10장 변수선택 및 정규화#
자료 출처: ISLP (An Introduction to Statistical Learning with Applications in Python) 및 gperaza/ISLR-Python-Labs
10.1 개요#
선형 모델을 좀 더 복잡한 비선형(non-linear) 모델로 확장시킴으로써 피팅 성과를 높일 수 있다. 그러나 선형 모델은 추론 측면에서 뚜렷한 이점이 있으며, 실제 문제에서 비선형 방법과 비교하여 놀랍도록 경쟁적인 경우가 많다. 따라서 비선형의 세계로 가기 전에 변수선택이나 정규화를 통해 선형 모델의 추정 성과를 개선할 수 있는 몇 가지 방법에 대해 살펴보자. 추정 성과를 개선한다는 것은 예측의 정확도와 모델의 해석력(model interpretability)을 높인다는 것이다.
예측 정확도: 추정 계수를 제한하거나 축소함으로써 편향을 일부 희생해서라도 분산을 줄일 필요가 있다. 이를 통해 테스트 세트에 대한 모델의 정확도를 크게 향상시킬 수 있다.
모델 해석력: 관련 없는 변수를 모델에 포함시키면 모델이 불필요하게 복잡해진다. 이러한 변수를 제거하면, 즉 해당 계수 추정치를 0으로 설정하게 되면 해석이 보다 쉬운 모델을 얻을 수 있다.
이 장에서는 선형 모델의 추정 성과를 개선하는 두 가지 방법에 대해 살펴본다.
첫 번째 방법은 예측변수(독립변수)의 부분집합 선택(Subset Selection)이다. 이것은 주어진 \(p\)개의 예측변수를 모두 다 사용하는 것이 아니라 그중 반응변수와 가장 밀접한 관련이 있다고 생각되는 변수들을 식별해낸 다음, 그것으로 모델을 피팅하는 방법이다. 부분집합 선택 방법 중 여기에서는 최량 부분집합 선택(best subset selection)과 단계적 모델 선택(stepwise model selection)에 대해 살펴본다.
두 번째 방법은 축소(shrinkage)이다. 이 접근 방식은 일단 \(p\)개 예측변수를 모두 포함하는 모델을 피팅한다. 그러나 추정된 계수는 최소제곱 추정치에 비해 0을 향해 축소된다. 이 축소를 정규화(regularization)라고도 하는데, 이렇게 함으로써 추정 계수의 분산을 줄이는 효과가 있다. 수행되는 축소 방식에 따라 일부 계수는 정확히 0으로 추정될 수 있기 때문에 축소를 통해 변수선택을 수행할 수도 있다. 축소 접근법 중 여기에서는 Ridge 회귀와 Lasso 기법에 대해 소개한다.
10.2 최량 부분집합 선택#
최량 부분집합 선택은 다음과 같이 진행된다. 우선 주어진 \(p\)개 예측변수의 모든 가능한 조합에 대해 각각 OLS 피팅을 수행한다. 즉, 예측변수가 하나만 있는 모든 \(p\)개 모델, 두 개의 예측변수만을 포함하는 \({p \choose 2}= p (p-1) / 2\)개의 모델 등, 이런 식으로 예측변수의 개수를 하나씩 늘려가면서 모든 조합에 대해 피팅을 수행한다.
그런 다음, 동일한 수의 예측변수를 가진 모델들(예측변수의 모든 조합)에 대해 RSS 또는 \(R^2\)를 사용하여 서로 비교한다. 그런 식으로 각 개수의 예측변수에 대해 최량의 모델을 선택한 다음, 그것들끼리 다시 비교하여 최상의 모델을 찾는다. 예측변수 개수가 다른 모델을 비교함에 있어서는 AIC, BIC, Adj \(R^2\) 등의 정보기준(information criteria)(아래 10.4.1절 참조)을 사용하거나 아니면 훈련 세트 일부를 테스트 세트로 사용하여 모델을 비교하는 소위 교차검증(cross-validation)(부록 참조)을 통해 최상의 모델을 선택한다.
예측변수가 \(p\)개일 때, 최량 부분집합 선택은 \(2^p\)개의 모든 가능한 모델 중에서 최상의 모델을 선택하는 방식이다. 한 가지 문제는 \(p\)가 커짐에 따라 실행에 상당한 시간이 소요된다는 점이다. 예측변수가 20개만 되더라도 모든 가능한 모델의 개수는 \(2^{20}\), 즉 1,048,576개에 이른다.
우선 이해를 돕기 위해 예측변수가 3개인 경우 최량 부분집합 선택 알고리즘을 생각해보자.
Best subset selection 알고리즘 (\(p=3\))
\(\mathcal M_0\)는 예측변수를 하나도 포함하지 않는 영(null) 모델로서 관측값의 표본평균을 나타낸다.
(1) 세 개의 예측변수 각각에 대해 각각 단순 선형 회귀(즉 예측변수 1개) 모델을 피팅한다. 이 세 개의 모델 중에서 최상의 것을 선택하고, 이를 \(\mathcal M_1\)이라고 부른다. 여기서 최상의 모델은 RSS가 가장 작은(또는 이와 동등하게 \(R^2\)가 가장 큰) 것으로 정의된다.
(2) 이번에는 예측변수 2개를 사용한 다중 선형 회귀 모델을 피팅한다. 예측변수가 2개인 모델은 세 가지가 있으며, 이 중 최상의 것을 \(\mathcal M_2\)라고 부른다.
(3) 이번에는 예측변수 3개를 모두 사용한 모델을 피팅한다. 예측변수가 3개인 경우는 하나밖에 없기 때문에 자신이 최상의 것이 되고,이를 \(\mathcal M_3\)라고 부른다.정보기준 \(C_p\)(AIC), BIC, adjusted \(R^2\)를 사용하여 \(\mathcal M_0,\mathcal M_1,\mathcal M_2,\mathcal M_3\) 중에서 최적의 모델을 선택한다.(결국 총 \(2^3=8\)개 모델 중에서 가장 우수한 것을 선택하는 것임.)

다음은 예측변수가 \(p\)개일 때, 최량 부분집합 선택 알고리즘을 정리한 것이다.
Best subset selection 알고리즘
\(\mathcal M_0\)는 예측변수를 하나도 포함하지 않는 영(null) 모델로서 관측값의 표본평균을 나타낸다.
\(k = 1, 2,. . ., p:\)
(1) 정확히 \(k\)개의 예측변수를 포함하는 모든 \(\binom{p}{k}\)개의 모델을 피팅한다.
(2) 이 \(\binom{p}{k}\)개의 모델 중에서 최상의 것을 선택하고, 이를 \(\mathcal M_k\)라고 부른다. 여기서 최상의 모델은 RSS가 가장 작은(또는 이와 동등하게 \(R^2\)가 가장 큰) 것으로 정의된다.정보기준 \(C_p\)(AIC), BIC, adjusted \(R^2\)를 사용하여 \(\mathcal M_0,...,\mathcal M_p\) 중에서 단일의 최적 모델을 선택한다.
Credit 데이터세트 적용 예#
Credit 데이터세트는 개인들의 신용카드 사용액과 관련된 데이터이다.(여기에서는 인터넷에서 데이터 파일을 불러들이는데 이것은 ISLP에서 제공하는 Credit.csv 파일과 변수 구성이 약간 다르다.)
Credit 데이터세트에는 Balance(각 개인의 월평균 신용카드 사용액)를 비롯해 Income(소득, 단위: 천달러), Limit(신용 한도), Rating(신용 등급), Cards(신용카드 개수), Age(나이), Education(교육 년수), Gender(성별), Student(학생 여부), Married(결혼 여부), Ethnicity(백인, 아프리카계 미국인, 아시아인) 등의 변수가 있다.
%matplotlib inline
import numpy as np
import pandas as pd
import statsmodels.api as sm
from matplotlib import pyplot as plt
from operator import itemgetter
from itertools import combinations
from sklearn.model_selection import KFold
import warnings
warnings.filterwarnings('ignore')
url = 'https://raw.githubusercontent.com/JWarmenhoven/ISLR-python/master/Notebooks/\
Data/Credit.csv'
Credit = pd.read_csv(url, usecols=list(range(1,12)))
Credit
| Income | Limit | Rating | Cards | Age | Education | Gender | Student | Married | Ethnicity | Balance | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.891 | 3606 | 283 | 2 | 34 | 11 | Male | No | Yes | Caucasian | 333 |
| 1 | 106.025 | 6645 | 483 | 3 | 82 | 15 | Female | Yes | Yes | Asian | 903 |
| 2 | 104.593 | 7075 | 514 | 4 | 71 | 11 | Male | No | No | Asian | 580 |
| 3 | 148.924 | 9504 | 681 | 3 | 36 | 11 | Female | No | No | Asian | 964 |
| 4 | 55.882 | 4897 | 357 | 2 | 68 | 16 | Male | No | Yes | Caucasian | 331 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 395 | 12.096 | 4100 | 307 | 3 | 32 | 13 | Male | No | Yes | Caucasian | 560 |
| 396 | 13.364 | 3838 | 296 | 5 | 65 | 17 | Male | No | No | African American | 480 |
| 397 | 57.872 | 4171 | 321 | 5 | 67 | 12 | Female | No | Yes | Caucasian | 138 |
| 398 | 37.728 | 2525 | 192 | 1 | 44 | 13 | Male | No | Yes | Caucasian | 0 |
| 399 | 18.701 | 5524 | 415 | 5 | 64 | 7 | Female | No | No | Asian | 966 |
400 rows × 11 columns
Gender, Student, Married, Ethnicity 등 4개의 범주형 변수에 대해 pd.get_dummies() 함수를 이용해 더미변수를 만든다. 그런 다음, 기존의 범주형 변수를 없애고 새로 만든 더미변수를 넣어 df라는 새로운 데이터프레임을 만든다.
dummies = pd.get_dummies(Credit[['Gender', 'Student', 'Married', 'Ethnicity']])
dummies.head()
| Gender_ Male | Gender_Female | Student_No | Student_Yes | Married_No | Married_Yes | Ethnicity_African American | Ethnicity_Asian | Ethnicity_Caucasian | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | True | False | True | False | False | True | False | False | True |
| 1 | False | True | False | True | False | True | False | True | False |
| 2 | True | False | True | False | True | False | False | True | False |
| 3 | False | True | True | False | True | False | False | True | False |
| 4 | True | False | True | False | False | True | False | False | True |
df = Credit.drop(['Gender', 'Student', 'Married', 'Ethnicity'], axis=1)
df = pd.concat([df, dummies[['Gender_Female', 'Student_Yes', 'Married_Yes',
'Ethnicity_Asian', 'Ethnicity_Caucasian']]],axis=1)
df.head()
| Income | Limit | Rating | Cards | Age | Education | Balance | Gender_Female | Student_Yes | Married_Yes | Ethnicity_Asian | Ethnicity_Caucasian | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.891 | 3606 | 283 | 2 | 34 | 11 | 333 | False | False | True | False | True |
| 1 | 106.025 | 6645 | 483 | 3 | 82 | 15 | 903 | True | True | True | True | False |
| 2 | 104.593 | 7075 | 514 | 4 | 71 | 11 | 580 | False | False | False | True | False |
| 3 | 148.924 | 9504 | 681 | 3 | 36 | 11 | 964 | True | False | False | True | False |
| 4 | 55.882 | 4897 | 357 | 2 | 68 | 16 | 331 | False | False | True | False | True |
앞에서도 언급했듯이 최량 부분집합 선택 기법은 계산 비용이 크기 때문에 잘 사용되지 않는다.(예측변수가 \(p\)개인 경우 \(2^p\)개의 모델을 비교해야 함.) 그래서 이를 수행하기 위한 내장(built-in) sklearn 모듈이 없다. 여기에서는 파이썬으로 함수를 만들어보는 학습 차원에서 직접 함수를 만들어 최량 부분집합 선택을 수행해보자.
Best subset selection 함수 만들기#
아래 best_subsets() 함수는 각 선형 회귀 모델 크기별로 RSS가 가장 낮은 모델을 찾는 함수를 만든 것이다.
def best_subsets(dataframe, predictors, response, max_features):
"""
주어진 데이터프레임에서 반응변수를 예측변수의 부분집합에 회귀시킨다.
예측변수 개수가 동일한 모델끼리 비교하여 RSS가 가장 낮은 모델을
해당 예측변수 개수에 대한 '최량' 모델로 선택한다.
PARAMETERS
----------
dataframe : 반응 및 예측변수가 들어있는 pandas 데이터프레임
predictors : 예측변수로 사용되는 데이터프레임의 열 이름 리스트
response : target으로 사용되는 데이터프레임의 열 이름 리스트
RETURNS
-------
최량 모델 리스트(예측변수 개수별로 하나씩)
"""
def process_linear_model(features):
"""
선형 회귀 모델을 구축
"""
X = sm.add_constant(dataframe[features].astype(float)) # bool → float 변환
y = dataframe[response]
model = sm.OLS(y,X).fit()
RSS = model.ssr
return (model, RSS)
def get_best_kth_model(k):
"""
k-예측변수가 있는 모든 모델에서 RSS가 가장 낮은 모델을 반환
"""
results = []
for combo in combinations(predictors, k):
results.append(process_linear_model(list(combo)))
return sorted(results, key=itemgetter(1)).pop(0)[0]
models =[]
for k in range(1,max_features+1):
models.append(get_best_kth_model(k))
return models
Credit 데이터세트 적용#
위에서 만든 best_subsets() 함수를 Credit 데이터에 대해 실행한다. 반응변수(종속변수)는 Balance이다. 우리의 목표는 Balance를 결정하는 최적의 변수들을 찾는 것이다.
predictors = list(df.columns)
predictors.remove('Balance')
models = best_subsets(df, predictors, ['Balance'], max_features=11)
각 모델 크기별로 최량의 변수 세트를 출력시킨다.
for model_i in models:
print(model_i.model.exog_names)
['const', 'Rating']
['const', 'Income', 'Rating']
['const', 'Income', 'Rating', 'Student_Yes']
['const', 'Income', 'Limit', 'Cards', 'Student_Yes']
['const', 'Income', 'Limit', 'Rating', 'Cards', 'Student_Yes']
['const', 'Income', 'Limit', 'Rating', 'Cards', 'Age', 'Student_Yes']
['const', 'Income', 'Limit', 'Rating', 'Cards', 'Age', 'Gender_Female', 'Student_Yes']
['const', 'Income', 'Limit', 'Rating', 'Cards', 'Age', 'Gender_Female', 'Student_Yes', 'Ethnicity_Asian']
['const', 'Income', 'Limit', 'Rating', 'Cards', 'Age', 'Gender_Female', 'Student_Yes', 'Married_Yes', 'Ethnicity_Asian']
['const', 'Income', 'Limit', 'Rating', 'Cards', 'Age', 'Gender_Female', 'Student_Yes', 'Married_Yes', 'Ethnicity_Asian', 'Ethnicity_Caucasian']
['const', 'Income', 'Limit', 'Rating', 'Cards', 'Age', 'Education', 'Gender_Female', 'Student_Yes', 'Married_Yes', 'Ethnicity_Asian', 'Ethnicity_Caucasian']
각 모델 크기별로 최량 모델의 \(R^2\) 값도 볼 수 있다.
for model_i in models:
print(model_i.rsquared)
0.7458484180585037
0.8751179476994355
0.94987877963262
0.9535800027954133
0.9541605970612348
0.9546878863974592
0.9548166616899534
0.9548879566476849
0.9549635868719017
0.9550468424377629
0.9551015633651758
위 결과를 보면, 모델에 하나의 예측변수만 있는 경우가 \(R^2=0.745\)로 가장 낮고, 모든 변수가 포함된 경우에는 \(R^2\)가 0.955로 높아진다. 예측변수 개수가 늘어남에 따라 \(R^2\)가 단조(monotonic) 증가하는 것을 알 수 있다. 이것을 그림으로 그린 것이 아래 그림 10.1에 나와 있다. 이는 결국 \(R^2\) 또는 RSS로는 최적의 모델(즉, 최적의 예측변수 조합)을 찾는 것이 불가능하다는 것을 의미한다. 그래서 \(R^2\)나 RSS 대신 앞에서 언급한 대로 정보기준이나 교차검증을 사용하는 것이다.(아래 10.4 최적 모델 선택 설명 참조)
그림 10.1. Credit 데이터세트의 10개 예측변수의 각 가능한 부분집합 모델에 대해 RSS 및 \(R^2\)가 표시돼 있다. 빨간색 점으로 연결된 선은 각 예측변수 개수별로 최량의 모델을 표시한 것이다. 데이터세트의 예측변수는 10개이지만 범주형 변수 중 하나인 Ethnicity(백인, 아프리카계 미국인, 아시아인)가 3개의 범주를 갖고 있어 두 개의 더미변수가 생성되기 때문에 가로축의 범위가 1에서 11까지(즉 11개 변수)로 돼있다.
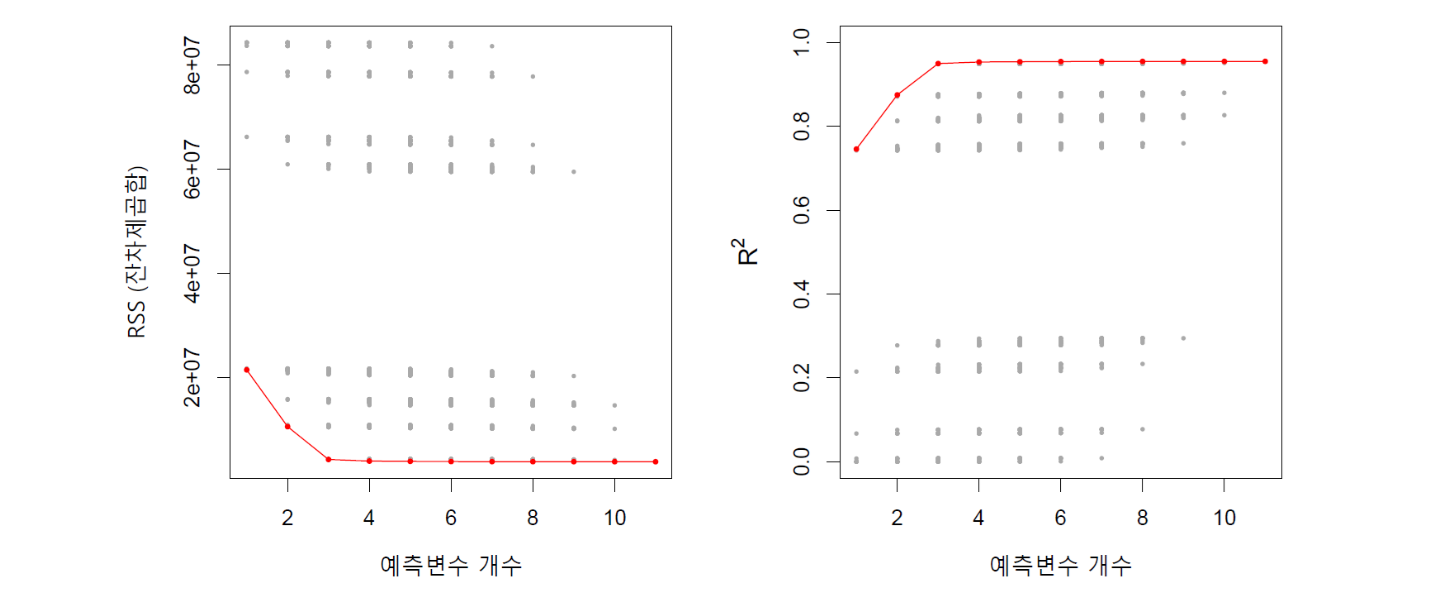
그림 출처: ISLP, FIGURE 6.1
최적 모델 선택#
예측변수 개수별로 구한 가장 우수한 모델 중에서 최고의 모델을 찾는 작업이 남아 있다. 정보기준 접근에 입각하여 adjusted \(R^2\), AIC(이것은 \(C_p\)와 서로 비례함), BIC를 그림으로 그려 보자. adjusted \(R^2\)의 경우에는 값이 가장 높은 모델이 가장 우수한 반면, AIC 및 BIC의 경우에는 값이 가장 낮은 모델이 가장 우수하다.
aics = [model.aic for model in models]
bics = [model.bic for model in models]
r_adj = [model.rsquared_adj for model in models]
plt.rcParams.update({'font.size': 13})
# 최적 모델 선택
min_aic_index, min_aic = min(enumerate(aics), key=itemgetter(1))
min_bic_index, min_bic = min(enumerate(bics), key=itemgetter(1))
max_radj_index, max_radj = max(enumerate(r_adj), key=itemgetter(1))
num_predictors = np.linspace(1, len(models), len(models))
# 그림 그리기
fig,(ax1, ax2) = plt.subplots(1, 2, figsize=(16,5))
ax1.plot(num_predictors, aics, 'r', marker='o', label='AIC')
ax1.plot(num_predictors, bics, 'b', marker='o', label='BIC')
ax1.plot(min_aic_index+1, min_aic, 'gx', markersize=20, markeredgewidth=1)
ax1.plot(min_bic_index+1, min_bic, 'gx', markersize=20, markeredgewidth=1)
ax1.set_xlabel('Number of Predictors')
ax1.legend(loc='best')
ax2.plot(num_predictors, r_adj,'k', marker='o')
ax2.plot(max_radj_index+1, max_radj, 'gx', markersize=20, markeredgewidth=1)
ax2.set_xlabel('Number of Predictors')
ax2.set_ylabel('Adjusted $R^2$')
plt.show()
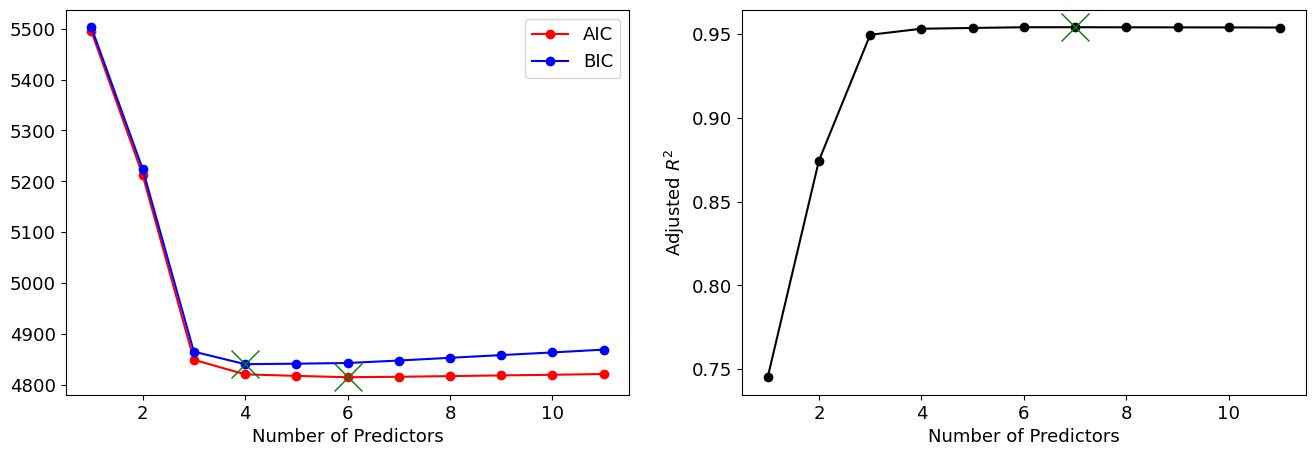
위 결과를 보면, 무엇을 기준으로 하든 예측변수가 4개 이상은 필요하다는 것을 알 수 있다. 가령 BIC를 기준으로 할 경우, 예측변수가 4개인 경우가 가장 좋은 모델이다. 이 모델의 추정 계수는 다음과 같다.
models[3].params
const -499.727212
Income -7.839229
Limit 0.266644
Cards 23.175379
Student_Yes 429.606420
dtype: float64
10.3 단계적 선택#
최량 부분집합 선택은 \(p\)가 크면 계산 비용이 너무 커서 적용하기 곤란하다. 또한 최량 부분집합 선택은 \(p\)가 클 때 계수 추정치의 높은 분산 및 과적합 문제로 이어질 수 있다.
이 때문에 훨씬 더 제한된 모델 세트를 탐색하는 단계적 선택(stepwise selection) 방법이 최량 부분집합 선택에 대한 매력적인 대안이다. 최량 부분집합은 \(p\)개 예측변수의 모든 부분집합에 대해 총 \(2^p\)개의 모델을 고려하는 반면, 단계적 선택은 훨씬 더 작은 모델 집합을 고려한다. 단계적 선택에는 전진(forward) 방식과 후진(backward) 방식이 있다.
전진 단계적 선택#
전진 단계적 선택은 예측변수가 없는 영(null) 모델에서 시작하여 모든 예측변수가 들어있는 모델에 이를 때까지 한 번에 하나씩 예측변수를 모델에 추가시킨다. 각 단계에서 피팅을 가장 크게 개선시키는 변수를 모델에 추가시키는 방식이다. 그런 다음, 정보기준 또는 교차검증을 사용하여 서로 다른 개수의 예측변수를 가진 모델들을 비교하여 최적의 모델을 선택한다.
우선 이해를 돕기 위해 예측변수가 3개인 경우에 대해 전진 단계적 선택 알고리즘을 생각해보자.
Forward stepwise selection 알고리즘 (\(p=3\))
\(\mathcal M_0\)는 예측변수를 포함하지 않는 영(null) 모델을 나타낸다.
(1) 예측변수가 하나도 없는 \(\mathcal M_0\) 모델에 예측변수를 추가적으로 1개 늘리는 세 가지 모델(즉 세 개의 단순 선형 회귀 모델)을 피팅한다. 이 세 가지 모델 중에서 최상의 것을 선택하고, 이를 \(\mathcal M_1\)이라고 부른다. 여기서 최상의 모델은 RSS가 가장 작거나 \(R^2\)가 가장 큰 것으로 정의된다.
(2) 이번에는 \(\mathcal M_1\)에 예측변수를 추가적으로 한 개 늘리는 두 가지 모델(즉 예측변수가 2개인 두 가지 다중 선형 회귀 모델)을 피팅한다. 이 두 가지 모델 중에서 최상의 것을 선택하고, 이를 \(\mathcal M_2\)라고 부른다.
(3) 이번에는 \(\mathcal M_2\)에 예측변수를 추가적으로 한 개 늘리는 모델(즉 예측변수 3개를 모두 사용한 다중 선형 회귀 모델)을 피팅한다. 예측변수가 3개인 경우는 모델이 하나밖에 없기 때문에 이것이 최상의 것이 되고,이를 \(\mathcal M_3\)라고 부른다.정보기준 \(C_p\)(AIC), BIC, adjusted \(R^2\)를 사용하여 \(\mathcal M_0,\mathcal M_1,\mathcal M_2,\mathcal M_3\) 중에서 단일의 최적 모델을 선택한다.(결국 총 7개 모델 중에서 가장 우수한 것을 선택하는 것임.)

다음은 예측변수가 \(p\)개일 때, 전진 단계적 선택 알고리즘을 정리한 것이다.
Forward stepwise selection 알고리즘
\(\mathcal M_0\)는 예측변수를 포함하지 않는 영(null) 모델을 나타낸다.
\(k = 0, 1,. . ., p-1:\)
(1) \(\mathcal M_k\)에서 예측변수를 추가적으로 하나 늘리는 모든 \(p − k\)개의 모델을 고려한다.
(2) 이 \(p - k\)개의 모델 중에서 최상의 것을 선택하고, 이를 \(\mathcal M_{k+1}\)이라고 부른다. 여기서 최상의 모델은 RSS가 가장 작거나 \(R^2\)가 가장 큰 것으로 정의된다.정보기준 \(C_p\)(AIC), BIC, adjusted \(R^2\)를 사용하여 \(\mathcal M_0,...,\mathcal M_p\) 중에서 단일의 최적 모델을 선택한다.
\(2^p\)개의 모델을 피팅해야 하는 최량 부분집합 선택과 달리, 전진 단계적 선택은 \(k = 0, . . . , p − 1\)에 대해 각각 \(p − k\)개의 모델을 피팅하게 된다. 이것은 영(null) 모델까지 포함해서 총 \(1 + \sum_{k = 0}^{p−1}{(p−k)} = 1 + p (p + 1) / 2\)개이다.
이것은 상당한 차이이다. 가령 \(p = 20\)일 때 최량 부분집합 선택은 1,048,576개의 모델을 피팅해야 하는 반면, 전진 단계적 선택은 211개의 모델만 피팅하면 된다.
전진 단계적 선택 함수 만들기
최량 부분집합 선택과 마찬가지로 전진(forward) 및 후진(backward) 단계적 선택을 수행하기 위해서는 함수를 직접 만들어야 한다.
def forward_step_select(df, predictors, response, max_features=len(predictors)):
"""
전진 단계적 알고리즘을 사용하여 반응을 예측변수에 회귀시킨다. 최소 RSS를 기준으로 예측변수이 추가된다.
PARAMETERS
-----------
df : 반응 및 예측변수가 들어있는 pandas 데이터프레임
predictors : 예측변수로 사용되는 모든 예측변수 리스트
response : 데이터프레임에서 예측변수에 회귀시키는 변수 리스트
max_features : 예측변수 리스트에서 사용할 최대 예측변수 개수
RETURNS
--------
max_features까지 예측변수 개수가 증가하는 모델 리스트
"""
def process_linear_model(features):
"""
선형 회귀 모델을 구축
"""
X = sm.add_constant(df[features].astype(float)) # bool → float 변환
y = df[response]
model = sm.OLS(y,X).fit()
RSS = model.ssr
return (model, RSS)
def update_model(best_features, remaining_features):
"""
새 모델의 RSS를 계산하고 RSS가 가장 낮은 모델을 반환
"""
results = []
for feature in remaining_features:
results.append(process_linear_model(best_features + [feature]))
# RSS 가장 낮은 모델을 선택
new_model = sorted(results, key= itemgetter(1)).pop(0)[0]
new_features = list(new_model.params.index)[1:]
return new_features, new_model
# models, model features를 위한 empty list를 만듦
models = []
best_features = []
remaining_features = predictors
while remaining_features and len(best_features) < max_features:
new_features, new_model = update_model(best_features, remaining_features)
best_features = new_features
remaining_features = [feature for feature in predictors
if feature not in best_features]
models.append(new_model)
return models
Credit 데이터세트에 대해 실행
위에서 만든 forward_step_select() 함수를 Credit 데이터세트(df)에 대해 실행한다.
predictors = list(df.columns)
predictors.remove('Balance')
mods = forward_step_select(df, predictors, ['Balance'], max_features=11)
각 모델 크기에 대해 최상의 변수 세트를 출력시킨다. 아래 결과를 보면, 최상의 단일 변수 모델은 Rating만 포함되고, 최상의 2개 변수 모델은 거기에 추가로 Income이 포함된다.
for model_i in mods:
print(model_i.model.exog_names)
['const', 'Rating']
['const', 'Rating', 'Income']
['const', 'Rating', 'Income', 'Student_Yes']
['const', 'Rating', 'Income', 'Student_Yes', 'Limit']
['const', 'Rating', 'Income', 'Student_Yes', 'Limit', 'Cards']
['const', 'Rating', 'Income', 'Student_Yes', 'Limit', 'Cards', 'Age']
['const', 'Rating', 'Income', 'Student_Yes', 'Limit', 'Cards', 'Age', 'Gender_Female']
['const', 'Rating', 'Income', 'Student_Yes', 'Limit', 'Cards', 'Age', 'Gender_Female', 'Ethnicity_Asian']
['const', 'Rating', 'Income', 'Student_Yes', 'Limit', 'Cards', 'Age', 'Gender_Female', 'Ethnicity_Asian', 'Married_Yes']
['const', 'Rating', 'Income', 'Student_Yes', 'Limit', 'Cards', 'Age', 'Gender_Female', 'Ethnicity_Asian', 'Married_Yes', 'Ethnicity_Caucasian']
['const', 'Rating', 'Income', 'Student_Yes', 'Limit', 'Cards', 'Age', 'Gender_Female', 'Ethnicity_Asian', 'Married_Yes', 'Ethnicity_Caucasian', 'Education']
아래 표 10.1에는 최량 부분집합 선택과 전진 단계적 선택에 있어서 예측변수가 1~4개인 경우에 어떤 변수들이 선택되었는지 보여준다. 처음 세 개 모델은 동일하지만 네 번째 모델은 서로 다른 것을 알 수 있다.
표 10.1. Credit 데이터세트에 대한 최량 부분집합 선택 및 전진 단계적 선택에서 변수 개수별로 선택된 최상의 변수 조합.

그림 출처: ISLP, TABLE 6.1
후진 단계적 선택#
후진 단계적 선택은 전진 단계적 선택과 마찬가지로 최량 부분집합 선택에 대한 효율적인 대안을 제공한다. 전진 단계적 선택과 달리 후진 방식을 취하는데, \(p\)개의 예측변수를 모두 포함하는 전체(full) 모델에서 시작하여 한 번에 하나씩 가장 유용하지 않은 예측변수를 반복적으로 제거해 나간다.
우선 이해를 돕기 위해 예측변수가 3개인 경우에 대해 후진 단계적 선택 알고리즘을 생각해보자.
Backward stepwise selection 알고리즘 (\(p=3\))
\(\mathcal M_3\)는 \(3\)개 예측변수 모두를 포함하는 전체(full) 모델을 나타낸다.
(1) \(\mathcal M_3\)에서 예측변수를 한 개 뺀 세 가지 모델(즉 예측변수가 2개인 세 가지 다중 선형 회귀 모델)을 피팅한다. 이 세 가지 모델 중에서 최상의 것을 선택하고, 이를 \(\mathcal M_2\)라고 부른다. 여기서 최상의 모델은 RSS가 가장 작거나 \(R^2\)가 가장 큰 것으로 정의된다.
(2) 이번에는 \(\mathcal M_2\)에서 예측변수를 추가적으로 한 개 뺀 두 가지 모델(즉 예측변수가 1개인 두 가지 단순 선형 회귀 모델)을 피팅한다. 이 두 가지 모델 중에서 최상의 것을 선택하고, 이를 \(\mathcal M_1\)이라고 부른다.
(3) 이번에는 \(\mathcal M_1\)에서 예측변수를 추가적으로 한 개 뺀 모델(즉 예측변수가 하나도 들어있지 않은 null 모델)을 피팅하고, 이를 \(\mathcal M_0\)라고 부른다.정보기준 \(C_p\)(AIC), BIC, adjusted \(R^2\)를 사용하여 \(\mathcal M_0,\mathcal M_1,\mathcal M_2,\mathcal M_3\) 중에서 단일의 최적 모델을 선택한다.(결국 총 7개 모델 중에서 가장 우수한 것을 선택하는 것임)

다음은 예측변수가 \(p\)개일 때, 후진 단계적 선택 알고리즘을 정리한 것이다.
Backward stepwise selection
\(\mathcal M_p\)는 모든 \(p\)개 예측변수를 포함하는 전체(full) 모델을 나타낸다.
\(k = p, p-1,. . ., 1:\)
(1) \(\mathcal M_k\)에서 예측변수가 \(k-1\)개로 하나 줄어든 모든 \(k\)개의 모델을 고려한다.
(2) 이 \(k\)개의 모델 중에서 최상의 것을 선택하고, 이를 \(\mathcal M_{k-1}\)이라고 부른다. 여기서 최상의 모델은 RSS가 가장 작거나 \(R^2\)가 가장 큰 것으로 정의된다.정보기준 \(C_p\)(AIC), BIC, adjusted \(R^2\)를 사용하여 \(\mathcal M_0,...,\mathcal M_p\) 중에서 단일의 최적 모델을 선택한다.
후진 단계적 선택 함수 만들기
후진 단계적 선택 함수는 전진 선택 함수와 매우 유사하다. 단지 update_model() 함수에서 예측변수를 제거해 나간다는 것이 다른 점이다.
def backward_step_select(df, predictors, response):
def process_linear_model(features):
"""
선형 회귀 모델을 구축
"""
X = sm.add_constant(df[features].astype(float)) # bool → float 변환
y = df[response]
model = sm.OLS(y,X).fit()
RSS = model.ssr
return (model, RSS)
def update_model(best_features):
"""
새 모델의 RSS를 계산하고 RSS가 가장 낮은 모델을 반환
"""
results = []
for feature in best_features:
results.append(process_linear_model([x for x in best_features
if x != feature]))
# RSS 가장 낮은 모델을 선택
new_model = sorted(results, key= itemgetter(1)).pop(0)[0]
new_features = list(new_model.params.index)[1:]
return new_features, new_model
models = []
best_features = predictors
while len(best_features) > 0:
best_features, new_model = update_model(best_features)
models.append(new_model)
return models
Credit 데이터세트에 대해 실행
위에서 만든 backward_step_select() 함수를 Credit 데이터세트(df)에 대해 실행한다.
predictors = list(df.columns)
predictors.remove('Balance')
models_b = backward_step_select(df, predictors, ['Balance'])
각 모델 크기에 대해 최상의 변수 세트를 출력시킨다.
for model_i in models_b:
print(model_i.model.exog_names)
['const', 'Income', 'Limit', 'Rating', 'Cards', 'Age', 'Gender_Female', 'Student_Yes', 'Married_Yes', 'Ethnicity_Asian', 'Ethnicity_Caucasian']
['const', 'Income', 'Limit', 'Rating', 'Cards', 'Age', 'Gender_Female', 'Student_Yes', 'Married_Yes', 'Ethnicity_Asian']
['const', 'Income', 'Limit', 'Rating', 'Cards', 'Age', 'Gender_Female', 'Student_Yes', 'Ethnicity_Asian']
['const', 'Income', 'Limit', 'Rating', 'Cards', 'Age', 'Gender_Female', 'Student_Yes']
['const', 'Income', 'Limit', 'Rating', 'Cards', 'Age', 'Student_Yes']
['const', 'Income', 'Limit', 'Rating', 'Cards', 'Student_Yes']
['const', 'Income', 'Limit', 'Cards', 'Student_Yes']
['const', 'Income', 'Limit', 'Student_Yes']
['const', 'Income', 'Limit']
['const', 'Limit']
['const']
10.4 최적 모델 선택#
최량 부분집합 선택, 전진 선택, 후진 선택 등은 \(p\)개 예측변수의 부분집합을 지닌 모델을 만들어 비교한다. 따라서 이들 방법을 구현하려면 예측변수 부분집합 별로 고른 최상의 모델 중 어떤 모델이 가장 적합한지 결정하는 방법이 필요하다. 그런데 RSS와 \(R^2\)의 경우 이들이 계산돼 나온 훈련 데이터세트에 있어서는 예측변수의 개수가 많은 모델일수록 RSS는 작아지고 \(R^2\)는 커진다. 즉 훈련 오차가 작아진다.
그러나 우리는 훈련 오차가 아니라 테스트 오차가 작은 모델을 원한다. 훈련 오차만을 고려해서 변수를 선택하게 되면 과적합 문제가 발생할 수 있다. 이 점에서 RSS와 \(R^2\)는 예측변수 개수가 서로 다른 모델 중에서 최적의 모델을 선택하는 데는 적합하지 않다. 이에 대한 대안이 정보기준과 교차검증이다.
정보기준#
RSS와 \(R^2\)가 갖고 있는 문제를 해결하는 한 가지 방법은 과적합으로 인한 편향(bias)을 감안하여 훈련 오차를 조정하는 방법이다. 훈련 오차를 수학적으로 조정하여 테스트 오차를 추정하는 방법이다. 즉 테스트 오차를 간접적으로 추정하려는 것이다. 여기에 속하는 것들이 \(C_p\), AIC, BIC, Adjusted \(R^2\) 등과 같은 정보기준(또는 모델선택기준)이다. 여기에서는 이 중 Adjusted \(R^2\)에 대해서만 좀 더 자세히 살펴보기로 한다.
예측변수가 \(d\)개 있는 최소 제곱 모형의 경우 Adjusted \(R^2\)는 다음과 같이 계산된다.
식에서 보듯이 Adjusted \(R^2\)를 최대화하는 것은 \(\frac {\rm RSS} {n−d−1}\)을 최소화하는 것과 동일하다. 왜냐하면 \({\rm TSS}\)나 \((n-1)\)은 고정돼 있기 때문이다. 그런데 모델의 변수 개수 \(d\)가 증가하면 \({\rm RSS}\)는 항상 감소하지만, \(\frac {\rm RSS} {n−d−1}\)이 항상 감소하는 것은 아니다(분모에 \(d\)가 있기 때문). 즉 \(R^2\)와 달리 Adjusted \(R^2\)는 모델에 불필요한 변수를 포함하는 경우 그 대가를 지불한다. 이런 식으로 과적합으로 인한 편향을 감안하여 훈련 오차를 조정하는 것이다. 결국 Adjusted \(R^2\)의 값이 클수록 테스트 오차가 작은 것을 의미한다.
ChatGPT Q&A#
AIC, BIC 등의 정보기준에 대해 쉽게 설명해줘.
AIC(Akaike Information Criterion)와 BIC(Bayesian Information Criterion)는 모델 선택에서 사용되는 두 가지 중요한 정보 기준입니다. 이들은 모델의 성능을 평가하고, 여러 모델 중에서 최적의 모델을 선택하는 데 도움을 줍니다. 간단하게 말해서, 이 기준들은 모델이 데이터를 얼마나 잘 설명하는지(적합도)와 모델의 복잡성(사용된 파라미터의 수) 사이의 균형을 평가합니다.
AIC (Akaike Information Criterion)
AIC = 2k - 2ln(L)
여기서,
k는 모델에 있는 파라미터의 수,L은 최대 우도(likelihood)입니다.AIC는 모델의 복잡성과 적합도를 동시에 고려합니다. 모델이 데이터에 더 잘 적합되면 우도(L)가 증가하고, 모델이 더 복잡해지면(더 많은 파라미터를 사용하면) k가 증가합니다.
AIC 값이 낮은 모델을 선호합니다. 낮은 AIC 값은 좋은 모델의 적합도와 상대적으로 낮은 모델 복잡성을 의미합니다.
BIC (Bayesian Information Criterion)
BIC = ln(n)k - 2ln(L)
여기서,
n은 샘플의 크기,k는 모델에 있는 파라미터의 수,L은 최대 우도입니다.BIC도 AIC와 유사하게 모델의 적합도와 복잡성을 고려하지만, 샘플 크기
n을 고려하여 모델의 복잡성에 대해 더 큰 벌칙을 부여합니다.BIC 값이 낮은 모델을 선호합니다. BIC는 특히 큰 데이터셋에서 더 복잡한 모델에 대해 더 엄격한 벌칙을 부여하여 과적합을 방지하는 데 도움이 됩니다.
요약
AIC와 BIC 모두 모델의 적합도와 복잡성 사이의 균형을 찾는 데 사용되며, 값이 낮을수록 좋은 모델로 간주됩니다. BIC는 AIC에 비해 샘플 크기의 영향을 더 많이 받으며, 과적합을 방지하는 데 더 효과적일 수 있습니다. 모델 선택 시에는 이러한 정보 기준 외에도 교차 검증 같은 다른 방법을 함께 고려하는 것이 좋습니다.
검증#
정보기준 대신 검증(validation)을 통해 테스트 오차를 직접 추정할 수 있다. 방법은 간단한데, 훈련 관측 일부를 보류해놓은 다음, 그것을 사용하여 테스트 오차를 추정하는 것이다. 즉 보류해 놓은 관측으로 각 후보 모델에 대해 테스트 세트 오차 또는 교차검증 오차를 계산할 수 있다. 그렇게 하여 테스트 오차가 가장 작은 모델을 선택하면 된다. 검증에서 검증 세트 접근은 따로 떼어 놓은 훈련 세트의 일부를 전적으로 테스트 세트로 사용하는 방식을 말하고, 교차검증 접근은 훈련 세트의 일부를 “번갈아 가면서” 테스트 세트로 사용하는 방식을 말한다.(부록: 교차검증(Cross-Validation) 참조.)
이 방법은 정보기준 방식에 비해 테스트 오차를 직접 추정하고 기본 모델에 대한 가정을 적게 한다는 이점이 있다. 또한 정보기준을 계산하는 데 필요한 모델 자유도(예: 모델의 예측변수 개수)를 정확하게 파악하기 어렵거나, 오차항 분산 \(\sigma^2\)를 추정하기 어려운 경우에도 사용할 수 있다.
과거에는 \(p\)나 \(n\)이 큰 경우, 교차검증을 수행하는 것이 계산적으로 어려워 교차검증 대신 정보기준을 사용하는 경우가 많았다. 그러나 오늘날 컴퓨터 성능이 좋아짐에 따라 교차검증이 매우 매력적인 접근 방식이 되었다.
Credit 데이터세트에 대해 검증 세트 접근(최량 부분집합 선택)
Credit 데이터세트에 대해 다시 한 번 최량 부분집합 선택을 수행해보자. 이때 최적 모델을 찾는 방법으로 검증을 사용한다. 그 중에서도 검증 세트 접근, 즉 훈련 세트의 일부를 떼어서 테스트 세트로 사용하는 방법을 사용한다. 여기에서는 전체 데이터세트를 임의로 절반으로 나누어 각각 훈련 세트와 테스트 세트로 사용한다.
np.random.seed(0)
df_train = df.sample(frac=0.5)
df_test = df.drop(df_train.index)
훈련 세트(df_train)에 대해 앞에서 만든 best_subsets 함수를 적용하여 예측변수 개수 별로 최상의 모델을 선택한다.
predictors = list(df_train.columns)
predictors.remove('Balance')
models = best_subsets(df_train, predictors, ['Balance'], max_features=11)
이제 따로 떼어 놓은 테스트 세트(df_test)를 이용하여 각 모델 크기 별로 검증 세트 오차(MSE: Mean Squared Error)를 계산한다.
mses = np.array([])
for model in models:
features = list(model.params.index[1:])
X_test = sm.add_constant(df_test[features])
Balance_pred = model.predict(X_test)
mses = np.append(mses, np.mean((Balance_pred - df_test.Balance.values)**2))
print('MSEs =', mses)
MSEs = [54282.25816835 26135.56555707 11129.23122325 10274.42992706
10170.0485311 10319.79376989 10167.24353295 10379.68738791
10219.55383892 10261.6016929 10262.22967703]
min_index, min_mse = min(enumerate(mses), key=itemgetter(1))
print(min_index, min_mse)
6 10167.243532952185
위 결과를 보면, 가장 좋은 모델은 7개의 변수를 가진 모델이다. 각 모델 크기에 대해 MSE 추정치를 그림으로 그려보자. 변수 개수가 3개보다 많아지면 테스트 MSE가 별로 바뀌지 않는 것을 알 수 있다.
plt.rcParams['font.size'] = '8' # 전체적으로(globally) 폰트 크기 조정
fig, ax1 = plt.subplots(figsize=(5,3))
num_predictors = np.linspace(1,len(models),len(models)) # X축에 예측변수 개수 설정
ax1.plot(num_predictors, mses, 'r', marker='o', label='MSE')
ax1.plot(min_index+1, min_mse, 'gx', markersize=10, markeredgewidth=2)
ax1.set_xlabel('Number of Predictors')
ax1.set_ylabel('Validation MSE')
ax1.legend(loc='best')
plt.show()
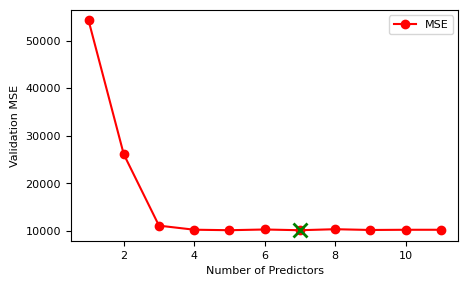
Credit 데이터세트에 대해 10중 교차검증 접근(최량 부분집합 선택)
이제 10중 교차검증을 사용하여 최량 부분집합 선택을 수행해보자. 우선 데이터를 10개 폴드로 분할한다. 변수 개수가 11개이기 때문에 총 10개 폴드 각각에 (해당 폴드가 테스트 세트로 사용될 때) 11개 모델에 대한 MSE가 생성된다. 이를 평균하여 교차검증 테스트 MSE를 얻는다.
kf = KFold(n_splits=10, shuffle=True, random_state=1) # sklearn의 KFold로 10개 폴드 생성
mses = np.zeros([10, len(predictors)]) # 10Xp 행렬: 모델 크기별로 10개 테스트 세트의 MSE 저장
for train_index, test_index in kf.split(df):
df_train = df.iloc[train_index]
df_test = df.iloc[test_index]
models = best_subsets(df_train, predictors, ['Balance'], max_features=11)
# 각 모델의 MSE 계산
for idx, model in enumerate(models):
features = list(model.params.index[1:])
X_test = sm.add_constant(df_test[features])
Balance_pred = model.predict(X_test)
mses[:,idx] = np.mean((Balance_pred - df_test.Balance.values)**2)
# 모델 크기별로 10개 폴드의 MSE를 평균함
cvs = np.mean(mses, axis=0)
교차검증 테스트 오차를 그림으로 그린다. 아래 결과를 보면, 변수가 3개인 모델이 가장 낮은 테스트 MSE를 산출하는 것으로 나타났다.
fig, ax1 = plt.subplots(figsize=(5,3))
num_predictors = np.linspace(1,len(models),len(models)) # X축에 예측변수 개수 설정
min_index, min_CV = min(enumerate(cvs), key=itemgetter(1)) # 평균 MSE가 가장 낮은 모델
ax1.plot(num_predictors, cvs, 'b', marker='o', label='Test MSE')
ax1.plot(min_index+1, min_CV, 'rx', markersize=10, markeredgewidth=2)
ax1.set_xlabel('Number of Predictors')
ax1.set_ylabel('CV Error')
ax1.legend(loc='best')
plt.show()
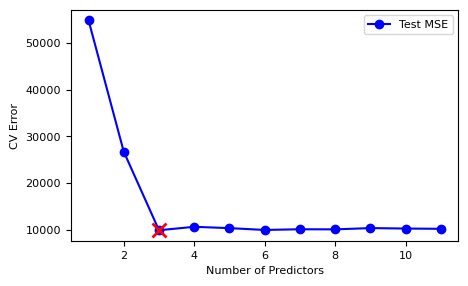
10.5 Ridge 및 Lasso#
앞에서 설명한 부분집합 선택 방법은 예측변수의 최적 세트를 찾는 것으로서 최소제곱 방법을 사용하는 것에는 변함이 없다. 이에 대한 대안으로 (모든 \(p\)개 예측변수를 포함하는 모델을 사용하되) 계수 추정값을 0쪽으로 축소하는 기법을 사용할 수 있다. 이러한 방법이 피팅의 성과를 개선하는 이유가 언뜻 명확하게 다가오지 않을 수 있지만, 계수 크기를 축소시키면 무엇보다 추정 계수의 분산을 크게 줄일 수 있다. 회귀 계수를 0쪽으로 축소시키는 가장 잘 알려진 두 가지 기법은 릿지(Ridge) 회귀와 라쏘(Lasso) 이다.
릿지와 라쏘를 수행하기 위해 sklearn 패키지를 사용한다. 이 패키지의 주요 함수는 Ridge 회귀 모델을 피팅하는 데 사용하는 Ridge(), 그리고 Lasso 모델을 피팅하는 Lasso()이다. 또한 교차검증과 관련된 RidgeCV() 및 LassoCV()가 있다.
Ridge 회귀#
릿지 회귀는 선형 회귀 모델에 다중공선성(multicollinearity), 즉 예측변수들 사이에 상관성이 높아 최소제곱 추정값에 부정확성이 높아지는 것에 대한 하나의 해법으로 1970년대에 개발되었다. 앞에서 설명했듯이 최소제곱(OLS) 피팅은 다음의 잔차제곱합(RSS)을 최소화하는 방식으로 \(\beta_0, \beta_1,..., \beta_p\)를 추정한다.
릿지는 최소제곱과 매우 유사하지만 RSS가 아니라 다음을 최소화하는 회귀 계수 추정치 \(\hat\beta{^R_\lambda}\)을 구한다.
여기서 \(\lambda ≥ 0\)은 조정 파라미터(tuning parameter)이다.
위 식 10.2는 두 가지 다른 기준을 절충한다. 우선 최소제곱과 마찬가지로 릿지 회귀는 RSS를 작게 만들어 데이터에 잘 맞는 계수 추정치를 찾는다. 그러면서 다른 한편으로 축소 페널티(shrinkage penalty)로 불리는 두 번째 항 \(\lambda \sum_{j=1}^p \beta_j^2\)는 \(\beta_j\)의 추정치를 0쪽으로 축소시키는 효과가 있다(절편은 제외). 왜냐하면 \(\beta_1,..., \beta_p\)가 0에 가까울수록 축소 페널티 항이 작아지기 때문이다.
여기에서 조정 파라미터 \(\lambda\)는 회귀 계수 추정치에 대한 위 두 개 항의 상대적 영향을 제어하는 역할을 한다. \(\lambda = 0\)이면 페널티 항은 효과가 없으며, 릿지는 최소제곱 추정값을 생성한다. 반면 \(\lambda \to \infty\)일수록, 축소 페널티의 영향이 커지고 릿지 회귀 계수 추정치가 0에 가까워진다.
하나의 계수 추정 세트만 생성하는 최소제곱과 달리 릿지는 각 \(\lambda\)값 별로 다른 계수 추정 세트 \(\hat\beta{^R_\lambda}\)를 생성한다. 따라서 좋은 \(\lambda\)값을 선택하는 것이 중요하다. 이를 위해서는 교차검증을 활용할 필요가 있다.
Credit 데이터세트 릿지 회귀 실행#
from sklearn.preprocessing import scale
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge, RidgeCV, Lasso, LassoCV
from sklearn.metrics import mean_squared_error
Ridge() 함수에는 모델을 조정하는 데 사용되는 파라미터 alpha(\(\lambda\)에 해당)가 있다. 우리는 매우 큰 값부터 아주 작은 값까지의 숫자를 생성시켜 \(\lambda\)값으로 사용하고자 한다. 이렇게 함으로써 절편만 포함하는 영(null) 모델부터 최소제곱 피팅에 이르기까지 전체 시나리오를 포괄할 수 있다. 즉 \(\lambda\)값이 아주 크면, 축소 페널티의 영향이 커져서 절편을 제외하고는 계수 값이 0쪽으로 축소되고, 반대로 \(\lambda\)값이 아주 작으면, 릿지 회귀는 최소제곱 추정에 가까워진다.
아래에서는 100개의 \(\lambda\)값에 대해 릿지 회귀 계수 벡터를 추정하여 coefs라는 이름으로 지정한다. 따라서 coefs는 100개의 행(각 \(\lambda\)값에 대해 하나씩)과 11개의 열(Credit 데이터세트 각 예측변수에 대해 하나씩)이 있는 \( 100 \times 11 \) 행렬이다.
추정하기 전에 예측변수가 동일한 척도를 갖도록 표준화시키는 작업을 거쳤다.
alphas = 3**np.linspace(10,-10,100)*0.2
print(alphas)
[1.18098000e+04 9.45920006e+03 7.57645902e+03 6.06845514e+03
4.86060147e+03 3.89315667e+03 3.11827024e+03 2.49761571e+03
2.00049507e+03 1.60232036e+03 1.28339759e+03 1.02795260e+03
8.23350883e+02 6.59472702e+02 5.28212520e+02 4.23078113e+02
3.38869457e+02 2.71421530e+02 2.17398309e+02 1.74127767e+02
1.39469710e+02 1.11709926e+02 8.94753968e+01 7.16663854e+01
5.74020455e+01 4.59768524e+01 3.68257079e+01 2.94959896e+01
2.36251644e+01 1.89228570e+01 1.51564878e+01 1.21397696e+01
9.72349310e+00 7.78814768e+00 6.23800970e+00 4.99640821e+00
4.00193270e+00 3.20539569e+00 2.56739988e+00 2.05638953e+00
1.64708970e+00 1.31925613e+00 1.05667392e+00 8.46355567e-01
6.77898578e-01 5.42970945e-01 4.34899050e-01 3.48337577e-01
2.79005134e-01 2.23472487e-01 1.78992952e-01 1.43366538e-01
1.14831137e-01 9.19753677e-02 7.36687669e-02 5.90058768e-02
4.72614602e-02 3.78546298e-02 3.03201169e-02 2.42852590e-02
1.94515676e-02 1.55799649e-02 1.24789586e-02 9.99517057e-03
8.00575099e-03 6.41230167e-03 5.13600944e-03 4.11374797e-03
3.29495546e-03 2.63913385e-03 2.11384571e-03 1.69310991e-03
1.35611656e-03 1.08619772e-03 8.70003010e-04 6.96839279e-04
5.58141725e-04 4.47050267e-04 3.58070239e-04 2.86800625e-04
2.29716379e-04 1.83994071e-04 1.47372244e-04 1.18039555e-04
9.45451886e-05 7.57270956e-05 6.06545197e-05 4.85819604e-05
3.89123002e-05 3.11672706e-05 2.49637968e-05 1.99950506e-05
1.60152740e-05 1.28276246e-05 1.02744388e-05 8.22943421e-06
6.59146340e-06 5.27951117e-06 4.22868739e-06 3.38701756e-06]
y = df.Balance
X = df.drop(['Balance'], axis=1)
X = (X-X.mean())/X.std() # 변수 표준화
ridge = Ridge()
coefs = []
for a in alphas:
ridge.set_params(alpha = a)
ridge.fit(X, y)
coefs.append(ridge.coef_)
np.shape(coefs)
(100, 11)
각 \(\lambda\)값에 따라 (표준화) 추정 계수가 어떻게 달라지는지 그림으로 그린 결과가 아래 나와 있다.
fig, ax = plt.subplots(figsize=(5,3))
ax = plt.gca()
ax.plot(alphas, coefs)
ax.set_xscale('log')
plt.axis('tight')
plt.xlabel('$\lambda$')
plt.ylabel('Standardized Coefficients')
plt.show()
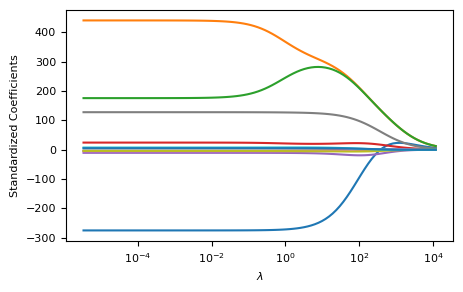
Ridge vs. OLS 테스트 오차 비교
이제 릿지와 OLS(최소제곱)의 예측 성과를 테스트 오차로 측정해보기로 한다. 이를 위해 표본을 훈련 세트와 테스트 세트로 1/2씩 임의로 분할한다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=1)
먼저 OLS 회귀를 수행한다. OLS는 \(\lambda=0\)인 릿지 회귀라는 것을 기억하자. 아래 결과에서 보듯이 테스트 MSE는 10,748이다.
ridge = Ridge(alpha = 0)
ridge.fit(X_train, y_train) # 훈련 데이터에 Ridge 회귀 피팅
pred = ridge.predict(X_test) # 이 모델을 사용하여 테스트 데이터 예측
print(pd.Series(ridge.coef_, index = X.columns)) # 추정 계수 프린트
print(mean_squared_error(y_test, pred)) # 테스트 MSE 계산
Income -283.216086
Limit 330.789952
Rating 293.345189
Cards 16.265604
Age -12.598182
Education -4.211196
Gender_Female 0.662339
Student_Yes 127.095619
Married_Yes -1.089227
Ethnicity_Asian 10.176119
Ethnicity_Caucasian 1.890813
dtype: float64
10748.84285383294
교차검증으로 조정 파라미터 \(\lambda\) 선택
동일한 훈련 데이터세트에 이번에는 릿지 회귀를 실행한다. 이를 위해서는 조정 파라미터 \(\lambda\)를 선택해야 하는데, 교차검증으로 최적의 \(\lambda\)를 찾기로 하자. 그 방법은 앞에서 만든 100개의 \(\lambda\)값 중에서 교차검증 오차를 가장 작게 만드는 \(\lambda\)를 선택하는 것이다.
교차검증은 RidgeCV() 함수를 사용하여 수행할 수 있다. 기본적으로 이 함수는 LOOCV 방식(부록 참조)으로 실행되지만 파라미터 cv를 사용하여 이를 변경할 수 있다(여기서는 5중 교차검증을 선택함).
ridgecv = RidgeCV(alphas = alphas, cv = 5)
ridgecv.fit(X_train, y_train)
ridgecv.alpha_
0.8463555674388502
가장 작은 교차검증 오차를 발생시키는 \(\lambda\)값이 0.8463임을 알수 있다. 이 \(\lambda\)값에 해당하는 테스트 MSE를 구해보자.
ridge = Ridge(alpha = ridgecv.alpha_)
ridge.fit(X_train, y_train)
mean_squared_error(y_test, ridge.predict(X_test))
10720.74768127418
앞에서 OLS 회귀의 경우 테스트 MSE가 10,748이었는데, 릿지 회귀는 테스트 MSE가 10,720으로서 추정 성과가 근소하게 개선된 것으로 나타났다.
마지막으로 교차검증을 통해 선택된 \(\lambda\)값을 사용하여 훈련 데이터 세트에 릿지 회귀 모델을 피팅한 계수 추정치를 프린트해보자. 아래 결과를 보면, 정확히 0인 계수는 하나도 없다. 즉, 릿지 회귀는 변수선택을 수행하지는 않는다.
pd.Series(ridge.coef_, index = X.columns)
Income -277.316218
Limit 314.041645
Rating 303.722287
Cards 15.741641
Age -12.512098
Education -3.827018
Gender_Female 1.082010
Student_Yes 126.126134
Married_Yes -0.906208
Ethnicity_Asian 10.239514
Ethnicity_Caucasian 2.375923
dtype: float64
Lasso#
릿지 회귀에는 한 가지 명백한 단점이 있다. 변수 중 일부만 포함하는 모델을 선택하는 최량 부분집합, 전진 단계적 선택, 후진 단계적 선택 등과 달리 릿지는 주어진 \(p\)개 예측변수를 모두 다 사용한다는 점이다. 릿지의 페널티 항 \(\lambda \sum\beta_j^2\)는 계수를 0쪽으로 축소시키기는 하지만, (\(\lambda \to \infty\)이 아닌 한) 정확히 0으로 만들지는 않는다. 이는 예측 정확도에는 문제가 되지 않을지 몰라도 변수 개수가 상당히 많은 경우 모델 해석에 문제를 일으킬 수 있다.
릿지의 이러한 단점을 극복하려는 비교적 최근의 대안이 라쏘(Lasso: Least absolute shrinkage and selection operator)이다. 라쏘는 다음을 최소화시키는 회귀 계수 추정치를 \(\hat\beta{^L_\lambda}\)을 구하는 방식이다.
식 10.2와 10.3을 비교해보면, 라쏘와 릿지의 두 추정 방식이 상당히 비슷한 것을 알 수 있다. 유일한 차이점은 릿지는 페널티 항에 \(\beta_j^2\)가 들어있는데 반해, 라쏘에서는 그것이 절대값 \(|\beta_j|\)로 대체되었다는 점이다.
통계학 및 머신러닝에서 라쏘는 변수선택과 정규화를 모두 수행함으로써 통계 모델의 예측 정확도와 해석 가능성을 향상시키는 방법으로 평가받는다. 우리는 앞에서 Credit 데이터세트에서 적절한 \(\lambda\)값을 사용한 릿지가 최소제곱(OLS)보다 예측성과가 약간 더 낫다는 것을 확인했다. 이번에는 동일한 Credit 데이터세트에 대해 라쏘와 릿지를 비교해보자.
라쏘 모델 피팅은 Lasso() 함수를 사용한다. 여기에서는 max_iter = 10000으로 설정했다. 계수 추정치를 반복적 최적화(iterative optimization) 방식으로 찾는데, 최대 반복 횟수를 10,000번으로 정한 것이다. 이것 외에는 릿지 모델을 피팅할 때와 마찬가지이다.
lasso = Lasso(max_iter = 10000)
coefs = []
for a in alphas:
lasso.set_params(alpha=a)
lasso.fit(scale(X_train), y_train)
coefs.append(lasso.coef_)
fig, ax = plt.subplots(figsize=(5,3))
ax = plt.gca()
ax.plot(alphas, coefs)
ax.set_xscale('log')
plt.axis('tight')
ax.set_xlabel('$\lambda$')
plt.ylabel('Standardized Coefficients')
plt.show()
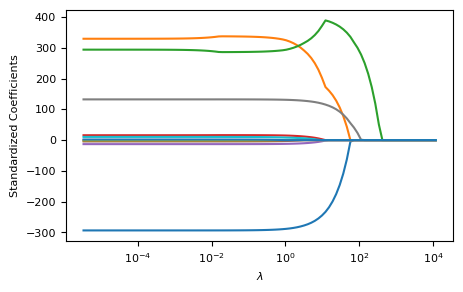
위 추정 계수 그림에서 보듯이 조정 파라미터 \(\lambda\)값이 커짐에 따라 일부 계수는 정확히 0이 된다.
이제 5중 교차검증을 수행하여 최적의 \(\lambda\)를 선택하고 모델을 다시 피팅한 다음, 테스트 오차를 계산한다.
lassocv = LassoCV(alphas = None, cv = 5, max_iter = 100000)
lassocv.fit(X_train, y_train)
lasso.set_params(alpha=lassocv.alpha_)
lasso.fit(X_train, y_train)
mean_squared_error(y_test, lasso.predict(X_test))
10703.166435003932
테스트 MSE가 10,703으로서 OLS(10,748)와 릿지(10,720)보다 오차가 더 작은 것으로 나타났다.
마지막으로 교차검증을 통해 선택한 \(\lambda\)값을 사용하여 훈련 데이터 세트에 라쏘 모델을 피팅한 계수 추정치를 프린트해보자. 아래 결과를 보면, 라쏘는 릿지와 달리 11개 계수 추정치 중 3개가 정확히 0이라는 것을 알 수 있다.
pd.Series(lasso.coef_, index=X.columns)
Income -275.276030
Limit 312.652360
Rating 302.921967
Cards 14.069159
Age -11.186074
Education -1.990272
Gender_Female 0.000000
Student_Yes 124.971533
Married_Yes -0.000000
Ethnicity_Asian 7.371007
Ethnicity_Caucasian 0.000000
dtype: float64
부록: 교차검증(Cross-Validation)#
앞에서 테스트 오차와 훈련 오차의 차이에 대해 설명했다. 테스트 오차는 통계적 기법을 훈련하는 데 사용되지 않은 관측에 대한 반응을 예측할 때 발생하는 평균 오차이다. 그런데 현실에서는 테스트 세트가 항상 주어지는 것은 아니다. 이에 반해 훈련 오차의 경우에는 훈련에 사용된 관측에 통계적 학습 방법을 적용하여 쉽게 계산할 수 있다. 그러나 앞에서 보았듯이 훈련 오차는 종종 테스트 오차와 상당히 다르며 특히 전자는 후자를 극적으로 과소평가할 수 있다(즉 과적합 문제).
테스트 오차를 직접 추정하는 데 사용할 수 있는 (매우 큰) 테스트 세트가 없는 경우, 훈련 데이터를 사용하여 이를 추정하는 기법들이 있다. 먼저 훈련 오차를 수학적으로 조정하여 테스트 오차를 간접 추정하는 방법이다. AIC, BIC 등이 그것이다. 다른 한편으로는 훈련 관측 일부를 보류해 놓은 다음 그것을 사용하여 테스트 오차를 직접 추정하는 방법이 있다. 이를 검증(validation)이라고 부른다.
검증에는 검증 세트(validation set) 접근방식, 단일제외 교차검증(Leave-one-out CV: LOOCV) 접근방식, 다중 교차검증(k-fold CV) 접근방식이 있다. 검증 세트 접근은 따로 떼어 놓은 훈련 세트의 일부를 전적으로 테스트 세트로 사용하는 방식을 말하고, “교차”검증은 훈련 세트의 일부를 “번갈아 가면서” 테스트 세트로 사용하는 방식을 말한다.
검증 세트 접근방식#

그림 출처: ISLP, FIGURE 5.1
주어진 \(n\)개의 관측을 무작위로 훈련 세트(그림에서 파란색으로 표시된 것으로서 7, 22, 13번 관측이 여기에 포함됨)와 검증 세트(베이지 색으로 표시된 것으로서 91번 관측이 여기에 포함됨)로 분할한다. 훈련 세트에 통계적 학습 기법을 피팅한 다음, 검증 세트에 대해 그 성능을 평가한다.
단일제외 교차검증 접근방식#
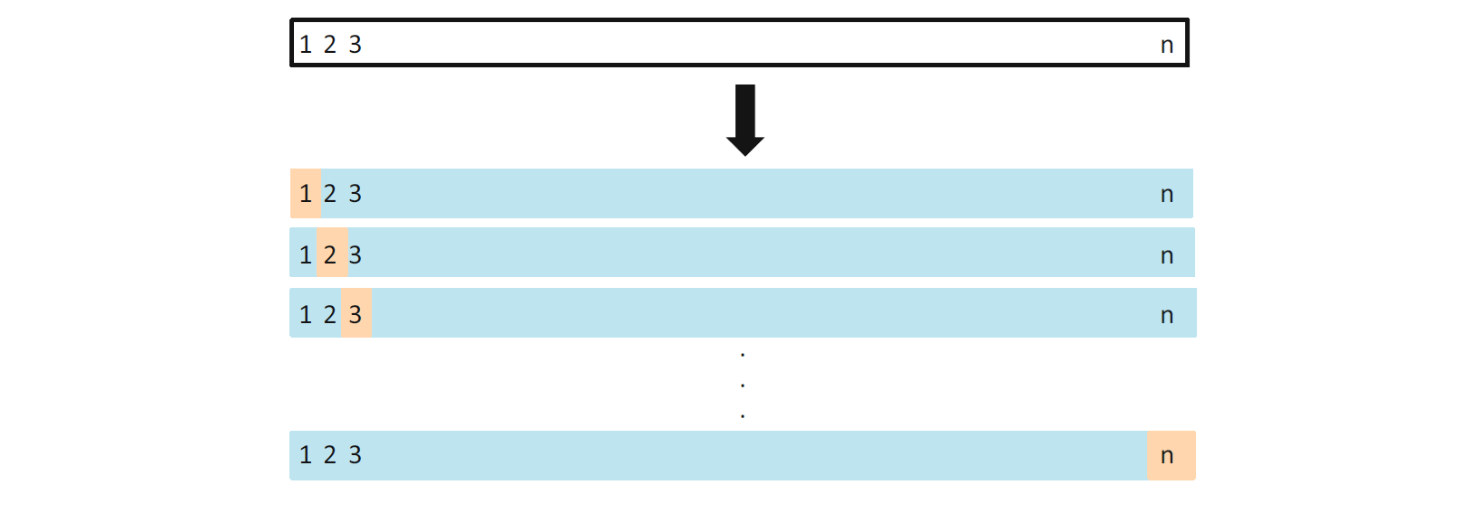
그림 출처: ISLP, FIGURE 5.3
주어진 \(n\)개의 관측을 훈련 세트(파란색으로 표시)와 검증 세트(베이지 색으로 표시)로 반복적으로 분할하는 방식으로서 첫 번째 분할에서는 1번 관측이 검증 세트이고 1번을 제외한 나머지 모든 관측이 훈련 세트에 포함되고, 두 번째 분할에서는 2번 관측이 검증 세트이고 2번을 제외한 나머지 모든 관측이 훈련 세트에 포함되는 식으로 \(n\)번의 분할을 계속해서 수행하는 방식이다. 테스트 오차는 \(n\)개의 MSE 추정치를 평균하여 추정한다.
5중 교차검증 접근방식#
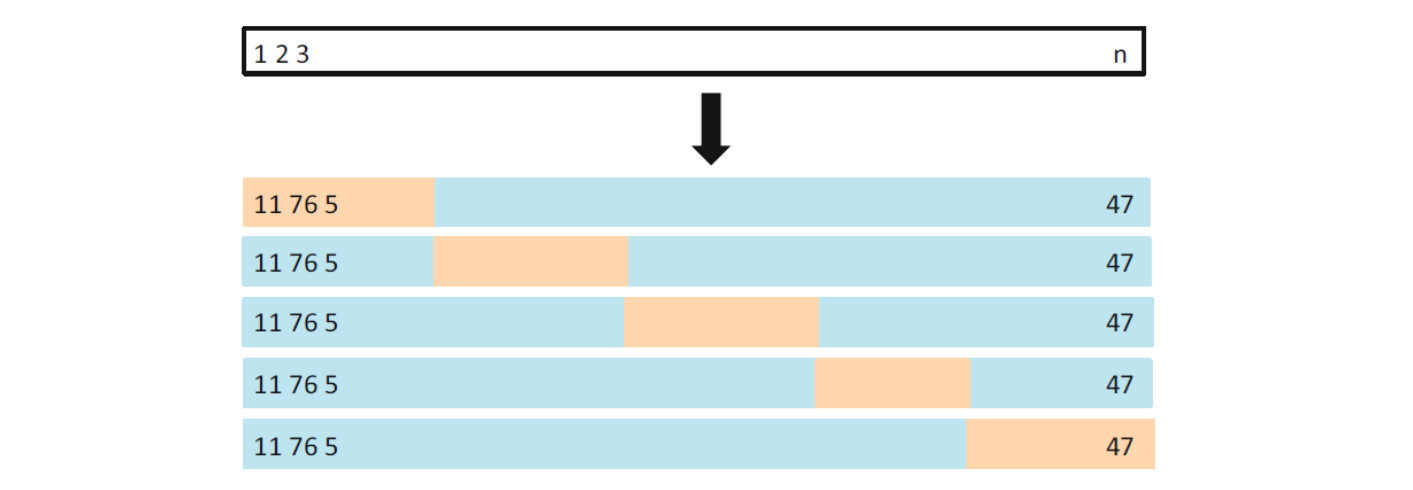
그림 출처: ISLP, FIGURE 5.5
주어진 \(n\)개의 관측을 5개의 겹치지 않는 그룹으로 무작위로 분할한다. 각 1/5의 관측이 번갈아 가면서 검증 세트(베이지 색으로 표시)가 되고, 그때마다 나머지 4/5의 관측이 훈련 세트(파란색으로 표시)가 되는 방식이다. 테스트 오차는 5개의 MSE 추정치를 평균하여 추정한다.