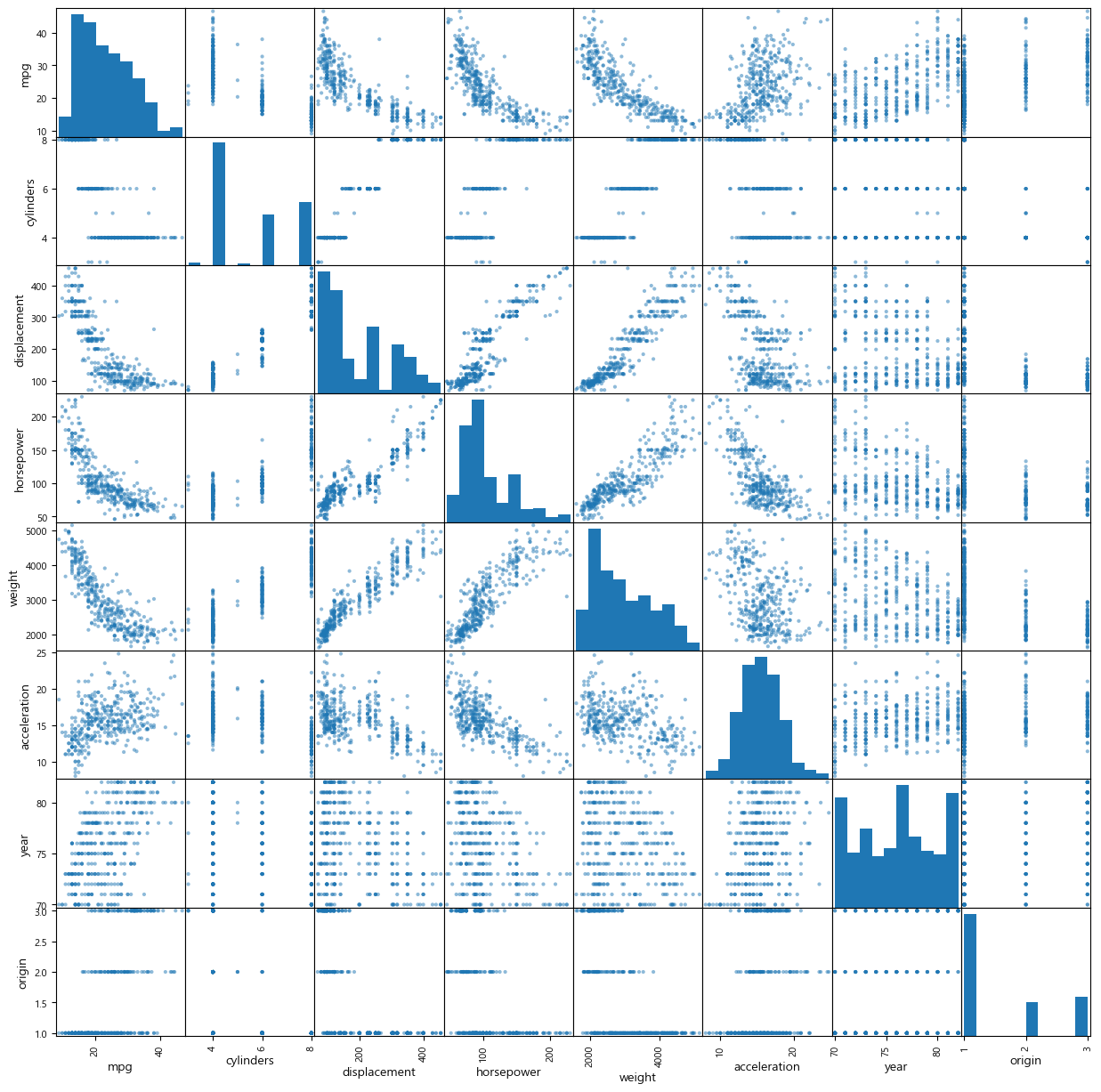
아래는 pd.plotting.scatter_matrix() 함수를 사용해서 Auto 데이터세트의 모든 숫자 변수의 쌍(pair)에 대해 산점도행렬(scatter plot matrix)을 그린 것이다. 행렬의 대각선은 산점도가 정의되지 않기 때문에 산점도 대신 해당 변수의 히스토그램을 그린 것이다. pd.plotting.scatter_matrix() 함수의 괄호안에 데이터세트 이름과 변수 리스트를 입력하면 해당 변수들에 대해서만 산점도행렬을 그릴 수 있다.(아래 명령문의 마지막에 있는 세미콜론은 그림 이외에 다른 텍스트 결과물이 나오지 않게 해준다.)
pd.plotting.scatter_matrix(Auto, figsize=(15,15))
plt.show()
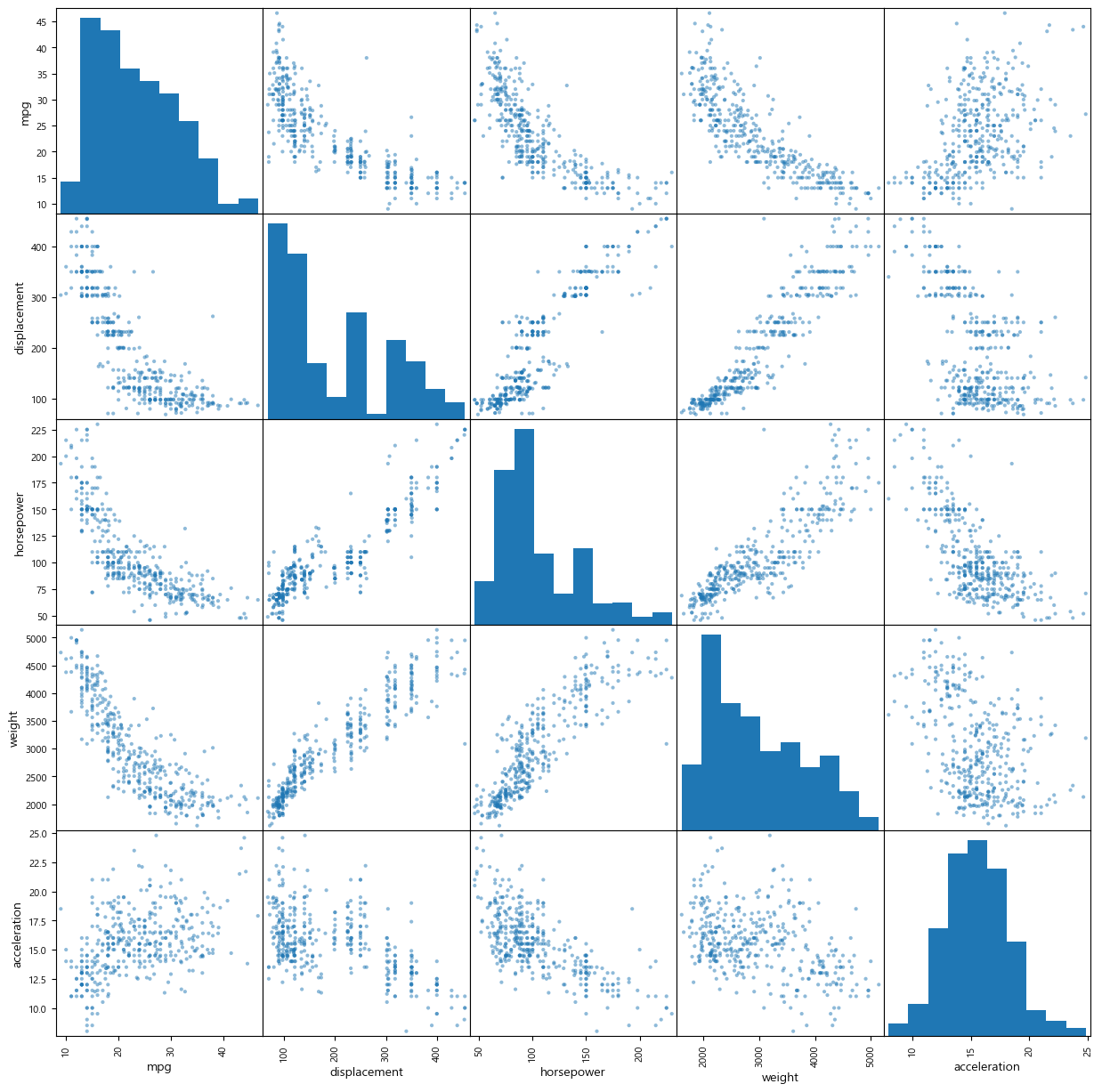
pd.plotting.scatter_matrix(Auto[['mpg', 'displacement', 'horsepower',
'weight', 'acceleration']], figsize=(15,15))
plt.show()
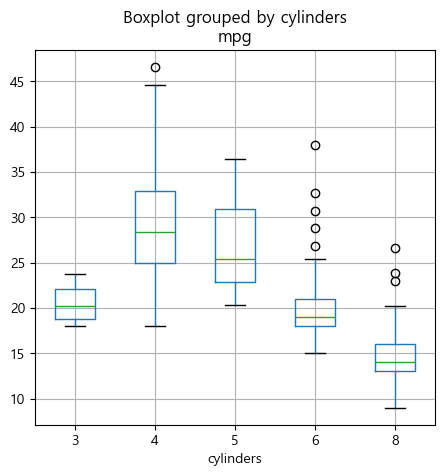
그래프 추가 사항#
상자그림(box plot)
pandas에서 제공하는 boxplot()을 이용해 상자그림(boxplot)을 그릴 수 있다. 아래 2.2 데이터 분석 연습에 상자그림에 대한 좀 더 자세한 내용이 나와 있다.
Auto.boxplot('mpg', 'cylinders', figsize=(5,5))
plt.show()
히스토그램
pandas에서 제공하는 hist()를 이용해 히스토그램(histogram)을 그릴 수 있다. 아래 2.2 데이터 분석 연습에 히스토그램에 대한 좀 더 자세한 내용이 나와 있다.
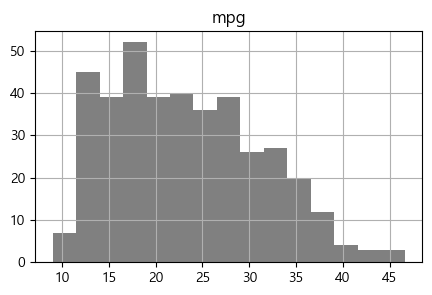
# 히스토그램 그리기
Auto.hist('mpg', color='grey', bins=15, figsize=(5,3))
plt.show()
pandas에서 제공하는 describe() 메서드는 해당 데이터세트의 각 변수에 대해 요약 통계량(summary statistics)을 보여준다. include='all' 옵션을 사용하면 숫자 변수뿐만 아니라 문자형이나 혼합형 등 모든 변수에 대해 요약 통계량을 볼 수 있다.
Auto.describe(include='all')
| mpg | cylinders | displacement | horsepower | weight | acceleration | year | origin | name | |
|---|---|---|---|---|---|---|---|---|---|
| count | 392.000000 | 392.000000 | 392.000000 | 392.000000 | 392.000000 | 392.000000 | 392.000000 | 392.000000 | 392 |
| unique | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 301 |
| top | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | amc matador |
| freq | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 5 |
| mean | 23.445918 | 5.471939 | 194.411990 | 104.469388 | 2977.584184 | 15.541327 | 75.979592 | 1.576531 | NaN |
| std | 7.805007 | 1.705783 | 104.644004 | 38.491160 | 849.402560 | 2.758864 | 3.683737 | 0.805518 | NaN |
| min | 9.000000 | 3.000000 | 68.000000 | 46.000000 | 1613.000000 | 8.000000 | 70.000000 | 1.000000 | NaN |
| 25% | 17.000000 | 4.000000 | 105.000000 | 75.000000 | 2225.250000 | 13.775000 | 73.000000 | 1.000000 | NaN |
| 50% | 22.750000 | 4.000000 | 151.000000 | 93.500000 | 2803.500000 | 15.500000 | 76.000000 | 1.000000 | NaN |
| 75% | 29.000000 | 8.000000 | 275.750000 | 126.000000 | 3614.750000 | 17.025000 | 79.000000 | 2.000000 | NaN |
| max | 46.600000 | 8.000000 | 455.000000 | 230.000000 | 5140.000000 | 24.800000 | 82.000000 | 3.000000 | NaN |
Auto.name.describe()
count 392
unique 301
top amc matador
freq 5
Name: name, dtype: object
Auto.mpg.describe()
count 392.000000
mean 23.445918
std 7.805007
min 9.000000
25% 17.000000
50% 22.750000
75% 29.000000
max 46.600000
Name: mpg, dtype: float64
2.2 데이터 분석 연습#
ISLP 데이터세트#
An Introduction to Statistical Learning with Applications in Python(이하 ISLP)에서 제공하는 여러 데이터세트를 사용해서 파이썬 코딩을 연습해보기로 하자. 해당 교재의 데이터를 다운로드 받는 주소는 https://www.statlearning.com/resources-python이다. 여기에 들어가 “Data Sets” 항목에서 “All .csv files, as .zip”을 클릭하면 데이터세트 zip 파일을 다운로드 받을 수 있다.
미국 대학 데이터#
아래의 College 데이터세트(파일명: “College.csv”)는 ISLP에서 다운로드 받은 것이다. 데이터에는 미국 777개 대학에 대해 다음과 같은 변수들이 들어있다.
Private: 공립/사립 지표Apps: 지원자 수Accept: 합격자 숫자Enroll: 신입생 등록 숫자Top10perc: 고등학교 성적 상위 10% 신입생 비율Top25perc: 고등학교 성적 상위 25% 신입생 비율F.Undergrad: 풀타임(full-time) 학부생 수P.Undergrad: 파트타임(part-time) 학부생 수Outstate: 다른 주에서(out-of-state) 온 학생 수업료Room.Board: 숙식비용Books: 예상 교재비용Personal: 예상 개인 지출PhD: 박사 학위 교수진 비율Terminal: 최종 학위(terminal degree) 교수진 비율S.F.Ratio: 학생/교수 비율perc.alumni: 기부 한 동문 비율Expend: 학생당 수업 지출Grad.Rate: 졸업률
라이브러리 및 데이터 로딩
우선 필요한 파이썬 라이브러리를 불러들인다. numpy는 다차원 배열과 행렬, 그리고 다양한 수학 함수를 지원하고, pandas는 데이터 분석을 지원하며, matplotlib과 seaborn은 그래프 작성을 지원한다. 첫 번째 줄 명령문 %matplotlib inline은 자신의 웹 애플리케이션에서 도표를 그리기 위한 것이다. 또한 마지막 줄 명령문은 숫자 표시를 소수점 둘째 자리로 제한한다.
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
pd.options.display.float_format = '{:,.2f}'.format
ISLP에서 다운로드 받은 “College.csv” 파일을 pandas에서 제공하는 read_csv 함수를 사용하여 데이터프레임 형태로 불러들인다.
저자들의 경우 본 저서와 관련된 모든 주피터 노트북 파일과 데이터 파일을 한 곳에 모아 놓았는데, 그 디렉토리 구조는 아래 그림과 같다.

즉 C:\Python Big Data의 하부에 Code 폴더와 Data 폴더가 들어있는 구조다. 본 주피터 노트북 파일(즉, 2 파이썬 코딩 기초.ipynb)은 Code 폴더에 들어있고, 데이터 파일인 “College.csv”은 Data 폴더에 저장해 놓았다.
이 경우 pd.read_csv() 함수의 괄호 안에 아래와 같이 '../Data/College.csv' 또는 'C:/Python Big Data/Data/College.csv' 식으로 적는다. 여기에서 ../은 현재 주피터 노트북 파일이 실행되고 있는 폴더(Code)의 한 단계 상위 폴더(Python Big Data)를 의미한다.(만약 두 단계 상위 디렉토리로 이동하려면 ../../으로 하면 된다. 반면 ./은 현재 주피터 노트북 파일이 실행되고 있는 폴더를 의미한다.)
College = pd.read_csv('../Data/College.csv')
# College = pd.read_csv('C:/Python Big Data/Data/College.csv')
College.head()
| Unnamed: 0 | Private | Apps | Accept | Enroll | Top10perc | Top25perc | F.Undergrad | P.Undergrad | Outstate | Room.Board | Books | Personal | PhD | Terminal | S.F.Ratio | perc.alumni | Expend | Grad.Rate | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Abilene Christian University | Yes | 1660 | 1232 | 721 | 23 | 52 | 2885 | 537 | 7440 | 3300 | 450 | 2200 | 70 | 78 | 18.10 | 12 | 7041 | 60 |
| 1 | Adelphi University | Yes | 2186 | 1924 | 512 | 16 | 29 | 2683 | 1227 | 12280 | 6450 | 750 | 1500 | 29 | 30 | 12.20 | 16 | 10527 | 56 |
| 2 | Adrian College | Yes | 1428 | 1097 | 336 | 22 | 50 | 1036 | 99 | 11250 | 3750 | 400 | 1165 | 53 | 66 | 12.90 | 30 | 8735 | 54 |
| 3 | Agnes Scott College | Yes | 417 | 349 | 137 | 60 | 89 | 510 | 63 | 12960 | 5450 | 450 | 875 | 92 | 97 | 7.70 | 37 | 19016 | 59 |
| 4 | Alaska Pacific University | Yes | 193 | 146 | 55 | 16 | 44 | 249 | 869 | 7560 | 4120 | 800 | 1500 | 76 | 72 | 11.90 | 2 | 10922 | 15 |
각 행에 대학 이름 레이블 부여
위 데이터세트를 보면, 대학이름들이 나와 있는 0번 열의 이름이 Unnamed: 0으로 돼있다. 또한 각 행의 인덱스가 0부터 776까지의 정수로 돼있다. pandas의 set_index 메서드를 이용하면 대학이름 0번 열을 인덱스로 만들 수 있다. 또한 이렇게 만들어진 인덱스의 이름을 Names로 붙이려고 한다. 이렇게 하면 이제 0번 열은 대학 이름이 아니라 기존에 1번 열이었던 Pravate 열이 된다.
College = College.set_index('Unnamed: 0') # 'Unnamed: 0' 열을 인덱스 열로 함
College.index.name = 'Names' # 인덱스 열의 이름을 'Names'로 지정
College.head()
| Private | Apps | Accept | Enroll | Top10perc | Top25perc | F.Undergrad | P.Undergrad | Outstate | Room.Board | Books | Personal | PhD | Terminal | S.F.Ratio | perc.alumni | Expend | Grad.Rate | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Names | ||||||||||||||||||
| Abilene Christian University | Yes | 1660 | 1232 | 721 | 23 | 52 | 2885 | 537 | 7440 | 3300 | 450 | 2200 | 70 | 78 | 18.10 | 12 | 7041 | 60 |
| Adelphi University | Yes | 2186 | 1924 | 512 | 16 | 29 | 2683 | 1227 | 12280 | 6450 | 750 | 1500 | 29 | 30 | 12.20 | 16 | 10527 | 56 |
| Adrian College | Yes | 1428 | 1097 | 336 | 22 | 50 | 1036 | 99 | 11250 | 3750 | 400 | 1165 | 53 | 66 | 12.90 | 30 | 8735 | 54 |
| Agnes Scott College | Yes | 417 | 349 | 137 | 60 | 89 | 510 | 63 | 12960 | 5450 | 450 | 875 | 92 | 97 | 7.70 | 37 | 19016 | 59 |
| Alaska Pacific University | Yes | 193 | 146 | 55 | 16 | 44 | 249 | 869 | 7560 | 4120 | 800 | 1500 | 76 | 72 | 11.90 | 2 | 10922 | 15 |
다음과 같이 아예 데이터를 로딩할 때 인덱스 열을 Unnamed: 0으로 지정하여 위와 동일한 결과를 얻을 수 있다.
College = pd.read_csv('../Data/College.csv', index_col='Unnamed: 0')
College.index.name = 'Names'
College.head()
| Private | Apps | Accept | Enroll | Top10perc | Top25perc | F.Undergrad | P.Undergrad | Outstate | Room.Board | Books | Personal | PhD | Terminal | S.F.Ratio | perc.alumni | Expend | Grad.Rate | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Names | ||||||||||||||||||
| Abilene Christian University | Yes | 1660 | 1232 | 721 | 23 | 52 | 2885 | 537 | 7440 | 3300 | 450 | 2200 | 70 | 78 | 18.10 | 12 | 7041 | 60 |
| Adelphi University | Yes | 2186 | 1924 | 512 | 16 | 29 | 2683 | 1227 | 12280 | 6450 | 750 | 1500 | 29 | 30 | 12.20 | 16 | 10527 | 56 |
| Adrian College | Yes | 1428 | 1097 | 336 | 22 | 50 | 1036 | 99 | 11250 | 3750 | 400 | 1165 | 53 | 66 | 12.90 | 30 | 8735 | 54 |
| Agnes Scott College | Yes | 417 | 349 | 137 | 60 | 89 | 510 | 63 | 12960 | 5450 | 450 | 875 | 92 | 97 | 7.70 | 37 | 19016 | 59 |
| Alaska Pacific University | Yes | 193 | 146 | 55 | 16 | 44 | 249 | 869 | 7560 | 4120 | 800 | 1500 | 76 | 72 | 11.90 | 2 | 10922 | 15 |
요약 통계량
pandas의 describe() 메서드를 사용하여 데이터세트의 모든 변수에 대해 요약 통계량(summary statistics)을 구할 수 있다. include='all' 옵션을 사용하면 숫자 변수뿐만 아니라 문자형이나 혼합형 등 모든 변수에 대해 요약 통계량을 구할 수 있다.
College.describe(include='all')
| Private | Apps | Accept | Enroll | Top10perc | Top25perc | F.Undergrad | P.Undergrad | Outstate | Room.Board | Books | Personal | PhD | Terminal | S.F.Ratio | perc.alumni | Expend | Grad.Rate | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 777 | 777.00 | 777.00 | 777.00 | 777.00 | 777.00 | 777.00 | 777.00 | 777.00 | 777.00 | 777.00 | 777.00 | 777.00 | 777.00 | 777.00 | 777.00 | 777.00 | 777.00 |
| unique | 2 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| top | Yes | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| freq | 565 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| mean | NaN | 3,001.64 | 2,018.80 | 779.97 | 27.56 | 55.80 | 3,699.91 | 855.30 | 10,440.67 | 4,357.53 | 549.38 | 1,340.64 | 72.66 | 79.70 | 14.09 | 22.74 | 9,660.17 | 65.46 |
| std | NaN | 3,870.20 | 2,451.11 | 929.18 | 17.64 | 19.80 | 4,850.42 | 1,522.43 | 4,023.02 | 1,096.70 | 165.11 | 677.07 | 16.33 | 14.72 | 3.96 | 12.39 | 5,221.77 | 17.18 |
| min | NaN | 81.00 | 72.00 | 35.00 | 1.00 | 9.00 | 139.00 | 1.00 | 2,340.00 | 1,780.00 | 96.00 | 250.00 | 8.00 | 24.00 | 2.50 | 0.00 | 3,186.00 | 10.00 |
| 25% | NaN | 776.00 | 604.00 | 242.00 | 15.00 | 41.00 | 992.00 | 95.00 | 7,320.00 | 3,597.00 | 470.00 | 850.00 | 62.00 | 71.00 | 11.50 | 13.00 | 6,751.00 | 53.00 |
| 50% | NaN | 1,558.00 | 1,110.00 | 434.00 | 23.00 | 54.00 | 1,707.00 | 353.00 | 9,990.00 | 4,200.00 | 500.00 | 1,200.00 | 75.00 | 82.00 | 13.60 | 21.00 | 8,377.00 | 65.00 |
| 75% | NaN | 3,624.00 | 2,424.00 | 902.00 | 35.00 | 69.00 | 4,005.00 | 967.00 | 12,925.00 | 5,050.00 | 600.00 | 1,700.00 | 85.00 | 92.00 | 16.50 | 31.00 | 10,830.00 | 78.00 |
| max | NaN | 48,094.00 | 26,330.00 | 6,392.00 | 96.00 | 100.00 | 31,643.00 | 21,836.00 | 21,700.00 | 8,124.00 | 2,340.00 | 6,800.00 | 103.00 | 100.00 | 39.80 | 64.00 | 56,233.00 | 118.00 |
위 결과를 보면, Private 변수를 제외한 모든 변수들은 숫자형 변수들로서 평균(mean), 표준편차(std), 최소값(min), 최대값(max), 사분위수(25%, 50%, 75%) 등의 통계량이 계산된다.
이에 반해 Private 변수는 Yes와 No의 두 가지 문자로된 범주형 변수이기 때문에 이러한 통계량은 의미가 없고 count(데이터 개수), unique(범주 개수), top(최다수 범주), freq(최다수 범주 빈도수) 등이 제공된다.
산점도행렬
pandas(pd)의 pd.plotting.scatter_matrix() 함수를 사용해서 데이터의 처음 10개 열에 대해 산점도행렬(scatter plot matrix)을 그려보자.
College 데이터세트에서 처음 10개 열을 잘라내 그것을 “College10”이라는 이름으로 지정한 다음, 그것에 대해 pd.plotting.scatter_matrix() 함수를 사용해 산점도행렬을 그리면 된다.
이때 데이터프레임의 일부를 잘라내는 방법 중의 하나는 판다스의 iloc[] 메서드를 사용하는 것이다. 아래는 College.iloc[:,0:10]로 돼있다. 여기에서 0:10는 처음 10개 열(column)을 의미한다.
범주형 변수(즉 Private 변수)와 숫자형 변수 간에는 산점도가 그려지지 않기 때문에 아래와 같이 Private 변수를 제외한 9개 변수의 모든 쌍에 대해 산점도행렬을 얻는다.
College10 = College.iloc[:,0:10]
axes = pd.plotting.scatter_matrix(College10, figsize=(15,15))
plt.show()
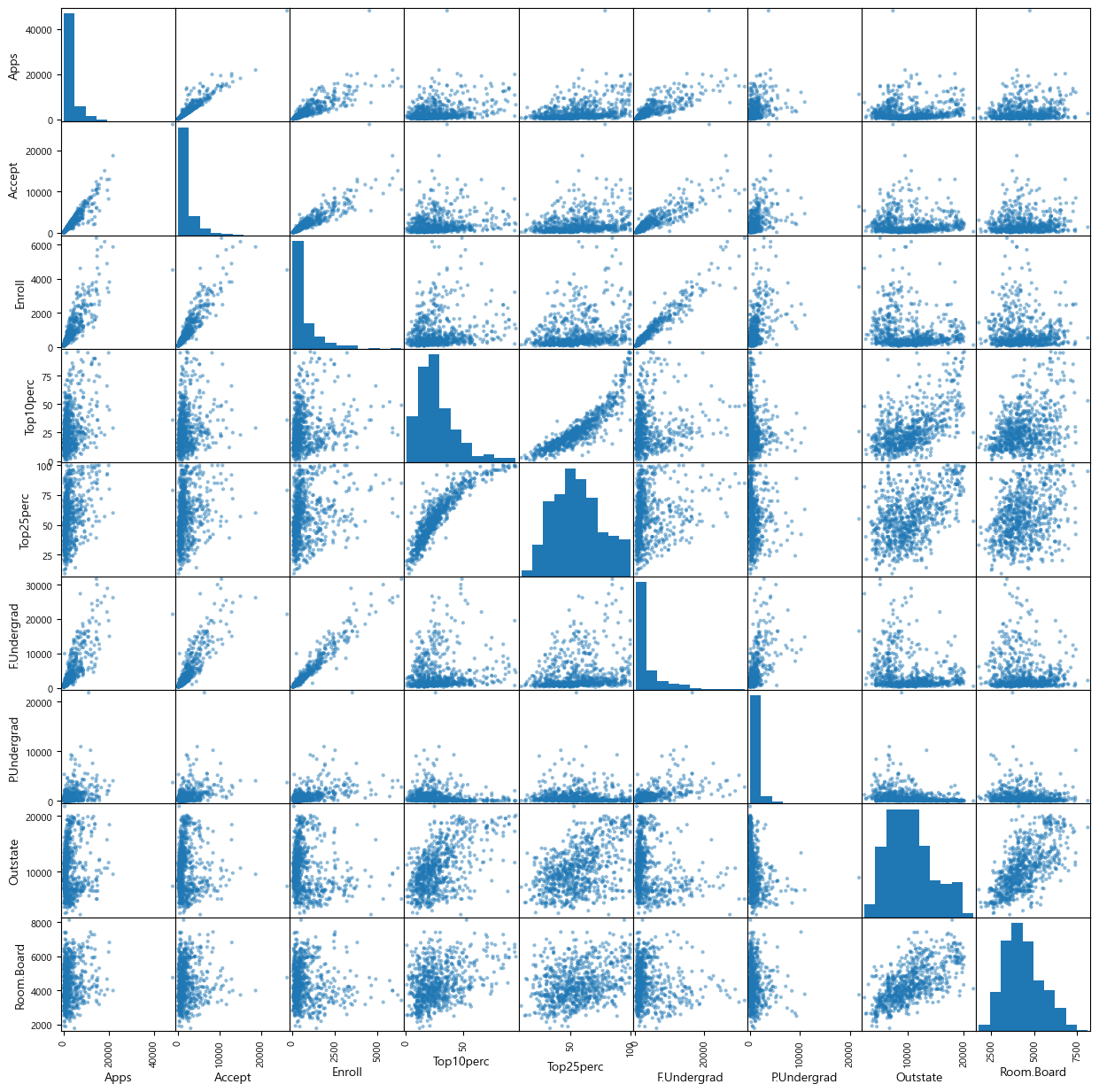
그런데 pd.plotting.scatter_matrix() 함수와 달리 seaborn(sns)의 sns.PairGrid() 함수를 사용하면 범주형 변수(즉 Private 변수)와 숫자형 변수 간에도 산점도를 얻는다. 또한 옵션으로 hue='Private'으로 지정하면, 모든 산점도에서 각 데이터 포인트의 색깔을 Private 변수의 각 범주별로 달리해서 보여준다. 여기에서는 Private의 두 범주 중 Yes가 파란색, No가 오렌지색으로 그려져 있다.
g = sns.PairGrid(College, vars=College.iloc[:,0:10], hue='Private')
g.map_upper(plt.scatter, s=5)
g.map_diag(plt.hist)
g.map_lower(plt.scatter, s=5)
g.fig.set_size_inches(12, 12)
plt.show()
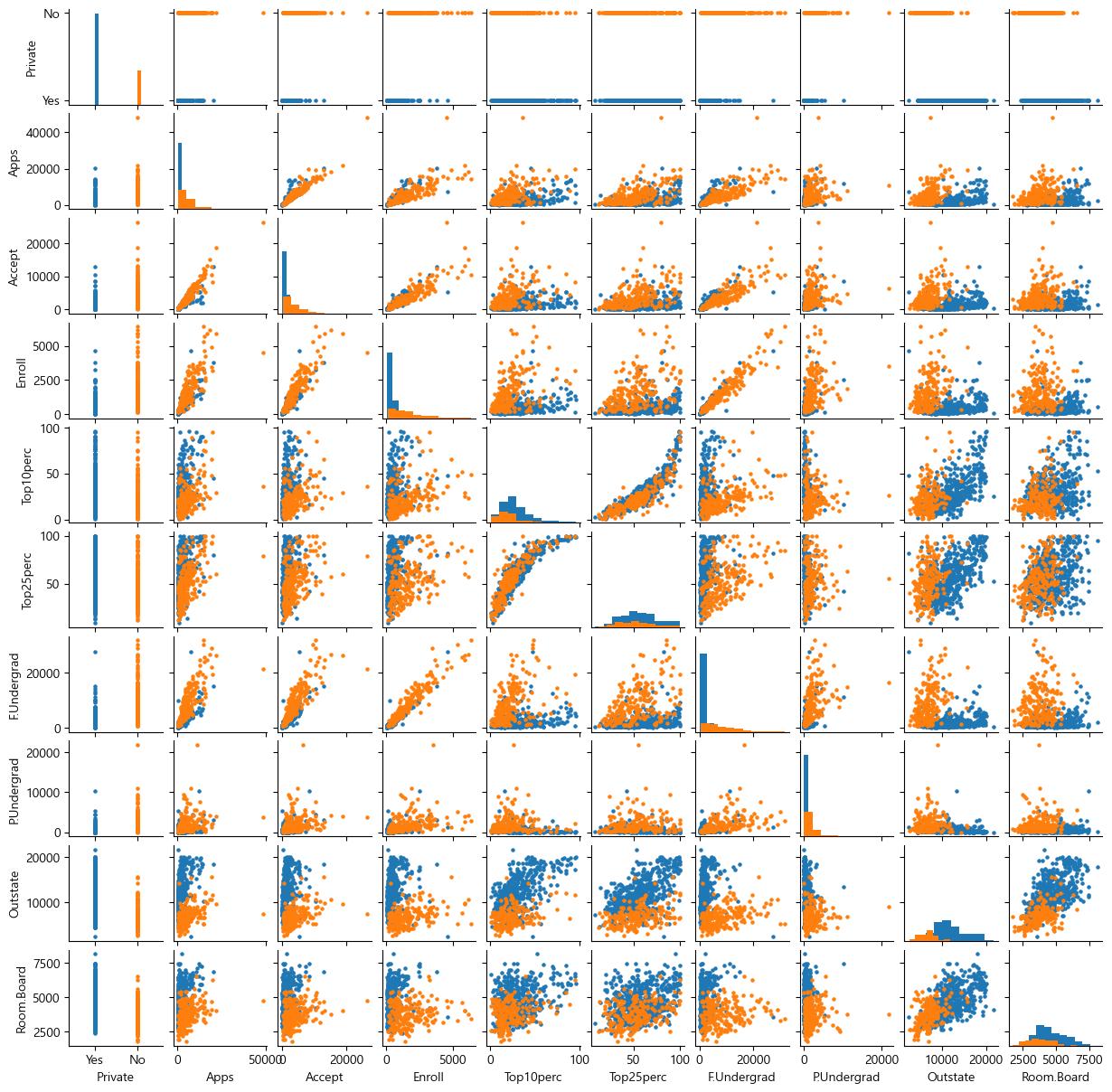
상자그림 그리기
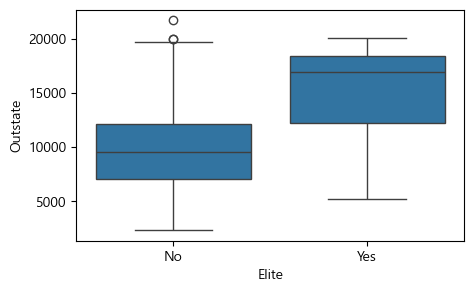
seaborn(sns)의 sns.boxplot() 함수를 사용해서 Outstate vs private의 상자그림(boxplot)을 그려보자.
plt.figure(figsize=(5,3))
sns.boxplot(x='Private', y='Outstate', data=College)
plt.show()
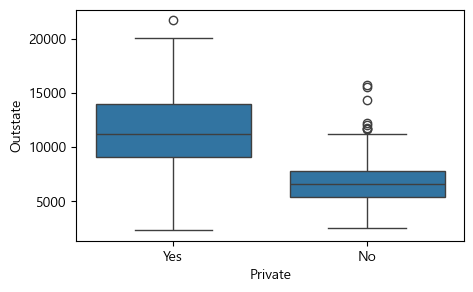
상자그림 읽는 법
우선 가로축이
Private변수이고, 세로축은Outstate변수다.Private변수는Yes와No라는 두 개의 범주를 가진 변수인데, 각 범주에 대해Outstate값이 어떤 분포를 갖고 있는지를 보여준다.가령
Yes범주의 경우, 가운데 파란색 상자가 그려져 있는데 상자의 밑변이Outstate의 제1사분위수를 가리킨다. 또 상자 중앙의 수평선이 제2사분위수(즉 중위값)이고, 상자의 윗변이 제3사분위수를 가리킨다. 상자에서 시작해 위와 아래로 수직선을 길게 그은 다음, 그 끝을 수평선으로 막게 되는데, 이 수평선은 상자 높이(즉 1사분위수와 3사분위수 간의 거리)의 1.5배 거리를 위와 아래에 각각 표시한 것이다.경우에 따라서는 아래쪽 수평선이 데이터의 최소값보다 더 아래쪽이거나, 또는 위쪽 수평선이 데이터의 최대값보다 더 위쪽에 위치하는 경우도 있을 수 있는데, 이때는 데이터 값이 없는 곳에는 선을 긋지 않고 최소값이나 최대값에서 선을 마감한다.
이런 식으로 위와 아래에 수평선을 그은 다음, 그 지점을 벗어나는 데이터에 대해서는 그 값을 작은 점이나 동그라미 등으로 하나씩 표시하는데, 이렇게 함으로써 이상값(outlier)의 분포를 시각적으로 볼 수 있게 해준다.
위 상자그림에서는
Yes와No두 개 범주 모두 아래쪽으로는 이상값이 존재하지 않고, 위쪽으로만 이상값이 존재하는 것을 알 수 있다.
신입생 우수 대학 파악하기
다음 코딩을 통해 각 대학의 신입생 중에서 고등학교 성적이 상위 10%에 드는 학생의 비율이 50%를 초과하는지 여부에 따라 대학을 두 그룹으로 나눈다. 즉 Top10perc 변수를 기준으로 대학들을 그룹핑하여 Elite라는 이름의 새로운 정성적 변수를 만든다.
College.loc[College['Top10perc']>50, 'Elite'] = 'Yes'
College['Elite'] = College['Elite'].fillna('No')
위 코드에서 첫 번째 명령문은 대학 중에서 Top10perc 변수의 값이 50을 초과하면 Yes를 부여하여 Elite라는 이름으로 지정하는 것이고, 두 번째 명령문은 Elite 변수 값에 Yes가 입력되지 않아 결측값인 경우에는 No를 입력하라는 것이다. fillna()는 결측값을 채우는 메서드이다.
첫 번째 명령문에서 사용한 loc[]는 위의 사용 예처럼 레이블을 이용해 데이터프레임의 행과 열을 지정하는 메서드이다. 앞에서 본 iloc[] 역시 loc[]와 마찬가지로 행과 열을 지정하는 기능은 똑같으나, iloc[]는 레이블이 아니라 행과 열의 번호(즉, 위치)를 사용해 행과 열을 지정한다는 점이 다르다.
pandas의 value_counts()를 사용하여 Elite가 Yes인 대학이 몇 개나 되는지 알아보자. 또한 Outstate vs. Elite의 상자그림을 그려보자.
College['Elite'].value_counts()
Elite
No 699
Yes 78
Name: count, dtype: int64
plt.figure(figsize=(5,3))
sns.boxplot(x='Elite', y='Outstate', data=College)
plt.show()
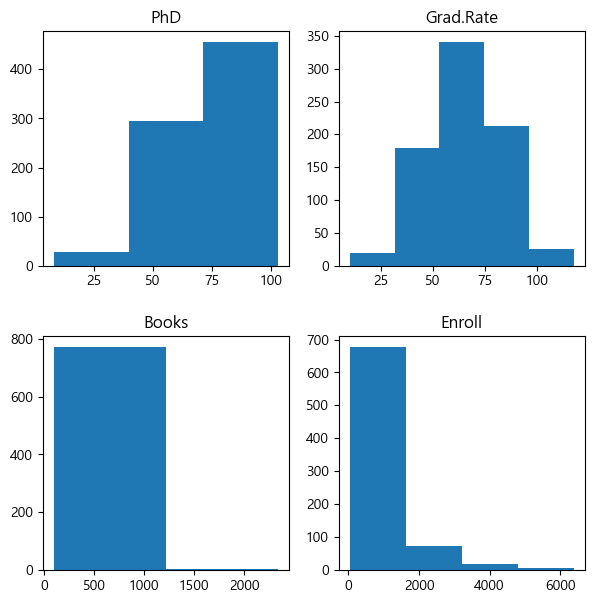
히스토그램 그리기
몇몇 정량적 변수에 대해 히스토그램을 그려보자. 히스토그램은 numpy, pandas 등 여러 라이브러리에서 함수를 제공하고 있지만, 여기에서는 matplotlib.pyplot(plt)을 이용해보자.
아래 코드는 우선 plt.figure() 함수로 그림을 생성하여 fig라는 이름으로 지정한 다음, plt.subplot() 함수를 사용하여 fig 그림 속에 들어갈 하위그림(subplot)을 생성한다. plt.subplot() 괄호안에 221은 1번째 그림을 의미하고, 마찬가지로 222, 223, 224는 2\( \times \)2의 하위그림 중 각각 2번째, 3번째, 4번째 그림을 의미한다. bins 옵션을 이용하여 계급(bin)의 개수를 지정할 수 있다.
# 히스토그램 2x2 그림 만들기
fig = plt.figure(figsize=(7,7))
plt.subplot(221)
_ = plt.hist(College['PhD'], bins=3)
plt.title('PhD')
plt.subplot(222)
_ = plt.hist(College['Grad.Rate'], bins=5)
plt.title('Grad.Rate')
plt.subplot(223)
_ = plt.hist(College['Books'], bins=2)
plt.title('Books')
plt.subplot(224)
_ = plt.hist(College['Enroll'], bins=4)
plt.title('Enroll')
fig.subplots_adjust(hspace=.3) # 하위그림의 위아래 간격을 조정
plt.show()
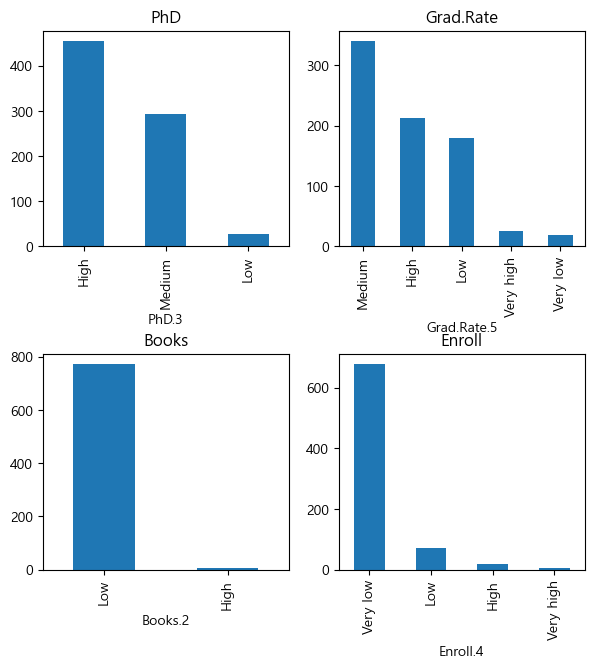
아예 자신이 원하는 계급(bin)을 따로 만들어 히스토그램을 그릴 수도 있다. pandas(pd)의 pd.cut() 함수를 이용하여 데이터를 주어진 개수의 계급으로 나누어 정렬시킬 수 있으며, labels= 파라미터를 이용해서 각 계급에 레이블을 부여할 수 있다. 이렇게 변수별로 계급을 만든 다음, value_counts().plot(kind='bar')를 이용하여 히스토그램을 그린다.
# 계급 만들기
College['PhD.3'] = pd.cut(
College['PhD'], 3, labels=['Low', 'Medium', 'High'])
College['Grad.Rate.5'] = pd.cut(
College['Grad.Rate'], 5, labels=['Very low', 'Low', 'Medium', 'High', 'Very high'])
College['Books.2'] = pd.cut(
College['Books'], 2, labels=['Low', 'High'])
College['Enroll.4'] = pd.cut(
College['Enroll'], 4, labels=['Very low', 'Low', 'High', 'Very high'])
# 히스토그램 2x2 그림 만들기
fig = plt.figure(figsize=(7,7))
plt.subplot(221)
College['PhD.3'].value_counts().plot(kind='bar', title = 'PhD')
plt.subplot(222)
College['Grad.Rate.5'].value_counts().plot(kind='bar', title = 'Grad.Rate')
plt.subplot(223)
College['Books.2'].value_counts().plot(kind='bar', title = 'Books')
plt.subplot(224)
College['Enroll.4'].value_counts().plot(kind='bar', title = 'Enroll')
fig.subplots_adjust(hspace=.5) # 하위그림의 위아래 간격을 조정
plt.show()
자동차 데이터#
데이터세트 로딩
앞에서는 Auto 데이터를 인터넷에서 불러들였는데, 이번에는 바로 앞 절에서와 마찬가지로 ISLP에서 제공하는 데이터를 사용하기로 한다. 앞에서와 마찬가지로 Auto 데이터를 로딩하기 전에 필요한 파이썬 라이브러리를 불러들인다. pandas는 데이터 분석을 지원하고, matplotlib과 seaborn은 그래프 작성을 지원한다. 아울러 아래의 첫 번째 줄 명령문은 자신의 웹 애플리케이션에서 도표를 그리기 위한 것이다. 또한 마지막 줄 명령문은 숫자 표시를 소수점 둘째 자리로 제한한다.
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
pd.options.display.float_format = '{:,.2f}'.format # 숫자 표시를 소수점 둘째 자리로 제한함
Auto = pd.read_csv('../Data/Auto.csv')
Auto
| mpg | cylinders | displacement | horsepower | weight | acceleration | year | origin | name | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 18.00 | 8 | 307.00 | 130 | 3504 | 12.00 | 70 | 1 | chevrolet chevelle malibu |
| 1 | 15.00 | 8 | 350.00 | 165 | 3693 | 11.50 | 70 | 1 | buick skylark 320 |
| 2 | 18.00 | 8 | 318.00 | 150 | 3436 | 11.00 | 70 | 1 | plymouth satellite |
| 3 | 16.00 | 8 | 304.00 | 150 | 3433 | 12.00 | 70 | 1 | amc rebel sst |
| 4 | 17.00 | 8 | 302.00 | 140 | 3449 | 10.50 | 70 | 1 | ford torino |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 392 | 27.00 | 4 | 140.00 | 86 | 2790 | 15.60 | 82 | 1 | ford mustang gl |
| 393 | 44.00 | 4 | 97.00 | 52 | 2130 | 24.60 | 82 | 2 | vw pickup |
| 394 | 32.00 | 4 | 135.00 | 84 | 2295 | 11.60 | 82 | 1 | dodge rampage |
| 395 | 28.00 | 4 | 120.00 | 79 | 2625 | 18.60 | 82 | 1 | ford ranger |
| 396 | 31.00 | 4 | 119.00 | 82 | 2720 | 19.40 | 82 | 1 | chevy s-10 |
397 rows × 9 columns
각 변수들의 의미는 다음과 같다.
mpg: 연비(갤런 당 마일)cylinders: 실린더 개수displacement: 엔진 배기량(큐빅 인치)horsepower: 엔진 마력weight: 차량 무게(파운드)acceleration: 정지 상태에서 시속 60마일 가속 시간(초)year: 모델 연식origin: 자동차 원산지 (1. 미국, 2. 유럽, 3. 일본)name: 차량 이름
origin과 name은 정성적이고 나머지는 정량적이다. origin 변수는 숫자형이기는 하지만 숫자 크기가 의미를 지니는 것은 아니고 단지 범주를 나누는 데 사용되기 때문에 범주형 변수다.
데이터프레임 정보
pandas의 info()는 데이터프레임에 대해 기본적인 정보를 알려주는 메서드이다. 각 열 변수의 이름, 결측값(null)이 아닌 값의 개수, 데이터 유형(dtype) 및 메모리 사용량 등을 알 수 있다. 데이터 유형에서 float64는 64비트 저장 공간을 차지하는 실수(즉 소수점 숫자), int64는 64비트 저장 공간을 차지하는 정수, object는 문자형(범주형) 변수를 가리킨다.
Auto.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 397 entries, 0 to 396
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mpg 397 non-null float64
1 cylinders 397 non-null int64
2 displacement 397 non-null float64
3 horsepower 397 non-null object
4 weight 397 non-null int64
5 acceleration 397 non-null float64
6 year 397 non-null int64
7 origin 397 non-null int64
8 name 397 non-null object
dtypes: float64(3), int64(4), object(2)
memory usage: 28.0+ KB
ChatGPT Q&A#
다음 결과에 대해 설명해줘.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 397 entries, 0 to 396 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 mpg 397 non-null float64 1 cylinders 397 non-null int64 2 displacement 397 non-null float64 3 horsepower 397 non-null object 4 weight 397 non-null int64 5 acceleration 397 non-null float64 6 year 397 non-null int64 7 origin 397 non-null int64 8 name 397 non-null object dtypes: float64(3), int64(4), object(2) memory usage: 28.0+ KB
이 결과는 Pandas 라이브러리의 DataFrame 객체에 대한 정보를 요약하여 보여주고 있습니다. DataFrame은 행과 열로 이루어진 테이블 형태의 데이터 구조입니다. 각각의 부분에 대해 설명하겠습니다.
<class 'pandas.core.frame.DataFrame'>:
이 부분은 현재 객체가 Pandas의
DataFrame클래스에 속한다는 것을 나타냅니다.
RangeIndex: 397 entries, 0 to 396:
이 DataFrame은 총 397개의 행을 가지고 있습니다.
행 인덱스는 0부터 시작하여 396까지 번호가 매겨져 있습니다.
Data columns (total 9 columns)::
이 DataFrame은 총 9개의 열(column)을 가지고 있습니다.
열별 상세 정보:
각 열의 이름, 비어 있지 않은 값의 개수(Non-Null Count), 그리고 데이터 타입(Dtype)이 나열됩니다.
예를 들어, 첫 번째 열 ‘mpg’는 397개의 비어 있지 않은 (
non-null) 값이 있고, 데이터 타입은float64입니다.
cylinders,weight,year,origin열은 정수형(int64) 데이터를 갖고 있습니다.
displacement,acceleration열도 부동소수점(float64) 데이터입니다.
horsepower,name열은 문자열(object) 데이터입니다.
memory usage: 28.0+ KB:
이 DataFrame이 메모리에서 차지하는 대략적인 크기는 28.0 킬로바이트입니다.
이 요약 정보는 데이터의 구조, 데이터 타입, 메모리 사용량 등을 빠르게 파악하는 데 유용합니다. 이를 통해 데이터 분석이나 처리 전에 데이터셋의 개요를 이해할 수 있습니다.
위 결과를 보면, Non-Null의 개수가 모두 397개로서 값이 입력되지 않은 결측값은 없는 것으로 나타났다. 하지만 horsepower(마력)의 데이터 유형이 우리가 알고 있는 정수가 아니라 문자형 변수로 잘못 읽어진 것을 알 수 있다. 그 이유를 알기 위해 unique() 메서드를 사용하여 아래와 같이 Auto 데이터세트 horsepower 변수의 모든 중복되지 않은 값들을 프린트시켜 봤더니 23번째 값에 ?이 있다. 즉 horsepower 데이터 값중에 ?으로 입력된 값이 있어서 이 변수의 모든 값이 숫자형이 아니라 문자형으로 읽힌 것이다.
Auto.horsepower.unique()
array(['130', '165', '150', '140', '198', '220', '215', '225', '190',
'170', '160', '95', '97', '85', '88', '46', '87', '90', '113',
'200', '210', '193', '?', '100', '105', '175', '153', '180', '110',
'72', '86', '70', '76', '65', '69', '60', '80', '54', '208', '155',
'112', '92', '145', '137', '158', '167', '94', '107', '230', '49',
'75', '91', '122', '67', '83', '78', '52', '61', '93', '148',
'129', '96', '71', '98', '115', '53', '81', '79', '120', '152',
'102', '108', '68', '58', '149', '89', '63', '48', '66', '139',
'103', '125', '133', '138', '135', '142', '77', '62', '132', '84',
'64', '74', '116', '82'], dtype=object)
아래 첫 번째 명령문은 Auto 데이터세트에서 Auto.horsepower 변수의 값이 ?이 아닌 행들로만 이루어진 데이터프레임을 Auto라는 이름으로 재지정(overwrite)한 것이다. 이때 copy() 메서드를 사용함으로써 새롭게 생성된 데이터프레임이 과거의 데이터프레임으로부터 간섭받지 않도록 했다.
아래 두 번째 명령문은 pd.to_numeric() 함수를 사용하여 Auto.horsepower 변수의 데이터 유형을 기존의 문자형에서 숫자형으로 바꿔준다.
Auto = Auto[Auto.horsepower != '?'].copy()
Auto['horsepower'] = pd.to_numeric(Auto['horsepower'])
Auto
| mpg | cylinders | displacement | horsepower | weight | acceleration | year | origin | name | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 18.00 | 8 | 307.00 | 130 | 3504 | 12.00 | 70 | 1 | chevrolet chevelle malibu |
| 1 | 15.00 | 8 | 350.00 | 165 | 3693 | 11.50 | 70 | 1 | buick skylark 320 |
| 2 | 18.00 | 8 | 318.00 | 150 | 3436 | 11.00 | 70 | 1 | plymouth satellite |
| 3 | 16.00 | 8 | 304.00 | 150 | 3433 | 12.00 | 70 | 1 | amc rebel sst |
| 4 | 17.00 | 8 | 302.00 | 140 | 3449 | 10.50 | 70 | 1 | ford torino |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 392 | 27.00 | 4 | 140.00 | 86 | 2790 | 15.60 | 82 | 1 | ford mustang gl |
| 393 | 44.00 | 4 | 97.00 | 52 | 2130 | 24.60 | 82 | 2 | vw pickup |
| 394 | 32.00 | 4 | 135.00 | 84 | 2295 | 11.60 | 82 | 1 | dodge rampage |
| 395 | 28.00 | 4 | 120.00 | 79 | 2625 | 18.60 | 82 | 1 | ford ranger |
| 396 | 31.00 | 4 | 119.00 | 82 | 2720 | 19.40 | 82 | 1 | chevy s-10 |
392 rows × 9 columns
Auto.info()
<class 'pandas.core.frame.DataFrame'>
Index: 392 entries, 0 to 396
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mpg 392 non-null float64
1 cylinders 392 non-null int64
2 displacement 392 non-null float64
3 horsepower 392 non-null int64
4 weight 392 non-null int64
5 acceleration 392 non-null float64
6 year 392 non-null int64
7 origin 392 non-null int64
8 name 392 non-null object
dtypes: float64(3), int64(5), object(1)
memory usage: 30.6+ KB
이제는 horsepower 변수의 데이터 유형이 정수형(int64)으로 바뀌었으며, 그 과정에서 ?으로 표시된 결측값 5개가 제거되어 관측 개수가 397개에서 392개로 줄어든 것을 알 수 있다.
Boston 주택 가격 데이터#
Boston 주택 가격 데이터 역시 ISLP에서 제공하는 데이터를 사용하기로 한다(파일명: Boston.csv). 데이터를 로딩하기 전에 필요한 파이썬 라이브러리를 불러들인다.
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
데이터 로딩
보스턴 주택 가격 데이터를 Boston이라는 이름으로 로딩한 다음, 각 열의 변수명을 편의상 원래의 소문자에서 대문자로 바꿨다.
Boston = pd.read_csv('../Data/Boston.csv', index_col='Unnamed: 0')
Boston.columns = map(str.upper, Boston.columns) # 변수명 대문자로 바꾸기
Boston
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.01 | 18.00 | 2.31 | 0 | 0.54 | 6.58 | 65.20 | 4.09 | 1 | 296 | 15.30 | 4.98 | 24.00 |
| 2 | 0.03 | 0.00 | 7.07 | 0 | 0.47 | 6.42 | 78.90 | 4.97 | 2 | 242 | 17.80 | 9.14 | 21.60 |
| 3 | 0.03 | 0.00 | 7.07 | 0 | 0.47 | 7.18 | 61.10 | 4.97 | 2 | 242 | 17.80 | 4.03 | 34.70 |
| 4 | 0.03 | 0.00 | 2.18 | 0 | 0.46 | 7.00 | 45.80 | 6.06 | 3 | 222 | 18.70 | 2.94 | 33.40 |
| 5 | 0.07 | 0.00 | 2.18 | 0 | 0.46 | 7.15 | 54.20 | 6.06 | 3 | 222 | 18.70 | 5.33 | 36.20 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 502 | 0.06 | 0.00 | 11.93 | 0 | 0.57 | 6.59 | 69.10 | 2.48 | 1 | 273 | 21.00 | 9.67 | 22.40 |
| 503 | 0.05 | 0.00 | 11.93 | 0 | 0.57 | 6.12 | 76.70 | 2.29 | 1 | 273 | 21.00 | 9.08 | 20.60 |
| 504 | 0.06 | 0.00 | 11.93 | 0 | 0.57 | 6.98 | 91.00 | 2.17 | 1 | 273 | 21.00 | 5.64 | 23.90 |
| 505 | 0.11 | 0.00 | 11.93 | 0 | 0.57 | 6.79 | 89.30 | 2.39 | 1 | 273 | 21.00 | 6.48 | 22.00 |
| 506 | 0.05 | 0.00 | 11.93 | 0 | 0.57 | 6.03 | 80.80 | 2.50 | 1 | 273 | 21.00 | 7.88 | 11.90 |
506 rows × 13 columns
위에서 맨 마지막 열에 있는 타겟(종속) 변수 MEDV는 1978년 보스턴 주택 가격으로서 506개 타운별로 소유주 점유 주택 가격의 중위값(단위 1,000달러)을 기록한 것이다. 이를 설명하기 위한 특성(설명) 변수는 다음과 같다.
CRIM: 타운별 1인당 범죄율ZN: 25,000 제곱피트 초과 거주지역 비율INDUS: 타운별 비소매 상업지역 면적 비율CHAS: 지역이 찰스강에 접한 경우는 1, 아니면 0NOX: 질소산화물 농도(천만 분의 1)RM: 주택당 평균 방 수AGE: 소유주 점유 주택 중 1940년 이전 건축된 비율DIS: 5개 보스턴 직업센터와의 가중평균 거리RAD: 순환 고속도로까지의 접근성TAX: 총재산세율(1만 달러당)PTRATIO: 타운별 학생/교사 비율LSTAT: 인구 중 하위 계층 비율
위 결과를 보면 Boston 데이터세트의 관측은 506개이고 변수는 총 13개다. 각 행은 506개 타운별 관측이다.
1인당 범죄율과 상관성이 높은 예측변수 찾기
pandas에서 제공하는 corrwith() 메서드를 사용하여 데이터세트(Boston)의 각 열들과 1인당 범죄율(CRIM)과의 상관계수를 구해보자. 이때 pandas에서 제공하는 sort_values() 메서드를 사용하여 상관계수를 내림차순으로 정렬시킬 수 있다.
Boston.corrwith(Boston['CRIM']).sort_values(ascending=False)
CRIM 1.00
RAD 0.63
TAX 0.58
LSTAT 0.46
NOX 0.42
INDUS 0.41
AGE 0.35
PTRATIO 0.29
CHAS -0.06
ZN -0.20
RM -0.22
DIS -0.38
MEDV -0.39
dtype: float64
1인당 범죄율(CRIM)과 상관계수가 가장 큰 3개 변수, 즉 RAD(순환 고속도로까지의 접근성), TAX(총재산세율, 1만 달러당), LSTAT(인구 중 하위 계층 비율)에 대해 조금 더 자세히 분석해보자.
먼저 RAD 변수의 경우 숫자형 변수이지만 총 9개의 정수로만 이루어져있다. 사실상 범주형 변수라 할 수 있다. 이런 변수의 경우 pandas의 groupby() 메서드를 이용하여 그룹별 빈도수를 확인해볼 수 있다.
Boston.groupby('RAD').size()
RAD
1 20
2 24
3 38
4 110
5 115
6 26
7 17
8 24
24 132
dtype: int64
따라서 산점도가 아니라 상자도표(boxplot)를 이용하여 RAD와 CRIM의 관계를 그림으로 그려보자. 아래 그림을 보면 눈에 띄게 확실한 것은 아니지만 두 변수의 플러스 상관관계를 짐작해볼 수 있다.
plt.figure(figsize=(5,3))
sns.boxplot(x='RAD', y='CRIM', data=Boston)
plt.show()
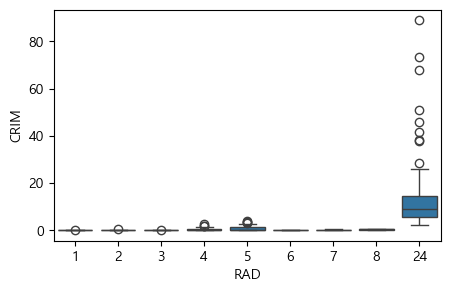
각 RAD(순환 고속도로까지의 접근성) 별로 1인당 범죄율(CRIM)이 평균적으로 어느 정도인지를 계산해 볼 수도 있다. groupby 메서드를 사용하여 각 RAD 그룹별로 CRIM 변수의 평균값을 구할 수 있다.
아래 결과를 보면 뚜렷한 선형의 관계는 아니지만 순환 고속도로까지의 접근성이 3 이하인 타운은 1인당 범죄율이 매우 낮고, 순환 고속도로까지의 접근성 가장 높은 24인 경우에는 1인당 범죄율이 뚜렷이 높은 것을 알 수 있다.
Boston.groupby(by='RAD')['CRIM'].mean()
RAD
1 0.04
2 0.08
3 0.10
4 0.39
5 0.69
6 0.15
7 0.15
8 0.37
24 12.76
Name: CRIM, dtype: float64
이번에는 1만 달러당 총재산세율(TAX)과 1인당 범죄율(CRIM)의 관계를 알아보기 위해 산점도를 그려보자.
plt.figure(figsize=(5,3))
plt.scatter(Boston['TAX'], Boston['CRIM'], s=8)
plt.xlabel('TAX')
plt.ylabel('CRIM')
plt.show()
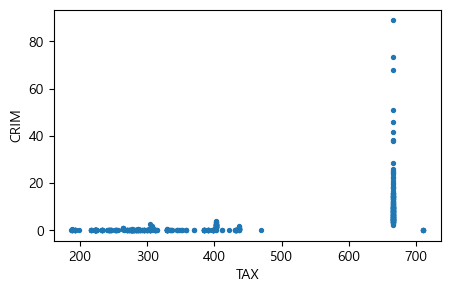
앞에서와 마찬가지로 각 TAX 별로 1인당 범죄율(CRIM)이 평균적으로 어느 정도인지를 계산해 볼 수 있다.
Boston.groupby(by='TAX')['CRIM'].mean()
TAX
187 0.02
188 0.15
193 0.07
198 0.02
216 0.07
...
432 0.15
437 0.59
469 0.01
666 12.76
711 0.15
Name: CRIM, Length: 66, dtype: float64
변수별 가장 큰 값 찾기
pandas에서 제공하는 nlargest() 메서드를 사용하면 데이터세트(Boston)에서 특정 열에 대해 가장 큰 값을 지닌 \(n\)개 행을 내림차순으로 반환시킬 수 있다. 이를 이용하여 보스턴 지역 타운 중 범죄율(CRIM), 재산세율(TAX), 학생/교사 비율(PTRATIO)이 가장 큰 5개 타운을 찾아보자.
Boston.nlargest(5, 'CRIM')
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 381 | 88.98 | 0.00 | 18.10 | 0 | 0.67 | 6.97 | 91.90 | 1.42 | 24 | 666 | 20.20 | 17.21 | 10.40 |
| 419 | 73.53 | 0.00 | 18.10 | 0 | 0.68 | 5.96 | 100.00 | 1.80 | 24 | 666 | 20.20 | 20.62 | 8.80 |
| 406 | 67.92 | 0.00 | 18.10 | 0 | 0.69 | 5.68 | 100.00 | 1.43 | 24 | 666 | 20.20 | 22.98 | 5.00 |
| 411 | 51.14 | 0.00 | 18.10 | 0 | 0.60 | 5.76 | 100.00 | 1.41 | 24 | 666 | 20.20 | 10.11 | 15.00 |
| 415 | 45.75 | 0.00 | 18.10 | 0 | 0.69 | 4.52 | 100.00 | 1.66 | 24 | 666 | 20.20 | 36.98 | 7.00 |
Boston.nlargest(5, 'TAX')
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 489 | 0.15 | 0.00 | 27.74 | 0 | 0.61 | 5.45 | 92.70 | 1.82 | 4 | 711 | 20.10 | 18.06 | 15.20 |
| 490 | 0.18 | 0.00 | 27.74 | 0 | 0.61 | 5.41 | 98.30 | 1.76 | 4 | 711 | 20.10 | 23.97 | 7.00 |
| 491 | 0.21 | 0.00 | 27.74 | 0 | 0.61 | 5.09 | 98.00 | 1.82 | 4 | 711 | 20.10 | 29.68 | 8.10 |
| 492 | 0.11 | 0.00 | 27.74 | 0 | 0.61 | 5.98 | 98.80 | 1.87 | 4 | 711 | 20.10 | 18.07 | 13.60 |
| 493 | 0.11 | 0.00 | 27.74 | 0 | 0.61 | 5.98 | 83.50 | 2.11 | 4 | 711 | 20.10 | 13.35 | 20.10 |
Boston.nlargest(5, 'PTRATIO')
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 355 | 0.04 | 80.00 | 1.91 | 0 | 0.41 | 5.66 | 21.90 | 10.59 | 4 | 334 | 22.00 | 8.05 | 18.20 |
| 356 | 0.11 | 80.00 | 1.91 | 0 | 0.41 | 5.94 | 19.50 | 10.59 | 4 | 334 | 22.00 | 5.57 | 20.60 |
| 128 | 0.26 | 0.00 | 21.89 | 0 | 0.62 | 5.69 | 96.00 | 1.79 | 4 | 437 | 21.20 | 17.19 | 16.20 |
| 129 | 0.33 | 0.00 | 21.89 | 0 | 0.62 | 6.43 | 98.80 | 1.81 | 4 | 437 | 21.20 | 15.39 | 18.00 |
| 130 | 0.88 | 0.00 | 21.89 | 0 | 0.62 | 5.64 | 94.70 | 1.98 | 4 | 437 | 21.20 | 18.34 | 14.30 |
특정 변수에 대한 통계량 구하기
가령 학생/교사 비율의 평균값을 알고 싶다. pandas의 mean() 메서드를 사용하면 데이터세트(Boston) 전체 열이나 특정 열의 평균값을 계산할 수 있다.
Boston['PTRATIO'].mean()
18.455533596837945
가령 보스턴 지역 타운 중 주택 가격(MEDV)이 가장 낮은 곳을 알고 싶다. pandas의 idxmin() 메서드를 사용하면 데이터세트(Boston) 전체 열이나 특정 열에서 최소값의 위치를 알아낼 수 있다. 아래 결과를 보면 399번 타운(즉 400번째 타운)의 주택 가격이 가장 낮은 것을 알 수 있다.
Boston['MEDV'].idxmin()
399
특정 개체에 대한 정보 구하기
loc[399,:]를 사용하면 데이터세트(Boston)의 행 레이블이 399인(즉, 399번째) 관측을 반환시킬 수 있다.
Boston.loc[399,:]
CRIM 38.35
ZN 0.00
INDUS 18.10
CHAS 0.00
NOX 0.69
RM 5.45
AGE 100.00
DIS 1.49
RAD 24.00
TAX 666.00
PTRATIO 20.20
LSTAT 30.59
MEDV 5.00
Name: 399, dtype: float64
iloc[]로 똑같은 결과를 얻기 위해서는 398번 관측을 지정해야 한다.(파이썬에서는 0번 관측이 1번째 관측이기 때문이다.) 즉, iloc[398,:]로 해야 399번째 관측을 얻을 수 있다.
Boston.iloc[398,:]
CRIM 38.35
ZN 0.00
INDUS 18.10
CHAS 0.00
NOX 0.69
RM 5.45
AGE 100.00
DIS 1.49
RAD 24.00
TAX 666.00
PTRATIO 20.20
LSTAT 30.59
MEDV 5.00
Name: 399, dtype: float64
전체 데이터세트에 대한 요약통계량(summary statistics)과 399번째 타운에 대한 관측값을 하나의 표로 만들어보자. 아래 표에서 맨 아래 행이 399번째 타운에 대한 관측값이고 나머지는 전체 데이터세트에 대한 요약통계량이다. 이런 표를 만듦으로써 399번째 타운의 각 변수 관측값이 전체 타운들과 비교하여 어느 정도 위치에 있는가를 가늠해 볼 수 있다.iloc와 loc에서 339번째를 가져오는 방법이 다름에 유의해야 한다.
a = Boston.describe() #Boston 데이터세트에 대한 요약통계량 행렬(데이터프레임)을 a라는 이름으로 지정
a.loc[399] = Boston.loc[399,:] #399번째 관측을 a 행렬에 339라는 레이블을 가진 행으로 추가함
a
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 |
| mean | 3.61 | 11.36 | 11.14 | 0.07 | 0.55 | 6.28 | 68.57 | 3.80 | 9.55 | 408.24 | 18.46 | 12.65 | 22.53 |
| std | 8.60 | 23.32 | 6.86 | 0.25 | 0.12 | 0.70 | 28.15 | 2.11 | 8.71 | 168.54 | 2.16 | 7.14 | 9.20 |
| min | 0.01 | 0.00 | 0.46 | 0.00 | 0.39 | 3.56 | 2.90 | 1.13 | 1.00 | 187.00 | 12.60 | 1.73 | 5.00 |
| 25% | 0.08 | 0.00 | 5.19 | 0.00 | 0.45 | 5.89 | 45.02 | 2.10 | 4.00 | 279.00 | 17.40 | 6.95 | 17.02 |
| 50% | 0.26 | 0.00 | 9.69 | 0.00 | 0.54 | 6.21 | 77.50 | 3.21 | 5.00 | 330.00 | 19.05 | 11.36 | 21.20 |
| 75% | 3.68 | 12.50 | 18.10 | 0.00 | 0.62 | 6.62 | 94.07 | 5.19 | 24.00 | 666.00 | 20.20 | 16.96 | 25.00 |
| max | 88.98 | 100.00 | 27.74 | 1.00 | 0.87 | 8.78 | 100.00 | 12.13 | 24.00 | 711.00 | 22.00 | 37.97 | 50.00 |
| 399 | 38.35 | 0.00 | 18.10 | 0.00 | 0.69 | 5.45 | 100.00 | 1.49 | 24.00 | 666.00 | 20.20 | 30.59 | 5.00 |
위 표를 보면, 399번째 타운은 다른 곳에 비해 CRIM(범죄율)이 분위수 75%를 크게 초과해 상당히 높은 편이며, ZN(25,000 제곱피트 초과 거주지역 비율)은 최소값에 해당하고, INDUS(비소매 상업지역 면적 비율)은 평균보다 높아 분위수 75% 수준이며, 찰스 강에 접하지 않고, NOX(질소산화물 농도)는 분위수 75% 이상이며, RM(주택당 평균 방 수)는 분위수 25 % 미만이고, AGE(1940년 이전 건축된 비율)은 최대값에 가까우며, DIS(직업센터와의 거리)는 최소값에 가깝고, RAD(순환 고속도로까지의 접근성)은 최대값에 해당하며, TAX(총재산세율) 및 PTRATIO(학생/교사 비율)은 분위수 75%에 해당하고, LSTAT(인구 중 하위 계층 비율)은 분위수 75% 이상이다.
특정 기준 만족 개체수 카운트하기
가령 보스톤에서 얼마나 많은 타운이 찰스 강에 접해 있는지를 알고 싶다. pandas의 value_counts() 메서드를 사용하면 데이터세트(Boston)의 특정 열에서 고유한 값의 개수가 몇 개인지를 카운트한 시리즈를 반환한다. 여기에서는 찰스 강을 접하는 경우, CHAS 변수의 값이 1로 정의돼있기 때문에 다음과 같이 대괄호를 사용하여 맨 마지막에 [1]을 기입해주면 된다. 아래 결과를 보면 35개 타운이 찰스 강과 접해 있는 것을 알 수 있다.
Boston['CHAS'].value_counts()[1]
35
가령 주택당 평균 방의 개수가 8개가 넘는 타운이 몇 개인지 알고 싶다. 또한 주택당 평균 방이 8개가 넘는 타운의 다른 변수들에 대한 요약통계량을 살펴보려면 다음과 같이 하면 된다.
len(Boston[Boston['RM']>8])
13
Boston[Boston['RM']>8].describe()
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 13.00 | 13.00 | 13.00 | 13.00 | 13.00 | 13.00 | 13.00 | 13.00 | 13.00 | 13.00 | 13.00 | 13.00 | 13.00 |
| mean | 0.72 | 13.62 | 7.08 | 0.15 | 0.54 | 8.35 | 71.54 | 3.43 | 7.46 | 325.08 | 16.36 | 4.31 | 44.20 |
| std | 0.90 | 26.30 | 5.39 | 0.38 | 0.09 | 0.25 | 24.61 | 1.88 | 5.33 | 110.97 | 2.41 | 1.37 | 8.09 |
| min | 0.02 | 0.00 | 2.68 | 0.00 | 0.42 | 8.03 | 8.40 | 1.80 | 2.00 | 224.00 | 13.00 | 2.47 | 21.90 |
| 25% | 0.33 | 0.00 | 3.97 | 0.00 | 0.50 | 8.25 | 70.40 | 2.29 | 5.00 | 264.00 | 14.70 | 3.32 | 41.70 |
| 50% | 0.52 | 0.00 | 6.20 | 0.00 | 0.51 | 8.30 | 78.30 | 2.89 | 7.00 | 307.00 | 17.40 | 4.14 | 48.30 |
| 75% | 0.58 | 20.00 | 6.20 | 0.00 | 0.60 | 8.40 | 86.50 | 3.65 | 8.00 | 307.00 | 17.40 | 5.12 | 50.00 |
| max | 3.47 | 95.00 | 19.58 | 1.00 | 0.72 | 8.78 | 93.90 | 8.91 | 24.00 | 666.00 | 20.20 | 7.44 | 50.00 |
주택당 평균 방이 8개가 넘는 타운의 특성을 전체 지역과 비교
Boston.describe()
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 | 506.00 |
| mean | 3.61 | 11.36 | 11.14 | 0.07 | 0.55 | 6.28 | 68.57 | 3.80 | 9.55 | 408.24 | 18.46 | 12.65 | 22.53 |
| std | 8.60 | 23.32 | 6.86 | 0.25 | 0.12 | 0.70 | 28.15 | 2.11 | 8.71 | 168.54 | 2.16 | 7.14 | 9.20 |
| min | 0.01 | 0.00 | 0.46 | 0.00 | 0.39 | 3.56 | 2.90 | 1.13 | 1.00 | 187.00 | 12.60 | 1.73 | 5.00 |
| 25% | 0.08 | 0.00 | 5.19 | 0.00 | 0.45 | 5.89 | 45.02 | 2.10 | 4.00 | 279.00 | 17.40 | 6.95 | 17.02 |
| 50% | 0.26 | 0.00 | 9.69 | 0.00 | 0.54 | 6.21 | 77.50 | 3.21 | 5.00 | 330.00 | 19.05 | 11.36 | 21.20 |
| 75% | 3.68 | 12.50 | 18.10 | 0.00 | 0.62 | 6.62 | 94.07 | 5.19 | 24.00 | 666.00 | 20.20 | 16.96 | 25.00 |
| max | 88.98 | 100.00 | 27.74 | 1.00 | 0.87 | 8.78 | 100.00 | 12.13 | 24.00 | 711.00 | 22.00 | 37.97 | 50.00 |
위 두 개의 요약통계량 표를 통해, 주택당 평균 방이 8개가 넘는 총 13개 타운(즉, 주택 규모가 큰 타운)의 특성을 Boston 전체 지역과 비교해보면, 주택 규모가 큰 동네가 평균적으로 CRIM(범죄율), INDUS(비소매 상업지역 면적 비율), NOX(질소산화물 농도), DIS(직업센터와의 거리), RAD(순환 고속도로까지의 접근성), TAX(총재산세율), PTRATIO(학생/교사 비율), LSTAT(인구 중 하위 계층 비율)이 더 낮은 편이며, 주택 가격의 중위값(MEDV)은 평균적으로 더 높다.
2.3 파이썬 프로그램 예제#
White Noise Process#
주어진 예제는 백색잡음(white noise) 프로세스(\(\epsilon_0, \epsilon_1, \ldots, \epsilon_T\))를 발생시킨 다음, 그것을 그림으로 그리는 것이다. 여기서 각 \(\epsilon_t\)는 상호독립적인 표준정규 변수다. 여러 가지 방법으로 이 작업을 수행할 수 있는데, 먼저 다음 명령문을 실행시켜보자.
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (5,3) # 그림 크기 전체적으로(globally) 조정
ϵ_values = np.random.randn(100)
plt.scatter(range(len(ϵ_values)), ϵ_values)
plt.show()
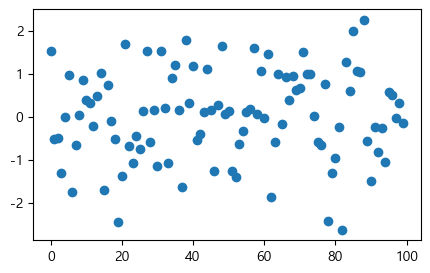
이 그림에서 가로축은 시점 \(t\)이고, 세로축은 \(\epsilon_t\)이다. 이제 위에서 실행시킨 프로그램을 각 부분으로 나누어 살펴보자.
Import
import numpy as np 후에는np.function 구문을 통해 numpy에서 제공하는 각종 함수(function)에 액세스할 수 있다. 아래 두 가지 예가 있다.
np.sqrt(4) # 4에 제곱근을 취함
2.0
np.log(4) # 4에 자연로그(natural logarithm)를 취함
1.3862943611198906
구문을 다음과 같이 사용할 수도 있다. 그러나 np라는 짧은 이름을 사용하는 것이 더 편리하고 표준적이다.
import numpy
numpy.sqrt(4)
2.0
파이썬 프로그램에는 일반적으로 여러 import 문장이 필요하다. 이는 의도적으로 핵심 언어(core language)를 작게 유지함으로써 배우고 유지하기 쉽게 만들기 위한 것이다. 파이썬으로 어떤 작업을 수행하려면 거의 항상 추가 함수들을 import 해와야 한다. 다음 코드를 다시 봐보자.
import numpy as np
np.sqrt(4)
2.0
그런데 NumPy의 sqrt(square root) 함수에 액세스하는 또 다른 방법이 있다.
from numpy import sqrt
sqrt(4)
2.0
위 두 개 방법 중 첫 번째 방법이 표준적이지만, 두 번째 방법을 사용해도 된다. 특히 만약 코드에서 sqrt 함수를 자주 사용하면 두 번째가 타이핑이 더 간단하다는 장점이 있다.
무작위 추출(Random Draws)
위의 백색잡음을 그리는 프로그램으로 돌아가서 import 문장 뒤의 나머지 부분, 즉 아래 코드를 봐보자. 여기에서 첫 번째 줄은 100개의 독립적인 표준정규 값을 생성하여 그것을 ϵ_values에 저장한다. 그 다음 두 줄은 ϵ_values에 대한 그림을 생성하기 위한 것이다.
ϵ_values = np.random.randn(100)
plt.scatter(range(len(ϵ_values)), ϵ_values)
plt.show()
위 코드와 내용은 동일하지만 접근이 약간 다른 방법들을 살펴보자. 아래 코딩은 원래 프로그램보다 덜 효율적으로서 다소 인위적이다. 하지만 몇 가지 중요한 파이썬 구문과 의미를 설명하는 데 도움이 된다. 즉 for 루프와 파이썬 리스트가 무엇인지를 보여주는 버전이다.
ts_length = 100
ϵ_values = [] # empty list(비어있는 리스트)
for i in range(ts_length):
e = np.random.randn()
ϵ_values.append(e)
plt.scatter(range(len(ϵ_values)), ϵ_values)
plt.show()
위 명령문을 차례대로 설명하면,
우선 첫 번째 줄
ts_length = 100은 원하는 시계열 길이를 100으로 설정한 것이다.다음 줄은 \( \epsilon_t \) 값을 생성하여 저장할
ϵ_values라는 이름의 비어있는 리스트(list)를 만든다(리스트는 대괄호를 사용함).그 다음 세 줄은 반복적으로 새로운 무작위숫자 \( \epsilon_t \)를 뽑아서
ϵ_values리스트 끝에 추가하는for루프이다.마지막 두 줄은 그림을 생성한다.
리스트에 값을 추가하기
리스트는 객체 모음을 그룹화하는 데 사용되는 파이썬의 기본 데이터 구조 중의 하나다. 예를 들어 다음을 시도해보자.
x = [10, 'foo', False]
print(x) # x를 프린트함
type(x) # x의 데이터 타입을 반환시킴
[10, 'foo', False]
list
x의 첫 번째 요소는 integer이고, 다음 요소는 string, 세 번째는 Boolean 값이다.
x
[10, 'foo', False]
리스트에 append() 메서드를 사용하면, 괄호안의 값을 해당 리스트에 추가한다.
x.append(2.5)
x
[10, 'foo', False, 2.5]
for 반복문
이제 위 프로그램의 for 루프 부분을 살펴 보자.
for i in range(ts_length):
e = np.random.randn()
ϵ_values.append(e)
파이썬은 위의 들여쓴(indented) 아래 두 줄–이를 코드 블록(code block)이라 부름–을 ts_length만큼, 즉 100번 실행시키는 코드이다.
원래 range() 함수는, 가령 range(3)이면, 0부터 2까지의 정수 수열을 의미한다. 따라서 range(ts_length)는 위에서 ts_length=100으로 지정했기 때문에 0부터 99까지 총 100개의 정수를 의미한다.
따라서 for i in range(ts_length):은 in 다음에 있는 수열(또는 리스트)의 모든 원소(이를 i라는 이름으로 지정했음)에 대해 들여쓴 부분(즉 코드 블록)을 반복적으로 시행하라는 의미다.
대부분의 다른 언어와 달리 파이썬은 들여쓰기(indentation)만으로 코드 블록의 범위를 인식한다. 우리 프로그램에서 ϵ_values.append(e) 줄 다음에는 들여쓰기가 없어져 파이썬에게 ϵ_values.append(e) 줄이 코드 블록의 아래쪽 경계임을 알려준다.
for 루프의 다른 예를 살펴보자.
animals = ['dog', 'cat', 'bird']
for animal in animals:
print("The plural of " + animal + " is " + animal + "s")
The plural of dog is dogs
The plural of cat is cats
The plural of bird is birds
이 예제는for 루프가 작동하는 방식을 명확히 하는 데 도움이 된다. 즉 다음과 같은 형태의 루프를 실행한다고 하자.
for variable_name in sequence:
<code block>
이 경우 파이썬 인터프리터는 sequence의 각 원소에 대해 variable_name이라는 이름을 해당 원소에 “바인딩”을 한 다음, 코드 블록을 실행한다. 아래에서 보게 되겠지만 sequence는 매우 일반적인 객체가 될 수 있다.
들여쓰기에 대한 설명
앞에서 for 루프에 대해 설명하면서 루프되는 코드 블록은 들여쓰기로 구분된다는 점을 설명했다. 실제로 파이썬에서 모든 코드 블록(즉, 루프, if 절, 함수 정의 등에서 발생하는 코드 블록)은 들여쓰기로 구분된다. 따라서 대부분의 다른 언어와 달리 파이썬 코드에서 공백(space)은 프로그램의 출력에 영향을 준다.
이것은 일단 익숙해지면 유용하게 사용할 수 있다. 깨끗하고 일관된 들여쓰기를 적용하여 가독성이 향상되고, 다른 언어에서 사용되는 대괄호 또는 end 구문이 필요 없기 때문이다. 반면에 제대로 작동하려면 약간의 주의가 필요하며, 다음 사항을 기억해야 한다.
코드 블록 시작 전의 줄은 항상 콜론으로 끝난다.
for i in range(10):if x > y:while x < 100:등등
코드 블록의 모든 줄은 동일한 들여쓰기를 가져야 한다.
파이썬 표준은 공백(space)이 4개다.
while 반복문
for 루프는 파이썬에서 가장 일반적인 루프 기법이다. 하지만 설명을 위해 위 프로그램을 수정하여 아래와 같이 while 루프를 대신 사용해보자.
ts_length = 100
ϵ_values = []
i = 0
while i < ts_length:
e = np.random.randn()
ϵ_values.append(e)
i = i + 1
plt.scatter(range(len(ϵ_values)), ϵ_values)
plt.show()
while 루프의 코드 블록은 앞에서와 마찬가지로 들여쓰기로만 구분된다. 한편, 위 코드에서 i=i+1 문장은 i+=1로 대체될 수 있다.
함수 만들기#
파이썬이 제공하는 함수가 아니라 사용자가 스스로 함수를 만들어 사용할 필요가 생기기도 한다. 이를 사용자 정의(user-defined) 함수라고 한다. 사용자 정의 함수를 한 번 만들어 놓으면, 필요할 때 이를 재사용할 수 있다. 다음은 매우 간단한 함수인 \( f(x)=2x+1 \)을 구현하는 파이썬 코드이다.
def f(x):
return 2*x + 1
위와 같이 \( f(x)=2x+1 \)을 정의했으므로 이를 호출(call)하여 의도대로 작동하는지 확인해보자.
f(1)
3
f(10)
21
이번에는 주어진 숫자의 절대값을 계산하는 함수를 만들어보자.(이러한 함수는 이미 내장돼있지만 연습을 위해 직접 작성해보자.)
def new_abs_function(x):
if x < 0:
abs_value = -x
else:
abs_value = x
return abs_value
위 구문을 검토해보자.
첫 줄의
def는 함수 정의를 시작하는 데 사용되는 파이썬 키워드이다.def new_abs_function(x):은 함수 이름을new_abs_function으로 정한 것으로서 이 함수에는 단일 파라미터x가 있음을 나타낸다.들여쓰기 된 코드는 함수 본체(function body)의 코드 블록이다.
return다음의abs_value가 호출 시 반환되는 객체다.
위 함수가 작동하는지 확인해보자.
print(new_abs_function(3))
print(new_abs_function(-3))
3
3
함수는 여러 개의 return 문장을 가질 수 있는데, 함수의 실행은 첫 번째 리턴에 도달하면 종료된다.
def f(x):
if x < 0:
return 'negative'
return 'nonnegative'
f(1)
'nonnegative'
한 줄 함수 : lambda
lambda 키워드는 간단한 함수를 한 줄만으로 만드는 데 사용된다. 예를 들어, 다음 두 개의 정의는 완전히 동일하다.
def f(x):
return x**3
f = lambda x: x**3
왜 lambda가 유용한지 알아보기 위해 \( \int_0 ^ 2 x ^ 3 dx \)를 계산한다고 가정해보자. SciPy 라이브러리에는 이 적분 계산을 수행하는 quad라는 함수가 있다. quad 함수의 구문은 quad(f,a,b)이다. 여기서 f는 함수이고 a와 b는 숫자다. 따라서 함수 f를 한 줄로 표현할 수 있어야 quad 함수를 제대로 사용할 수 있다. 즉, 다음과 같이 quad(f,a,b)의 f 자리에 lambda x: x**3처럼 \( f(x)=x^3 \) 함수를 한 줄로 만들어 입력하면 된다.
from scipy.integrate import quad
quad(lambda x: x**3, 0, 2)
(4.0, 4.440892098500626e-14)
키워드 인수 vs. 위치 인수
가령 함수 plt.plot(x, 'b-', label = "white noise")을 생각해보자. 이 함수에서 괄호속 마지막 인수는 name = argument의 형태이며, 이런 인수를 키워드 인수(keyword argument) 또는 명명된 인수(named argument)라고 한다. 즉 “파라미터 이름 = 인수” 형태의 인수가 키워드 인수다. 이 예에서는 label이 키워드로서 함수 정의에서 사용된 파라미터 이름이다. 키워드 인수가 아닌 인수는 순서에 따라 의미가 결정되므로 위치 인수(positional argument)라고 한다.
키워드 인수는 함수에 인수가 많은 경우 올바른 순서를 기억하기 어렵기 때문에 사용된다. 사용자 정의 함수에서도 키워드 인수를 채택할 수 있다. 다음이 그 예다.
def f(x, a=1, b=1): # 여기에서 a=1, b=1이 키워드 인수다.
return a + b * x
f(2)
3
여기에서 알 수 있듯이 f 정의에서 제공한 키워드 인수 값이 기본값이 된다. 키워드 인수 값을 다음과 같이 수정할 수도 있다.
f(2, a=4, b=5)
14
2.4 파이썬 데이터 기본 유형#
Boolean values#
간단한 데이터 유형 중 하나는 부울 값(Boolean value)으로서 True 또는 False 둘 중 하나를 취할 수 있다. 아래 x가 부을 값의 예다.
x = True
x
True
type() 함수를 사용하여 객체의 유형을 확인해보자.
type(x)
bool
아래 코드는 = 오른쪽에 있는 표현식을 평가하여 이를 y에 부여한다.(즉, y는 부울 값이다.)
y = 100 < 10
y
False
type(y)
bool
산술식에서 True는 1로, False는 0으로 변환된다. 이를 부울 산술(Boolean arithmetic)이라고 하며 프로그래밍에서 종종 유용하게 사용된다. 아래는 부울 산술의 몇 가지 예다.
x + y
1
x * y
0
True + True
2
bools = [True, True, False, True] # 부울 값 List
sum(bools)
3
리스트#
파이썬에는 데이터 모음을 담기 위한 몇 가지 기본 유형이 있다. 리스트, 튜플, 딕셔너리, 세트 등이다. 이중 리스트(list)는 앞에서도 몇 차례 설명했듯이 대괄호 [ ]로 감싸주며, 각 원소는 쉼표로 구분해준다.
list1 = [1, 2, 3, 4, 5]
list2 = ['a', 'b', 'c', 'd', 'e']
list3 = [[1, 3], [2, 4]] # 리스트의 원소가 두 개의 리스트로 돼 있는 경우
print(list3)
type(list3)
[[1, 3], [2, 4]]
list
튜플#
파이썬의 또 다른 데이터 컨테이너 유형은 “변경불가능(immutable)” 리스트인 튜플(tuple)이다. 튜플은 소괄호를 사용하거나 괄호 없이 사용한다.
x = ('a', 'b') # 대괄호가 아니라 소괄호
x = 'a', 'b' # 또는 괄호 없음 --- 의미는 동일함
x
('a', 'b')
type(x)
tuple
파이썬에서 어떤 객체가 일단 생성되고 나서 변경할 수 없는 경우 변경불가능(immutable)이라고 부른다. 반대로 객체가 생성 후에도 변경할 수 있는 경우 변경가능(mutable)이라고 한다. 다음 예에서 보듯이 리스트는 변경가능하다
x = [1, 2]
x[0] = 10
x
[10, 2]
그러나 튜플은 변경이 불가능하며, 아래와 같이 변경을 시도하면 에러 메시지가 나온다.
x = (1, 2)
x[0] = 10
슬라이스 표기법(Slice Notation)
리스트 또는 튜플의 여러 요소에 액세스하려면 파이썬의 슬라이스 표기법을 사용할 수 있다.
a = [2, 4, 6, 8]
a[1:]
[4, 6, 8]
a[1:3]
[4, 6]
일반적인 규칙은 a[m:n]은 a[m]에서 시작하는 \(n-m\)개의 요소를 반환한다.(음수도 허용된다.)
a[-2:] # 끝에서 두 번째부터 끝까지(즉 마지막 두 요소)
[6, 8]
딕셔너리#
딕셔너리(dictionary)는 리스트와 매우 비슷하지만, 각 원소에 번호가 지정되는 대신, 어떤 이름(name)을 직접 지정한다는 점이 다르다. 딕셔너리는 중괄호 { }로 감싸주며, 입력하는 방법은 다음과 같다.
d = {'name': 'Frodo', 'age': 33}
type(d)
dict
d['age']
33
여기에서 name과 age를 키(key)라고 하고, 키가 매핑되는 객체(Frodo 및 33)를 값(value)이라고 한다.
세트#
세트(set)는 수학에서 사용하는 집합의 개념이다. 원소들은 중복되지 않는 것으로 받아들이며, 원소들의 순서도 지정되지 않는 데이터 모음이다. 세트 관련 메서드를 사용해 일반적인 집합 이론 연산이 가능하다. 세트 역시 중괄호 { }로 감싸준다.
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket)
type(basket)
{'apple', 'pear', 'orange', 'banana'}
set
s1 = {'a', 'b', 'c'}
s2 = {'b', 'c'}
s2.issubset(s1) # s2가 s1의 부분집합(subset)인지 여부
True
s1.intersection(s2) # s1과 s2의 교집합(intersection)
{'b', 'c'}
set() 함수는 어떤 시퀀스를 세트로 만든다.
s3 = set(('foo', 'bar', 'foo'))
s3
{'bar', 'foo'}