17장 생존분석#
자료 출처: ISLP (An Introduction to Statistical Learning with Applications in Python)
17.1 소개#
이 장에서는 생존분석(survival analysis)에 대해 다룬다. 생존분석은 환자의 사망이나 기계 시스템에서의 고장(failure)과 같은 특정 이벤트가 발생할 때까지의 소요 시간을 분석하는 통계학의 한 분야다. 분석하려는 목표변수가 특이한데, 그것은 다름 아닌 어떤 사건(event)이 발생할 때까지의 시간이다. 여기에서 ‘사건’이란 이루 다 열거할 수 없을 만큼 다양한 예가 가능한데, 가장 대표적 예가 ‘사망’이다. 가령 어떤 수술을 받은 환자가 사망에 이르기까지의 생존기간을 기록한 데이터를 생각해보자. 이때의 사건(event)은 ‘사망’이 된다. 사망에 이르기까지의 시간, 즉 생존시간(survival time)이 우리가 분석하려는 목표변수다.
생존분석이라는 용어는 의학보건 분야 연구를 연상시키지만 생존분석의 적용 범위는 공학, 경제학, 경영학 등 매우 광범위하다. 공학에서는 신뢰도(reliability) 이론 또는 신뢰도 분석, 경제학에서는 듀레이션(duration) 분석 또는 듀레이션 모델링, 사회학에서는 이벤트 히스토리 분석이라고도 불린다.
ChatGPT Q&A#
생존분석이 활용되는 분야나 주제를 가급적 많이 알려줘.
생존분석은 다양한 분야에서 활용되며 주요한 응용 분야 중 일부는 다음과 같습니다:
의학 및 생물학: 생존분석은 암의 치료 효과, 신약 효능, 생물학적 생존 기간 등을 평가하는 데 사용됩니다.
공학 및 신뢰도 공학: 제품이나 장비의 수명을 예측하고 고장 예측에 활용됩니다.
경제학: 듀레이션(지속 시간) 분석은 소비자 구매력, 신제품 도입 시간 등을 이해하는 데 활용됩니다.
사회학: 생존분석은 이벤트의 발생이 시간에 따라 어떻게 변하는지를 연구하여 사회 현상을 이해하는 데 사용됩니다.
금융 및 보험: 금융 분야에서는 보험 청구, 금융 상품의 수명 주기 등을 분석하는 데 활용됩니다.
환경과 생태학: 생태학적 연구에서는 생물종의 생존 및 소멸 패턴을 이해하는 데 사용됩니다.
인구 통계학: 인구 조사 및 통계에서는 특정 집단의 생존 기간 및 사망률을 연구하는 데 활용됩니다.
소프트웨어 개발: 소프트웨어의 수명주기 및 버그 발생 패턴을 분석하여 소프트웨어 신뢰성을 평가하는 데 사용됩니다.
이 외에도 다양한 분야에서 생존분석은 시간과 사건 간의 관계를 이해하고 예측하는 데 활용되어 광범위한 응용이 이루어지고 있습니다. 몇 가지 추가적인 예를 살펴보겠습니다:
신약 개발: 의약품 산업에서는 새로운 약물이나 치료법의 효과를 평가하고 환자의 생존 기간을 예측하는 데에 활용됩니다.
고객 이탈 분석: 비즈니스 분야에서는 서비스 이용자들이 얼마 동안 이용하고 있는지, 언제 이탈하는지 등을 파악하여 이탈을 예측하고 개선점을 찾는 데 사용됩니다.
인간 행동 연구: 생존분석은 인간 행동, 특히 변화되는 행동 패턴이나 어떤 이벤트에 영향을 받는 특정 행동을 연구하는 데 활용됩니다.
프로젝트 관리: 프로젝트의 각 단계에서의 생존 확률을 추정하여 프로젝트 완료 예측 및 리스크 관리에 사용됩니다.
소비재 등의 제품 수명 주기 예측: 제품의 수명 주기를 예측하고 제품이 언제 고장나거나 더 이상 사용되지 않을지를 평가하는 데 사용됩니다.
시장 조사: 새로운 제품이나 서비스가 시장에서 얼마 동안 유지될 수 있는지, 어떤 인자가 시장에서의 생존에 영향을 미치는지 등을 연구하는 데 활용됩니다.
인터넷 서비스 및 소프트웨어 분석: 사용자가 웹 서비스나 소프트웨어를 얼마 동안 사용하는지를 추적하고 분석하여 개선점을 찾는 데 사용됩니다.
이러한 다양한 응용 분야에서 생존분석은 데이터를 이해하고 예측하는 강력한 도구로 활용되고 있습니다.
17.2 생존시간 및 중도절단시간#
생존분석은 사건의 종류에 따라 그것이 발생하는 데까지 걸린 시간을 여러가지 용어(사건시간, 고장시간, 구독시간, 재발시간 등)로 표현할 수 있는데, 우리는 이 모두를 통칭해서 생존시간이란 용어를 종종 사용할 것이고, 그것에 대한 분석을 생존분석이라고 표현할 것이다. 즉, 생존분석에서 말하는 생존시간이 반드시 환자가 사망에 이르기까지의 시간을 의미하는 것은 아니며, 그 포괄범위는 매우 넓다.
암 치료 분석 데이터를 생각해보자. 암 치료를 받은 환자들을 5년간 관찰했다. 그 과정에서 환자별로 여러 특성(feature) 데이터가 모아졌으며, 그것으로 환자의 생존시간을 분석 예측하는 모델을 만들려고 한다.
이 경우 생존시간을 반응변수로 놓고 여러 특성들을 이용해 앞에서 배운 회귀 모형으로 분석하면 되지 않을까 생각할 수도 있다. 그러나 생존시간 데이터는 지금까지 우리가 다룬 반응변수와는 뚜렷이 구별되는 중요한 차이점을 갖고 있다. 우선 시간이기 때문에 그 값이 항상 0보다 크다는 점을 들 수 있지만, 이 부분은 마이너한 것이다. 핵심적인 차이는 일부 관측값이 중도절단(censored)되었다는 점이다.(‘censored’는 검열, 삭제 등을 의미하며, 센서(sensor)와는 무관한 단어다.)
참고: 생존시간 용어
생존시간은 “사망에 이르기까지의 시간”이기 때문에 이를 줄여서 사망시간으로 표현할 수도 있다. 즉 “생존”시간과 “사망”시간이라는 정반대의 단어가 동일한 것을 지칭하는 데 사용되는 것이다. 또한 사망시간을 사망시점이라고도 할 수 있다. 즉, 생존시간, 사망시간, 사망시점은 모두 같은 것을 지칭한다.
치매 발생 시기를 기록한 데이터가 있을 때, 거기 들어있는 숫자(가령 65세)는 (1) 치매가 아직 발생하지 않은 정상시간(즉 65년 동안 치매가 발생하지 않음)이면서, 동시에 (2) 치매 발생까지 걸린 시간, 또는 간단히 (3) 치매발생시간 등으로 표현할 수 있을 것이다.
또 다른 예로 어떤 기계나 설비가 고장(failure)이 나는 사건을 생각해보자. 이때는 고장에 이르기까지의 시간, 즉 정상가동시간이 분석 대상 시간이 된다. 이 경우 역시 정상시간을 고장시간 또는 고장시점으로 표현할 수 있다.
이밖에도 가령 구독취소를 분석한다면 구독취소가 관심사건이 되고, 분석의 목표변수는 구독기간 또는 (구독)취소시간이다.
또 어떤 병이나 증상이 재발되는 것을 분석한다면 여기에서의 사건은 증상의 재발이고, 목표변수는 정상기간(또는 재발시간)이 된다.
ChatGPT Q&A#
“생존시간”을 “사망시간”으로도 부를 수 있다고 생각하는데 너의 생각은 어때?
“생존시간”과 “사망시간”은 통계학이나 의학 연구에서 자주 사용되는 용어이며, 이 두 용어는 상황에 따라 다르게 해석될 수 있습니다.
생존시간(Survival Time): 보통은 어떤 치료를 받거나 특정 시점(예: 질병 진단 시)부터 측정된 시간을 의미합니다. 이 용어는 대상이 살아있는 동안의 시간을 강조합니다. 생존 분석(Survival Analysis)에서 중요한 개념으로, 특정 시점까지 살아남은 비율을 추정하는 데 사용됩니다.
사망시간(Time until death): 이 용어는 어떤 시작점(예: 질병 진단, 치료 시작)부터 사망에 이르기까지의 시간을 의미합니다. 이는 생존시간의 끝점을 특정하는 방식으로 사용되며, 생존 분석에서도 중요한 지표입니다.
두 용어는 서로 관련이 있지만, 연구의 초점에 따라 선택되는 용어가 달라질 수 있습니다. 생존시간은 보다 긍정적인 결과나 생존율의 향상을 강조할 때 사용되는 경향이 있으며, 사망시간은 사망 위험 또는 위험 요소에 더 초점을 맞출 때 사용될 수 있습니다. 따라서, 연구의 목적과 맥락에 따라 적절한 용어를 선택하는 것이 중요합니다.
각 용어의 선택은 데이터를 해석하고 결과를 전달하는 방식에 영향을 미칠 수 있으므로, 사용하는 용어가 연구의 목적과 어떻게 일치하는지 고려하는 것이 중요합니다.
중도절단의 의미#
중도절단의 의미는 다음과 같다. 가령 암치료를 받은 환자가 3명만 있는 간단한 예를 생각해보자. 이들 중 첫 번째와 두 번째 환자는 각각 1년, 2년 후 사망한 반면, 마지막 세 번째 환자는 5년의 연구기간 동안 사망하지 않고 생존했다. 이때 우리는 세 명의 관측시간(년)을 [1, 2, 5]로 기록하게 되는데, 이 3개의 숫자 중 처음 2개는 생존시간이지만, 마지막(즉 5년)은 당연히 생존시간이 아니다. 왜냐하면 5년째에 사망하지 않고 여전히 생존해 있기 때문이다. 즉 관측시간 [1, 2, 5]의 3개 원소가 동일한 의미를 지닌 시간이 아니다. 우리는 처음 2개를 생존시간이라고 표현하고 마지막은 중도절단시간이라고 표현한다. 세 번째 환자의 경우에는 생존시간, 즉 언제까지 생존할지는 아직 관측되지 않았고, 단지 암치료 후 5년까지 생존해있다는 것만 관찰된 상황이다. 그런 의미에서 세 번째 환자의 생존시간은 “잘린”(censored) 것이다.
위의 간단한 예에서 (세 번째 환자의 관측시간은 생존시간이 아니기 때문에) 세 번째 환자를 표본에서 제외시키고 생존시간을 분석하면 어떻게 될까? 이 경우 분석은 훨씬 간단해진다. 앞에서 배운 선형회귀나 다항(polynomial)회귀로도 분석할 수 있을 것이다.(단, 이 경우 생존시간 관측값이 항상 0보다 크다는 점을 감안할 수 없다는 문제는 안고 있다.)
그러나 세 번째 환자를 분석에서 제외하는 것은 아주 귀중한 정보를 배제시키는 것이다. 관측된 시간이 비록 생존시간은 아니지만 생존시간을 분석하는 데 중요한 정보를 제공하기 때문이다. 왜냐하면 정확한 생존시간은 모르지만 “생존시간이 최소 5년 이상”이라는 의미있는 정보를 말해주기 때문이다. 따라서 3번 환자를 제외시켜서는 안된다. 3번 환자가 제공하는 정보를 포함시켜 분석하려다 보니까 생존분석이 선형회귀 분석보다는 복잡해진다. 한마디로 중도절단 관측의 존재가 분석을 좀 더 복잡하게 만드는 것이다.
중도절단과 관련하여 생존분석의 기법을 “시간”과 관련이 없는 다른 분야에도 적용할 수 있다. 가령 사람들의 체중을 모델링하려는데, 가령 체중계가 200kg 이상의 체중은 측정할 수 없다고 해보자. 그런 경우 해당 숫자를 초과하는 모든 체중은 중도절단되는 셈이므로 이 장에 제시된 생존분석 기법을 그런 데이터세트 분석에도 사용할 수 있다.
중도절단 데이터 사례
아래 그림 17.1은 생존분석 데이터의 특징을 잘 보여준다. 실제 연구가 수행된 데이터로서 먼저 왼쪽 그림 (a)를 보면, 88명의 환자들이 언제 뇌종양 진단을 받았고, 언제 사망하거나 또는 연구에서 빠졌는지가 나와있다. 연구에 첫 번째로 포함된 환자가 그림에서 가장 왼쪽 첫 번째 빨간색 수직선으로 표시돼있다. 이 환자는 2004년 7월 30일 뇌종양 진단을 받았는데, 수직선 길이가 아주 짧은 것은 진단후 얼마 지나지 않아 사망한 것을 의미한다. 그림에서 빨간색은 사망을 의미하고, 파란색은 중도절단을 의미한다. 중도절단의 경우에는 일차적으로 연구가 종료된 시점까지 생존한 환자가 있고, 그밖에도 연구 종료 이전에 다양한 이유로 연구에서 배제된 환자들도 있다. 가령 환자가 증상이 심해져서 추가적인 조치를 받기 위해 연구에서 빠진다거나, 또는 중간에 스스로 퇴원을 한다거나, 또는 뇌종양과 전혀 관련되지 않은 이유(가령 교통사고)로 사망하는 등 다양한 경우가 있을 수 있다.
아래 그림 (a)에서 세 번째 환자까지는 중도절단되지 않은 환자들이고, 네 번째 환자는 중도절단된 경우(파란색으로 표시)다. 이 네 번째 환자의 경우 연구가 종료된 2012년 5월 경까지 사망하지 않고 생존 상태였다는 것만 알 수 있을 뿐, 언제 사망했는지는 나와 있지 않다. 즉, 1-3번 환자까지는 뇌종양 진단 이후 생존시간(즉 사망까지의 시간)이 기록돼있는 데 반해, 4번 환자의 경우에는 사망까지의 시간이 기록돼있는 것이 아니라 뇌종양 진단 후 연구가 종료된 시점까지의 시간이 기록돼있는 것이다. 이런 점에서 1-3번 환자에 대해 기록된 시간(즉, 빨간색 선의 길이)과 4번 환자에 대해 기록된 시간(즉, 파란색 선의 길이)은 서로 성격이 다르다. 요컨대, 이 데이터세트에는 모든 환자들에 대해 time이 기록돼있는데, 사망 환자의 경우에는 그것이 생존시간을 의미하지만, 중도절단 환자의 경우에는 중도탈락 또는 연구종료까지의 시간을 의미한다.
그림 17.1의 오른쪽 그림 (b)를 보면, time 변수를 히스토그램으로 그려놓은 것이다. time이 1년 이내인 경우가 20% 가량이고, 1년보다 크고 2년보다 작은 경우가 12% 가량인 것을 알 수 있다. 그런데 바로 위에서 설명했듯이, 이 그림을 보고 “뇌종양 진단후 1년 이내 사망 확률이 20%이고, 2년 이내 사망 확률이 32% 수준”이라고 해석하면, 그것은 크게 잘못된 것이다. 왜냐하면 time 변수가 사망시간뿐만 아니라 중도절단시간까지 포함하고 있기 때문이다. 요컨대, 생존분석에서는 중도절단과 관련된 부분을 잘 감안하여 생존확률을 추정해야 한다는 것을 의미한다.
그림 17.1. 생존분석 데이터
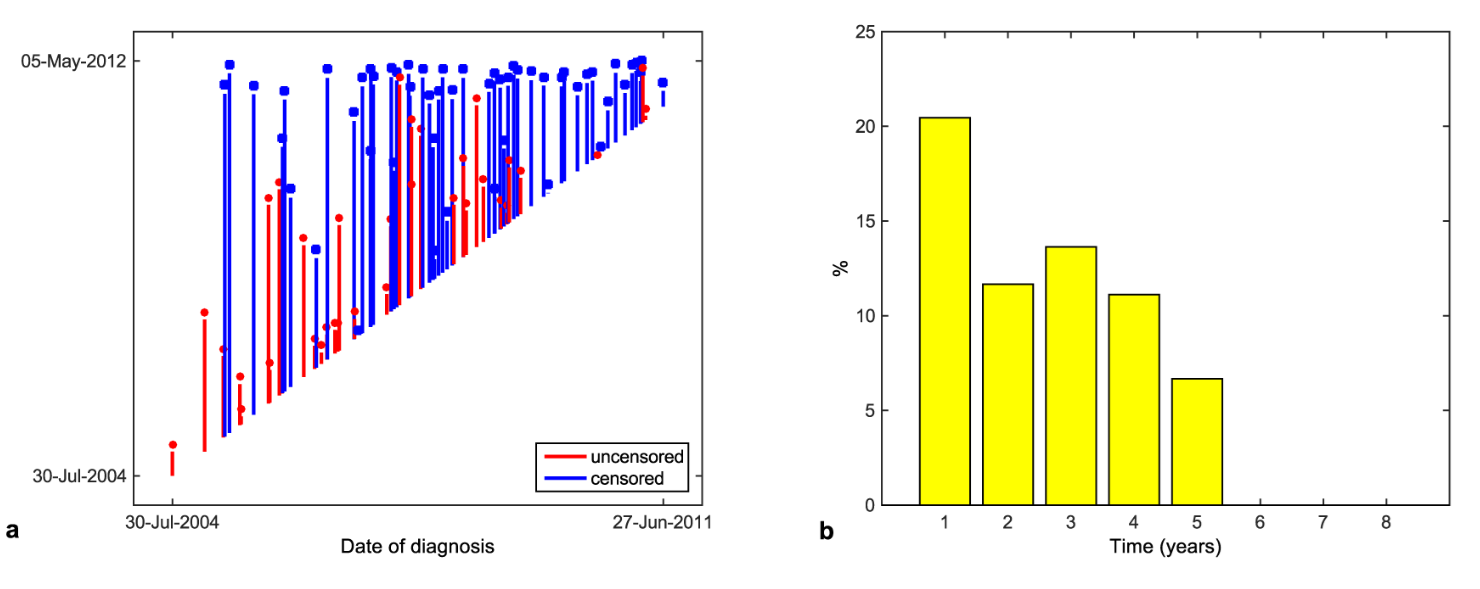
그림 출처: Selingerová et al. (2016)
생존분석 일반화
이상에서 설명한 것을 일반화시켜서 정리해보자. 우리는 각 개체별로(여기에서 개체는 환자를 생각하면 되지만 데이터에 따라서는 기계, 유저, 구독자 등이 될 수도 있음) 어떤 관측된 시간을 갖고 있는데, 어떤 개체의 경우에는 생존시간(survival time) \(T\)이지만, 또 다른 개체에 대해서는 생존시간이 아니라 중도절단시간(censoring time) \(C\)이다. 생존시간은 주어진 관심 사건이 발생하는 시간으로서 실패시간(failure time) 또는 사건시간(event time)이라고도 한다. 정확히 말하면 실패 또는 사건이 발생하는 데까지 걸린 시간이 될 것이다. 예를 들어 환자가 사망하거나 고객이 구독을 취소하는 데 걸린 시간이다. 이에 반해 중도절단시간은 중도절단이 발생하는 데까지 걸린 시간으로서 예를 들어 환자가 연구에서 탈락하거나 연구가 종료되는 데까지 걸린 시간이다.
각 개체에 대해 관측된 시간 변수를 \(Y\)로 표기하면, 이것은 생존시간 \(T\)나 중도절단시간 \(C\) 중 하나다. \(Y\)와 \((T, C)\)의 관계를 식으로 표현할 수 있는데, 그것은 다음과 같다.
먼저 중도절단시간(\(C\))이 관측된 개체를 생각해보면, 해당 개체의 (관측되지 않은) 생존시간(\(T\))은 반드시 \(C\)보다는 클 것이다. 중도절단이 관측됐다는 것 자체가 (사망) 사건이 발생하지 않았다는 것을 의미하기 때문이다. 즉, 중도절단시간이 관측된 개체의 경우, 관측된 시간 \(Y\)는 \(T\)와 \(C\) 중에서 값이 더 작은 \(C\)이다. 따라서 아래와 같이 표현할 수 있다.
위의 관계는 생존시간(\(T\))이 관측된 개체에 대해서도 성립한다. 왜냐하면 생존시간이 관측됐다는 것 자체가 중도절단이 발생하기 전에 (사망) 사건이 발생했다는 것을 의미하기 때문이다. 즉 생존 개체의 경우에도 \(T\)와 \(C\) 중에서 값이 더 작은 \(T\)가 관측된 것이다. 요컨대, 중도절단 전에 사건이 발생하면(즉, \(T \le C\)) 생존시간 \(T\)가 관측되고, 사건이 발생하기 전에 중도절단이 발생하면(즉, \(T>C\)), 중도절단시간이 관측된다. 이와 관련된 상태 지표(status indicator) \(\delta\)를 다음과 같이 정의하기로 하자.
식으로 표현하다보니 약간 복잡해 보이지만, \(\delta\)의 의미는 아주 간단하다. 즉, \(\delta = 1\)이면 (사망) 사건이 발생한 것(즉, 생존시간이 관측된 것)을 의미하고, \(\delta = 0\)이면 사건이 발생하지 않은 것(즉, 중도절단시간이 관측된 것)을 의미한다. 즉, \(\delta\)는 사건 발생 여부를 구분하는 더미변수다.
이제 \(n\)개의 \((Y, \delta)\), 즉 \((y_1, \delta_1), . . . , (y_n, \delta_n)\)을 관측했다고 가정하자. 아래 그림 17.2는 \(n = 4\)명의 환자를 1년 동안 관측한 가상의 예를 보여준다. 환자 1과 3의 경우 사건(예: 사망 또는 질병재발)이 발생했다(즉 \(\delta_1=\delta_3=1\)). 따라서 관측된 시간은 생존시간 \(T\)에 해당한다. 이것을 \(y_1=t_1\), \(y_3=t_3\)로 표현할 수 있다.(생존시간 변수 \(T\)의 다양한 값 중의 하나라는 것을 표현하기 위해 소문자 \(t\)를 사용했다.) 환자 2는 연구가 끝났을 때까지 생존했고, 환자 4는 연구에서 중도이탈했다 (즉 \(\delta_2=\delta_4=0\)). 이들 환자 2와 4에 대해서는 중도절단시간 \(C = c_i\)가 관측된 것이다. 즉, \(y_2=c_2\), \(y_4=c_4\)로 표현할 수 있다.
그림 17.2. 중도절단된 생존 데이터 그림. 환자 1과 3은 사건이 관측됐고, 환자 2와 4는 사건이 관측되지 않았다. 환자 2는 연구가 끝났을 때까지 생존했고, 환자 4는 연구에서 이탈했다.
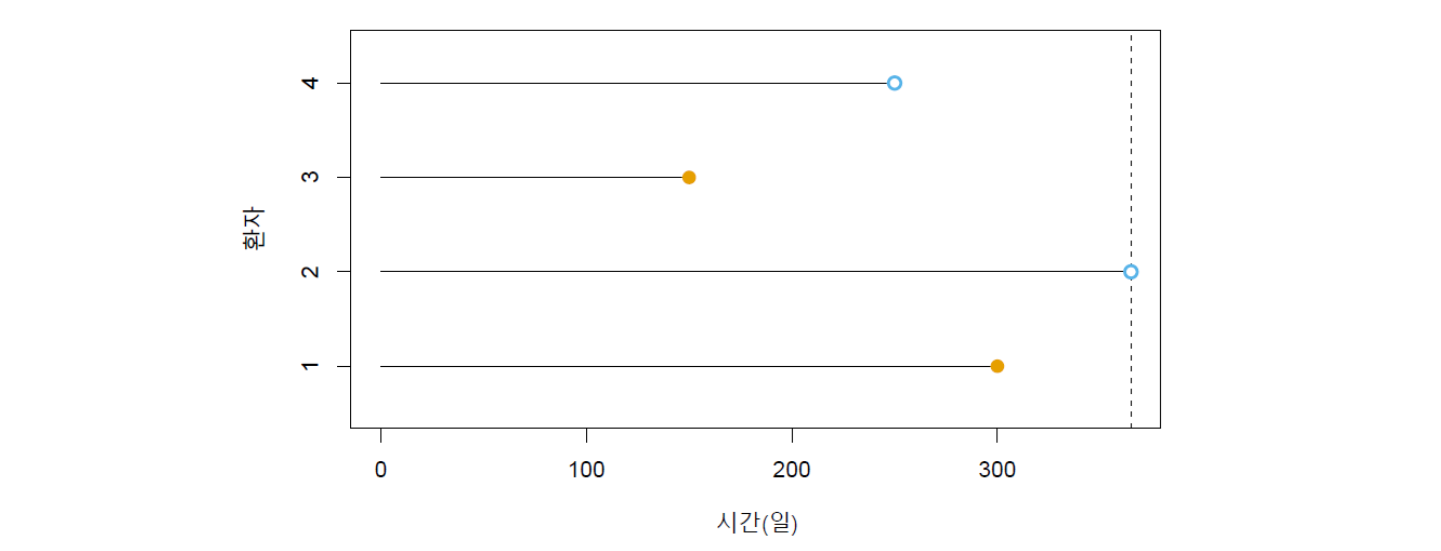
그림 출처: ISLP, FIGURE 11.1
17.3 중도절단에 대한 가정#
우리는 중도절단 메커니즘이 독립적(independent)이라고 가정한다. 즉 생존시간 \(T\)는 중도절단시간 \(C\)와 무관하다고 가정하는 것이다. 생존시간이 중도절단시간과 무관하지 않은 예를 들면 다음과 같다. 예를 들어, 어떤 암에 대해 연구하는 과정에서 많은 환자들이 중도이탈했는데 그 이유가 병세가 심해졌기 때문(그래서 가령 추가적인 치료를 받아야 했기 때문)이라고 해보자. 즉 중도절단이 많은 이유가 사실상 높은 사망 가능성을 의미하는 것이다. 이 경우 환자가 중도이탈한 이유를 전혀 감안하지 않고 분석을 할 경우, 실제의 생존시간을 과대평가할 가능성이 있다. 반대로 많은 환자들이 병세가 아주 호전돼 연구 중간에 퇴원함으로써 중도이탈이 많아진 경우에는 앞의 예와 반대를 의미한다. 즉, 중도이탈한 이유를 감안하지 않고 분석을 할 경우 이번에는 실제의 생존시간을 과소평가할 가능성이 있다. 또 다른 예로 가령 증상이 심해졌을 때, 남성이 여성보다 연구에서 이탈할 가능성이 더 높다고 가정해보자. 그런 상황에서 남녀의 성향 차이를 전혀 고려하지 않고 분석할 경우 남성의 생존시간을 여성보다 과대평가할 가능성이 있다.
이런 예들은 독립적 중도절단의 가정을 위배하는 것들이다. 일반적으로 중도절단 메커니즘이 독립적인지 여부는 데이터 자체만으로는 확인할 수 없다. 대신 독립적 중도절단 가정이 합리적인지 여부를 판단하기 위해 데이터 수집 프로세스를 신중하게 살펴봐야 한다. 여기서는 중도이탈의 예를 들었지만, 중도절단에는 중도이탈뿐만 아니라 연구가 끝날 때까지 생존한(즉, 사건이 발생하지 않은) 경우도 포함된다. 어쨌든 우리는 이 장의 나머지 부분에서는 중도절단 메커니즘이 독립적이라고 가정한다.
이 장에서는 \(T \ge Y\)일 때 발생하는 오른쪽 중도절단(right censoring)에 초점을 맞춘다.(이것은 식 17.1에서 보듯이 \(T \ge C\)를 의미함.) 그러나 다른 유형의 중도절단도 가능하다. 예를 들어 왼쪽 중도절단(left censoring)도 있을 수 있는데, 이것은 실제 사건시간 \(T\)가 관측시간 \(Y\)보다 작거나 같은 경우이다. 예를 들어, 산모들의 임신 기간에 대한 연구를 생각해보자. 이 연구에서 만약 임신 250일이 지난 산모들에 대해서만 정확한 출산 시점을 기록했다고 해보자. 이 경우 임신 250일 이전에 출산을 한 산모는 임신 기간은 250일 미만이지만 정확한 시점은 조사되지 않았기 때문에 왼쪽 중도절단에 해당한다.
구간 중도절단(interval censoring)은 사건의 정확한 발생시간을 알지는 못하지만 특정 구간에 속하는 것은 알고 있는 상황을 말한다. 예를 들어, 환자들에게 특정 사건이 발생했는지를 일주일에 한 번씩 조사하는 경우가 여기에 해당한다.
이 장에서는 오른쪽 중도절단에 초점을 맞추기로 한다. 왼쪽 중도절단 및 구간 중도절단은 이 장에 제시된 방법을 약간 변형시켜 분석할 수 있다.
17.4 카플란-마이어 생존곡선 추정#
생존분석의 핵심 요소는 생존시간이다. 다양한 방식으로 생존시간을 분석하지만, 가장 기초적인 분석은 생존시간의 분포를 알아보는 것이다. 가령 어떤 암 치료를 받은 환자들의 생존시간 데이터가 주어진 경우, 암 치료를 받고 1년 이상 생존할 확률, 2년 이상 생존할 확률, 이런 것들을 추정하는 것이다. 마치 소득 데이터가 있을 때, 사람들의 소득 분포를 그려보는 것과 마찬가지다. 소득분포의 경우 대개 히스토그램(histogram)을 그린다. 월 소득이 50만 원 이하인 그룹이 몇 퍼센트고, 50만 원에서 100만 원 그룹이 몇 퍼센트고, 이런 식으로 소위 경험적 분포함수(empirical distribution function)를 그리는 것이다. 마찬가지로 생존분석에서도 생존시간의 분포를 추정할 수 있다. 그것을 생존곡선(survival curve) 또는 생존함수(survival function)라고 한다.
카플란-마이어 추정#
생존곡선을 구하는 대표적 기법이 카플란-마이어(Kaplan-Meier) 추정이다. 간단한 예시로 어떤 암 치료를 받은 5명 환자의 생존시간을 100주 동안 관찰했는데, 관측된 시간이 (오름차순으로 정렬했을 때) 50, 60, 70, 80, 90주라고 해보자.
환자 |
생존시간(주) |
|---|---|
1 |
50 |
2 |
60 |
3 |
70 |
4 |
80 |
5 |
90 |
이해를 돕기 위해 먼저 중도절단이 없는 경우를 생각해보자. 즉 5개의 관측시간이 모두 다 생존시간이라 해보자. 이런 경우라면, 생존확률 계산은 매우 간단하다.
\(S(50)\): 50주 시점에 5명 중 총 1명이 사망하고 4명이 생존했기 때문에 50주 이상 생존확률은 4/5(80%).
\(S(60)\): 60주 시점에 5명 중 총 2명이 사망하고 3명이 생존했기 때문에 60주 이상 생존확률은 3/5(60%).
\(S(70)\): 70주 시점에 5명 중 총 3명이 사망하고 2명이 생존했기 때문에 70주 이상 생존확률은 2/5(40%).
\(S(80)\): 80주 시점에 5명 중 총 4명이 사망하고 1명이 생존했기 때문에 80주 이상 생존확률은 1/5(20%).
\(S(90)\): 90주 시점에 5명 중 총 5명이 사망하고 0명이 생존했기 때문에 90주 이상 생존확률은 0/5(0%).
이처럼 중도절단 관측이 없는 경우에는 카플란-마이어 추정에 대해 새롭게 배울 필요도 없이 상식만으로도 생존확률과 생존곡선을 구할 수 있다. 다음은 5명 환자의 각 사망시점에서 계산한 생존확률을 식으로 표현한 것이다.
\(S(50) = \frac{4}{5} = 0.8\)
\(S(60) = \frac{4}{5} \times \frac{3}{4} = 0.6\)
\(S(70) = \frac{4}{5} \times \frac{3}{4} \times \frac{2}{3} = 0.4\)
\(S(80) = \frac{4}{5} \times \frac{3}{4} \times \frac{2}{3} \times \frac{1}{2} = 0.2\)
\(S(90) = \frac{4}{5} \times \frac{3}{4} \times \frac{2}{3} \times \frac{1}{2} \times \frac{0}{1} = 0\)
가령 \(S(60)\), 즉 60주 이상 생존확률은 앞에서도 설명했듯이 50주와 60주에 각 1명씩 사망하여 5명 중 3명만 남았기 때문에 이 확률은 \(3/5=0.6\)이다. 이것을 위에서 분수를 사용해 \(4/5 \times 3/4\)와 같은 식으로 좀 더 복잡하게 적어놓은 이유는 카플란-마이어 추정을 일반화하기 위한 것이다. \(S(60)\) 계산에 나와있는 \(4/5 \times 3/4\)의 의미는 대략적으로 이렇다. 즉, “60주 이상 생존”한다는 것은 “60주 직전까지 생존한 환자 중에서 60주 이상도 생존”한 경우다. 따라서 그 확률은 60주 직전까지 생존할 확률(이것은 50주 이상 생존할 확률과 동일한 것으로 \(4/5\)임), 그것에다 60주 직전까지 생존한 환자(50주에 1명이 사망했기 때문에 대상 환자가 이제는 5명이 아니라 4명으로 바뀜) 중에서 60주 이상 생존할 확률(즉 \(3/4\))을 곱한 것이다. \(S(70)\), \(S(80)\), \(S(90)\)도 마찬가지 방식으로 표현한 것이다.
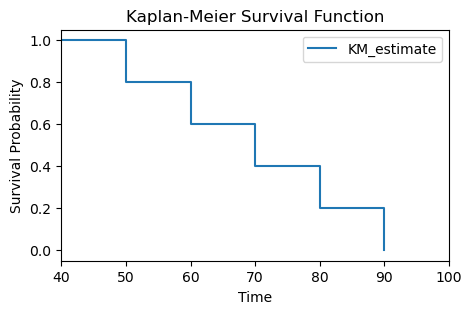
다음은 위의 간단한 예에 대해 파이썬 lifelines 모듈을 사용하여 카플란-마이어 생존곡선을 추정한 것이다. ChatGPT에게 예제 코드를 받아서 위의 숫자들을 집어넣은 것이다. 아래 예에서 event라는 이름의 변수가 앞에서 설명한 상태 지표 \(\delta\)에 해당하는 것으로서 사망 더미변수이다.
ChatGPT Q&A#
Survival model에서 Kaplan-Meier 생존함수 추정 예제 코드를 만들어줘. 관측이 5개인 경우.
# 처음 한 번 설치해야 함
# %pip install lifelines
import numpy as np
import pandas as pd
from lifelines import KaplanMeierFitter
import matplotlib.pyplot as plt
data = pd.DataFrame({
'time': [50, 60, 70, 80, 90], # 생존 시간
'event': [1, 1, 1, 1, 1] # 사건 여부 (1: 사건 발생, 0: 사건 미발생)
})
# Kaplan-Meier 생존 함수 추정
kmf = KaplanMeierFitter()
kmf.fit(durations=data['time'], event_observed=data['event'])
# 생존 확률 표 출력
survival_table = kmf.survival_function_.reset_index()
survival_table.columns = ['Time', 'S(t)']
# time을 기준으로 data와 survival_table 합치기
result = pd.merge(data, survival_table, left_on='time', right_on='Time')
# 불필요한 열 제거
result = result.drop('Time', axis=1)
# 결과 출력
print(result)
# 새로운 그림 생성 및 크기 지정
plt.figure(figsize=(5, 3))
# 생존 함수 그래프 출력 (신뢰구간 표시 안 함)
kmf.plot_survival_function(ci_show=False)
plt.title('Kaplan-Meier Survival Function')
plt.xlabel('Time')
plt.ylabel('Survival Probability')
# x-축 범위 설정
plt.xlim(40, 100)
plt.show()
time event S(t)
0 50 1 0.8
1 60 1 0.6
2 70 1 0.4
3 80 1 0.2
4 90 1 0.0
중도절단이 있는 경우#
관측시간에 중도절단시간이 포함된 경우 생존확률을 구할 때 좀 더 생각을 해야 한다. 앞에서와 비슷한 예시로 어떤 암 치료를 받은 5명의 환자를 100주 동안 관찰을 했는데, 관측된 시간이 (오름차순으로 정렬했을 때) 50, 60, 75, 80, 100주라고 해보자. 단, 이 중 75주와 100주는 중도절단시간이라고 해보자.
환자 |
관측시간(주) |
상태 |
|---|---|---|
1 |
50 |
사망 |
2 |
60 |
사망 |
3 |
75 |
중도절단 |
4 |
80 |
사망 |
5 |
100 |
중도절단 |
즉, 세 번째 환자(75주)는 연구 대상에서 중도이탈했으며, 다섯 번째 환자(100주)는 연구가 끝나는 시점까지 사망사건이 발생하지 않은 경우다. 이 예에 대해 카플란-마이어 방식으로 생존확률을 계산하면 다음과 같다.
\(S(50) = \frac{4}{5} = 0.8\)
\(S(60) = \frac{4}{5} \times \frac{3}{4} = 0.6\)
\(S(80) = \frac{4}{5} \times \frac{3}{4} \times \frac{1}{2}= 0.3\)
일단 \(S(50)\)과 \(S(60)\)은 앞의 중도절단이 전혀 없는 경우와 동일하다. 이는 50주와 60주가 모두 생존시간(즉, 사망시간)을 의미하기 때문에 생존확률 계산이 앞의 중도절단이 없는 경우와 달라질 이유가 없다.
다음으로 \(S(75)\)와 \(S(100)\)은 생존확률을 계산하지 않았다. 정확히 말하면 70주와 100주 시점에서는 사망사건이 발생하지 않았기 때문에 생존확률이 바뀔 이유가 없다. 즉, \(S(70)\)은 60주 이후 사망사건이 발생하지 않았기 때문에 \(S(60)\)과 동일하고, \(S(100)\)은 80주 이후 사망사건이 발생하지 않았기 때문에 \(S(80)\)과 동일하다.
결국 \(S(80)\)만 따져보면 되는데, 만약 앞의 중도이탈 환자가 전혀 없는 경우와 동일한 방식으로 생각한다면, 전체 5명 중 80주 이상 생존한 환자가 1명이기 때문에 \(S(80)\)을 0.2(즉 20%)로 생각할 수 있다. 그러나 이것은 타당하지 않다. 왜냐하면 1명만이 80주 이상 생존한 것은 맞는데, 그렇다고 나머지 4명 모두가 80주 이전에 사망한 것은 아니기 때문이다. 즉 75주에 1명이 중도이탈했고, 이 환자가 80주 시점에서 이미 사망했는지(아니면 아직 생존하고 있는지) 모르는 상태에서 80주 이상 생존확률을 20%로 보는 것은 생존 가능성을 과소평가하는 것이기 때문이다. 결국 중도이탈 환자의 존재가 생존확률 계산을 간단하지 않게 만드는 것이다.
카플란-마이어는 생존확률을 다음과 같이 추정하는 것이 타당하다고 본다. 즉, 위에 나와 있는 곱셈 \(S(80) = 4/5 \times 3/4 \times 1/2\)은 다음을 의미한다. “80주 이상 생존”은 “80주 직전까지 생존한 환자 중에서 80주 이상까지도 생존”한 경우이다. 따라서 그 확률은 80주 직전까지 생존할 확률(이것은 직전 사망사건이 발생한 60주를 넘어 생존할 확률이기 때문에 \(S(60) = 4/5 \times 3/4 \)에 해당함), 그것에다 80주 직전까지 생존한 환자(75주에 1명이 이탈했기 때문에 대상 환자가 3명이 아니라 2명임) 중에서 80주 이상 생존할 확률(즉 \(1/2\))을 곱한 것이다. 이렇게 계산하면 30%가 나오는데, 이것은 앞에서 중도이탈 환자를 고려하지 않고 계산했던 20%보다 높다.
만약 이 연구에서 중도이탈 환자들 2명(즉 75주와 100주 관측)을 빼버리고, 나머지 3명만 가지고 생존확률을 구할 경우, 80주 이상 생존 환자가 한 명도 없기 때문에 생존확률이 0이 되고, 이것 역시 카플란-마이어 추정과 비교하면 생존확률을 매우 편향되게 추정한 것임을 알 수 있다.
위의 숫자 예를 코딩으로 추정
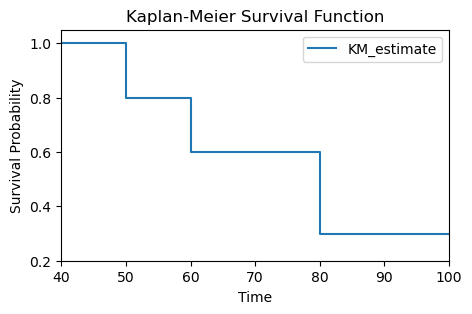
이상의 예에 대해 파이썬 코딩으로 카플란-마이어 생존곡선을 추정한 것이 아래 나와 있다.
import numpy as np
import pandas as pd
from lifelines import KaplanMeierFitter
import matplotlib.pyplot as plt
data = pd.DataFrame({
'time': [50, 60, 75, 80, 100], # 생존 시간
'event': [1, 1, 0, 1, 0] # 사건 여부 (1: 사건 발생, 0: 사건 미발생)
})
# Kaplan-Meier 생존 함수 추정
kmf = KaplanMeierFitter()
kmf.fit(durations=data['time'], event_observed=data['event'])
# 생존 확률 표 출력
survival_table = kmf.survival_function_.reset_index()
survival_table.columns = ['Time', 'S(t)']
# time을 기준으로 data와 survival_table 합치기
result = pd.merge(data, survival_table, left_on='time', right_on='Time')
# 불필요한 열 제거
result = result.drop('Time', axis=1)
# 결과 출력
print(result)
# 새로운 그림 생성 및 크기 지정
plt.figure(figsize=(5, 3))
# 생존 함수 그래프 출력 (신뢰구간 표시 안 함)
kmf.plot_survival_function(ci_show=False)
plt.title('Kaplan-Meier Survival Function')
plt.xlabel('Time')
plt.ylabel('Survival Probability')
# x-축 범위 설정
plt.xlim(40, 100)
plt.ylim(0.2, 1.05)
plt.show()
time event S(t)
0 50 1 0.8
1 60 1 0.6
2 75 0 0.6
3 80 1 0.3
4 100 0 0.3
이론적 설명#
생존곡선(survival curve) 또는 생존함수(survival function)는 다음과 같이 정의된다.
즉, 생존함수 \(S(t)\)는 생존시간(\(T\))이 어떤 주어진 \(t\)보다 더 클 확률이다. 1년 이상 생존확률보다 2년 이상 생존확률이 당연히 작을 것이기 때문에 생존함수는 감소함수(decreasing function)다.
어떤 관측시간이 있을 때, 카플란-마이어 \(S(t)\) 추정은 다음과 같다. 관측시간에 생존시간과 중도절단시간이 섞여 있는데, 그 중에서 생존시간만 골라내 그것을 오름차순으로 정렬한 것을 \(d_1 < d_2 < · · · < d_K\)라고 하자. 이들 각각의 \(d_k\)를 사망 시점이라 부를 수도 있다.
한편 \(q_k\)는 사망시점이 \(d_k\)인 환자의 수, 즉 \(d_k\)에 몇 명이 사망했는지를 나타낸다고 하자. 그리고 \(r_k\)는 \(d_k\)까지는 살아있고 연구에도 들어있는 환자의 숫자를 나타낸다고 하자. 따라서 \(r_k\)는 생존시간(또는 사망시점)이 \(d_k\)보다 클 확률을 구할 때 분모의 크기가 될 것이다. 우리는 이 \(r_k\)에 속하는 환자를 위기(at risk) 환자라고 부르기로 한다. 아직 살아있고 연구에도 들어있는 환자는 언제든, 또는 언젠가는 사망사건이 발생할 수 있기 때문이다. 어떤 주어진 시점에 전체 위기 환자의 집합을 위기집합(risk set)이라고 부르기로 한다.
전체확률의 법칙(law of total probability)을 생각해보자. 두 사건 \(A\) 및 \(B\)가 있고, \(B^c\)는 사건 \(B\)의 여집합, 즉 \(B\)가 성립하지 않는 사건이라 할 때, 전체확률의 법칙에 따르면 \(\Pr(A) = \Pr(A\mid B) \Pr(B) + \Pr(A\mid B^c) \Pr(B^c)\)이다. 이를 생존함수 \(\Pr(T > d_{k})\)에 적용하면 다음과 같다.
여기서 \(d_{k−1} < d_{k}\)이기 때문에 \(\Pr(T > d_{k} \mid T ≤ d_{k−1}) = 0\)이 된다.즉, 환자가 \(d_{k−1}\)까지 생존하지 못한 경우 \(d_k\) 이후에 생존하는 것은 불가능하다. 그러므로 위 식은 다음과 같이 된다.
여기서 맨 오른쪽 끝의 \(\Pr(T > d_{k−1})\)은 \(S(d_{k−1})\)이므로 위 식은 다음과 같이 된다.
결국 이것은 다음을 의미한다.
여기서 우변에 있는 각 항에 추정치를 집어넣으려고 하는데, 다음 추정치를 사용하는 것이 타당하다.
여기서 \(T > d_{j−1}\)의 조건은 환자가 (\(d_{j-1}\)부터) \(d_{j}\)까지 생존해있고 연구에도 들어있는 것을 의미하기 때문에 \(d_{j}\)에 위기집합에 속해있는 것을 의미한다. 따라서 \({\Pr}(T > d_j \mid T > d_{j −1})\) 확률은 \(d_{j}\)에 위기집합에 속한 환자 중 생존시간이 \(d_j\)보다 클 확률이기 때문에 \(r_j\)를 분모로 하고 \(d_j\)에 살아있는 환자, 즉 \(r_j − q_j\)를 분자로 하는 비율로 추정하는 것이 타당하다. 이렇게 해서 구한 다음의 생존곡선이 카플란-마이어 추정이다.
우리는 \(d_k\)와 \(d_{k+1}\) 사이의 시간 \(t\)에 대해서는 수평, 즉 \(\hat{S}(t) = \hat{S}(d_k)\)로 설정한다. 결과적으로 카플란-마이어 생존곡선은 계단 모양을 갖는다. 식 17.3에서 보는 것처럼 카플란-마이어 추정은 곱하기를 연속적으로 해나가는 방식이라서 곱(의)극한추정량(product-limit estimator)이라고 부른다. 이렇게 카플란-마이어 추정처럼 최초 시점에서 시작하여 시간의 흐름에 따라 순차적(sequential)인 방식으로 추정해나가는 것은 중도절단 관측이 지닌 정보를 포함시키려는 것으로서 카플란-마이어 생존함수 추정뿐만 아니라 생존분석 분야의 다른 분석(가령 아래에서 다루는 로그순위 검정)에서도 사용되는 기법이다.
BrainCancer 데이터세트#
사용할 데이터세트는 정위 방사선(stereotactic radiation) 방법으로 치료를 받은 원발성 뇌종양(primary brain tumors) 환자의 생존시간과 관련된 것이다.(이 데이터세트는 다음 논문에 나온다. Selingerová et al. (2016) Survival of patients with primary brain tumors: Comparison of two statistical approaches. PLoS One, 11(2):e0148733.) 88명의 환자 중 연구가 끝날 때까지 생존한 환자는 53명이다.
관측 환자
원발성 뇌종양을 가진 환자들은 브루노(Brno)의 Masaryk Memorial Cancer Institute에서 치료를 받았다. 정위 방사선 치료를 받은 환자들은 방사선종양학 클리닉과 신경과 정신과에서 모니터링되었으며 정기적으로 자기공명 이미징 검사를 받았다.
연구는 2004년 7월 30일 첫 번째 환자부터 시작되었으며, 2011년 6월 27일에 마지막 환자가 포함되었고, 2012년 5월 5일에 연구가 완료됐다. 총 100명의 의료 기록 중 88명의 환자가 선정됐다. 11세 미만의 환자, 두뇌방사선치료, 총종양 부피가 80\(\text{cm}^3\) 이상인 환자는 제외됐다.
환자들의 특성
예측변수는 gtv(총종양 부피, 단위: \(\text{cm}^3\)), sex(female, male), diagnosis(진단명: 뇌막종, LG 뇌종양, HG 뇌종양, 기타), loc(종양 위치: 두뇌하, 두뇌상), ki(Karnofsky 지수), stereo(정위적 방법: 정위 방사선 수술(SRS), 분할 정위 방사선 요법(SRT)) 등이다.
뇌막종, LG 뇌종양, HG 뇌종양은 뇌세포 방사선치료를 받은 환자들의 가장 일반적인 진단이며, 그밖의 다른 진단은 비중이 낮아 하나의 그룹으로 합쳐졌다. 종양 위치는 종양의 유형을 결정하는 데 유용할 수 있다. 이 연구에서 환자들은 성인이었기 때문에 소뇌천막위(두뇌상)의 종양 위치가 우세했다. 소뇌천막 아래(두뇌하)의 위치는 어린이 환자에서 더 자주 나타난다. 환자의 전반적인 상태를 특성화하는 Karnofsky 지수는 100%에서 0%까지 범위가 있으며, 100%는 완전한 건강을 나타내고 0%는 사망을 나타낸다. Karnofsky 지수가 80% 이상이면 일상 활동이나 작업을 수행할 수 있는 환자를 의미한다. 이상값(outlier)으로 인해 gtv는 96번째 백분위수에서 윈저화(winsorized)되었다(3명의 환자). SRS를 받은 23명 환자의 중위값 용량은 18 Gy(범위 14-40 Gy)였으며, SRT를 받은 65명의 환자는 중위값 용량이 28 Gy(범위 12-58 Gy)의 방사선 치료를 받았다.
from matplotlib.pyplot import subplots
import numpy as np
import pandas as pd
from lifelines import KaplanMeierFitter, CoxPHFitter
from lifelines.statistics import logrank_test, multivariate_logrank_test
데이터 로딩
ISLP에서 제공하는 BrainCancer.csv 데이터를 불러들인다.
df = pd.read_csv('../Data/BrainCancer.csv')
df.drop('Unnamed: 0', axis=1, inplace=True)
df.head()
| sex | diagnosis | loc | ki | gtv | stereo | status | time | |
|---|---|---|---|---|---|---|---|---|
| 0 | Female | Meningioma | Infratentorial | 90 | 6.11 | SRS | 0 | 57.64 |
| 1 | Male | HG glioma | Supratentorial | 90 | 19.35 | SRT | 1 | 8.98 |
| 2 | Female | Meningioma | Infratentorial | 70 | 7.95 | SRS | 0 | 26.46 |
| 3 | Female | LG glioma | Supratentorial | 80 | 7.61 | SRT | 1 | 47.80 |
| 4 | Male | HG glioma | Supratentorial | 90 | 5.06 | SRT | 1 | 6.30 |
ISLP 모듈
ISLP에서 제공하는 ISLP 모듈과 함수를 이용하면 ISLP의 여러 데이터세트를 좀 더 간단히 불러들일 수 있다.
참고: 이 책의 앞 장에서도 아래와 같은 방식으로 ISLP의 여러 데이터세트를 (사실상 인터넷을 통해) 좀 더 간단히 로딩할 수 있는데, 우리는 의도적으로 그와 같은 방식을 사용하지 않았다. 그 대신 ISLP 데이터 사이트에서 예제 데이터세트를 직접 다운로드 받아 자신의 컴퓨터에 저장한 다음, 그것을 불러들이는 방식을 연습했다. 이런 방식에 익숙해져야만 ISLP 제공 데이터가 아닌 다른 데이터세트도 잘 로딩시킬 수 있기 때문이다.
# 처음 한 번 설치
# %pip install ISLP
from ISLP import load_data
BrainCancer = load_data('BrainCancer')
BrainCancer.head()
| sex | diagnosis | loc | ki | gtv | stereo | status | time | |
|---|---|---|---|---|---|---|---|---|
| 0 | Female | Meningioma | Infratentorial | 90 | 6.11 | SRS | 0 | 57.64 |
| 1 | Male | HG glioma | Supratentorial | 90 | 19.35 | SRT | 1 | 8.98 |
| 2 | Female | Meningioma | Infratentorial | 70 | 7.95 | SRS | 0 | 26.46 |
| 3 | Female | LG glioma | Supratentorial | 80 | 7.61 | SRT | 1 | 47.80 |
| 4 | Male | HG glioma | Supratentorial | 90 | 5.06 | SRT | 1 | 6.30 |
BrainCancer.columns
Index(['sex', 'diagnosis', 'loc', 'ki', 'gtv', 'stereo', 'status', 'time'], dtype='object')
BrainCancer 데이터세트 변수
sex: 성별(Female, Male)diagnosis: 진단명(Meningioma, LG glioma, HG glioma, Other)loc: 종양 위치(Infratentorial, Supratentorial)ki: Karnofsky indexgtv: 총 종양 부피(단위: 세제곱 센티미터)stereo: 정위적 방법(SRS, SRT)status: 지표변수(1: 사건발생, 0: 중도절단)time: 관측시간
BrainCancer.dtypes
sex category
diagnosis category
loc category
ki int64
gtv float64
stereo category
status int64
time float64
dtype: object
BrainCancer['sex'].value_counts()
sex
Female 45
Male 43
Name: count, dtype: int64
BrainCancer['diagnosis'].value_counts()
diagnosis
Meningioma 42
HG glioma 22
Other 14
LG glioma 9
Name: count, dtype: int64
BrainCancer['status'].value_counts()
status
0 53
1 35
Name: count, dtype: int64
카플란-마이어 생존곡선
from lifelines import KaplanMeierFitter
# fit data into Kaplan Meier estimator
kmf = KaplanMeierFitter()
kmf.fit(durations=BrainCancer['time'], event_observed=BrainCancer['status'])
# plot survival curve
plt.figure(figsize=(5, 3))
kmf.plot(ci_show=True)
plt.ylim(0.2, 1.05)
plt.ylabel('Estimated Probability of Survival')
plt.xlabel('Months')
plt.title('Kaplan-Meier Survival Curve')
plt.show()
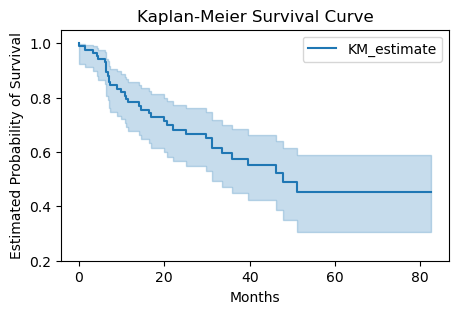
ChatGPT Q&A#
kmf.survival_function_at_times함수를 이용해 생존시간이 10, 20,…,70일 확률을 구해줘.
# Survival times of interest
times_of_interest = [10, 20, 30, 40, 50, 60, 70]
# Calculate survival probabilities at specified times
survival_probabilities = kmf.survival_function_at_times(times_of_interest)
# Display the results
result_df = pd.DataFrame({
'Time': times_of_interest,
'Survival Probability': survival_probabilities.values
})
print(result_df)
Time Survival Probability
0 10 0.820558
1 20 0.713191
2 30 0.650288
3 40 0.552476
4 50 0.489171
5 60 0.451543
6 70 0.451543
위 결과에서 보듯이 20개월 이상 카플란-마이어 생존확률 추정치는 71.3%이다. 가령 중도절단 관측을 고려하지 않고 전체 환자 88명 중 20개월 이상 생존자(48명)의 비율(54.5%; 아래 계산 참조)로 생존확률을 삼을 경우 제대로 된 추정이 아니다. 왜냐하면 20개월 이상 생존자에서 빠진 40명 중 사망자는 23명뿐이고 나머지 17명은 중도이탈 환자들이기 때문이다.
print("전체", len(BrainCancer), "명의 환자중, 20개월 넘게 생존한 환자는",
sum(BrainCancer['time']>20), "명으로서, 비율은",
round(sum(BrainCancer['time']>20)/len(BrainCancer)*100, 1), "%이다.")
전체 88 명의 환자중, 20개월 넘게 생존한 환자는 48 명으로서, 비율은 54.5 %이다.
print("20개월 전에 중도절단된 환자는",
round(len(BrainCancer[(BrainCancer['status']==0)
& (BrainCancer['time']<20)])), "명이다.")
20개월 전에 중도절단된 환자는 17 명이다.
17.5 로그순위 검정#
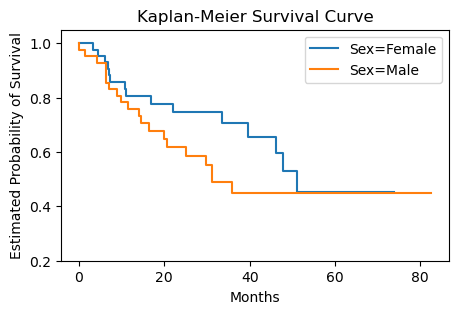
앞 절에서 BrainCancer 데이터의 생존곡선을 추정했다. 이번에는 남성과 여성의 생존곡선에 차이가 있는지를 검토한다.
우선 각 그룹별로 카플란-마이어 추정 생존곡선을 그린 것이 아래 나와 있다. 그림을 보면, 대략 50개월까지는 여성의 생존확률이 남성보다 조금 높지만 그 다음에는 두 곡선 모두 약 50% 수준으로 동일해지는 것을 알 수 있다. 이 결과에 대해 두 생존곡선이 동일한지 검정을 수행하려고 하는데, 그 대표적인 방법이 로그순위 검정(log-rank test)이다. 로그순위 검정은 Mantel-Haenszel 검정 또는 Cochran-Mantel-Haenszel 검정이라고도 한다.
fig, ax = subplots(figsize=(5,3))
by_sex = {}
for sex, df in BrainCancer.groupby('sex', observed=False):
by_sex[sex] = df
kmf_sex = kmf.fit(df['time'], df['status'])
kmf_sex.plot(label='Sex=%s' % sex, ax=ax, ci_show=False)
plt.ylim(0.2, 1.05)
plt.ylabel('Estimated Probability of Survival')
plt.xlabel('Months')
plt.title('Kaplan-Meier Survival Curve')
plt.show()
이론적 설명#
우선 다음과 같이 정의한다.
\(d_1 < d_2 < · · · < d_K\): 중도절단되지 않은 사망 환자의 각 사망시간(또는 사망시점)
\(r_k\): \(d_k\) 시점의 위기 환자 수
\(q_k\): \(d_k\) 시점의 사망 환자 수
\(r_{1k}\): \(d_k\) 시점 그룹 1의 위기 환자 수
\(r_{2k}\): \(d_k\) 시점 그룹 2의 위기 환자 수
\(q_{1k}\): \(d_k\) 시점 그룹 1의 사망 환자 수
\(q_{2k}\): \(d_k\) 시점 그룹 2의 사망 환자 수
위와 같이 정의하면, \(r_{1k} + r_{2k} = r_k\)와 \(q_{1k} + q_{2k} = q_k\)이 성립한다. 이제 각 사망 시점 \(d_k\)에 대해 표 17.1과 같은 표를 만든다. 사망시간이 겹치는 경우가 없다면(즉, 두 사람 이상이 동시에 사망하지 않는다면) \(q_{1k}\)와 \(q_{2k}\) 중 어느 하나는 1이고 다른 하나는 0이 될 것이다.
표 17.1. 그룹 1과 2의 사망 시점 \(d_k\) 위기 환자 및 사망 환자 수

표 출처: ISLP, TABLE 11.1
로그순위 검정통계량은 다음의 형태이다.
여기에서 \(X = \sum^K_{k=1} q_{1k}\)로서 사망 시점별 그룹 1의 사망 환자 수를 모두 합친 것이다. 각 사망 시점별로 두 그룹의 생존에 차이가 없다는 귀무가설 하에서 \(q_{1k}\)의 기대값은 다음과 같다.
중도절단 관측의 존재 때문에 기대값이 \(q_{k}\)가 아니라 위 식과 같이 되었다. 또한 \(q_{1k}\)의 분산은 다음과 같이 된다.
\(X = \sum^K_{k=1} q_{1k}\)의 분산을 계산함에 있어서 \(q_{11},..., q_{1k}\) 간에 상관성이 없다고 가정하면 다음과 같다.
이상의 결과를 다 합치면, 식 17.4의 로그순위 검정통계량은 다음과 같이 된다.
표본 크기가 크면 로그순위 검정통계량 \(W\)는 대략 표준정규 분포를 갖는다. 이것은 두 그룹의 생존곡선 간에 차이가 없다는 귀무가설에 대한 \(p\)-값을 계산하는 데 사용할 수 있다.
BrainCancer 데이터에서 여성과 남성의 생존시간을 비교하면 \(W = 1.44\)의 로그순위 검정통계량이 나온다. \(p\)-값이 0.23으로서 여성과 남성 사이의 생존곡선에 차이가 없다는 귀무가설을 기각할 수 없다. 즉 남녀의 생존에 차이가 있다는 증거가 없다는 것이다.
from lifelines.statistics import logrank_test
logrank_test(by_sex['Male']['time'],
by_sex['Female']['time'],
by_sex['Male']['status'],
by_sex['Female']['status'])
| t_0 | -1 |
|---|---|
| null_distribution | chi squared |
| degrees_of_freedom | 1 |
| test_name | logrank_test |
| test_statistic | p | -log2(p) | |
|---|---|---|---|
| 0 | 1.44 | 0.23 | 2.12 |
17.6 생존분석 회귀 모델#
이제 생존 데이터를 회귀 모델로 분석하는 작업을 생각해보자. 생존분석에서는 반응변수 관측값이 \((Y, \delta)\) 형식이다. 여기서 \(Y = \min(T,C)\)는 관측시간으로서 생존시간이나 중도절단시간으로 구성돼있고, \(\delta\)는 \(T ≤ C\)인 경우 1의 값을 갖는 지표변수(또는 사건발생 더미변수)이다. 생존시간을 설명하는 변수 \(X\)는 \(p\)개의 특성(feature)으로 구성돼있다고 하자. 이들 특성을 공변량(covariate)이라고도 부른다. 우리의 목표는 \(X\)를 이용해 생존시간 \(T\)를 예측(또는 분석)하는 것이다.
여기에서도 앞에서와 마찬가지로 중도절단 관측이 문제를 어렵게 만든다. 우리는 생존분석 회귀분석에 있어서도 Kaplan-Meier 생존곡선이나 로그순위 검정과 비슷하게 순차적 방식을 사용한다. 그에 앞서 분석에 필요한 헤저드 함수를 설명한다.
위험함수#
위험함수(hazard function)는 다음과 같이 정의된다.
여기서 \(T\)는 생존시간이다. 위험함수는 시점 \(t\)까지 생존했다는 조건 하에서 그 직후의 사망률이다.(위 식의 분모에 있는 \(\Delta t\)로 인해 위험함수 값은 사망확률 자체는 아니고 “단위시간 당 사망률”이라 표현할 수 있다. 그러나 일반적인 확률밀도함수에서도 그 값이 높을수록 확률변수의 발생 가능도가 높은 것과 마찬가지로 \(h(t)\) 값이 높을수록 사망확률이 높아진다. \(h(t)\)는 사실 \(T \gt t\) 조건 하에서 \(T\)에 대한 확률밀도함수이다.)
식 17.9에서 \(\Delta t\)가 0에 가까워지는 극한을 취하므로 \(\Delta t\)를 극히 작은 숫자로 생각할 수 있다. 따라서 식 17.9를 좀 더 직관적으로 표현하면, 임의의 작은 \(\Delta t\)에 대해 다음을 의미한다.
우리가 위험함수라는 개념을 도입하는 이유는 무엇일까? 우선, 아래에서 보게 되겠지만 위험함수는 생존곡선인 식 17.2와 서로 밀접한 관련이 있다. 둘째, 생존 데이터를 공변량의 함수로 모델링하는 핵심 접근 방식(즉 Cox의 비례위험 모델)이 위험함수에 크게 의존한다. 아래에서 이 접근법을 소개한다.
이제 위험함수 \(h(t)\)를 좀 더 자세히 살펴보자. 두 사건 \(A\)와 \(B\)가 있을때, \(B\) 조건부 \(A\)의 확률, 즉 \(\Pr(A \mid B)\)은 그 정의가 \(\Pr(A ∩ B)/ \Pr(B)\)이다. 즉, \(A\)와 \(B\)가 모두 발생할 확률을 \(B\)가 발생할 확률로 나눈 것이다. 그리고 식 17.2에서 \(S(t) = \Pr(T > t)\)로 정의했기 때문에 다음이 성립한다.
여기서 \(f(t)\)는 다음과 같으며, \(T\)에 대한 확률밀도함수(PDF: probability density function)이다.
또한 위 식 17.10의 두 번째 등호는 \(t < T \le t+\Delta t\)인 경우 당연히 \(T > t\)이어야 한다는 사실을 이용했다.
식 17.10은 위험함수 \(h(t)\), 생존함수 \(S(t)\), 확률밀도함수 \(f(t)\) 사이의 관계를 보여주고 있다. 사실, 이들 세 가지 함수는 \(T\)의 분포를 설명하는 세 가지 동등한 방법이다.
\(i\)번째 관측과 관련된 가능도(likelihood)는 다음과 같다.
식 17.12에 대한 직관적 설명은 다음과 같다. \(i\)번째 관측치가 \(Y = y_i\)이고 이 관측이 중도절단되지 않은 경우, 그것의 가능도는 시간 \(y_i\) 주변의 극히 짧은 기간에 사망할 확률이다. 반면, \(i\)번째 관측치가 중도절단되면 가능도는 적어도 \(y_i\) 시간까지 생존할 확률이다. \(n\)개의 관측치가 독립적이라고 가정하면 데이터의 가능도는 다음과 같다.
여기서 두 번째 등호는 식 17.10, 즉 \(f(t)=h(t)S(t)\)이 성립하기 때문이다.
이제 생존시간을 모델링하는 작업을 생각해보자. 가장 간단한 예로 생존시간 \(T\)가 지수(exponential) 분포를 따른다고 해보자. 지수 분포의 확률밀도함수는 \(f(t) = \lambda \exp(-\lambda t)\)이고 생존함수는 \(S(t)=\exp(-\lambda t)\)이다. 따라서 식 17.13에서 가능도의 로그값, 즉 로그 가능도를 최대화하는 파라미터 \(\lambda\)를 추정하는 것은 간단하다. \(\lambda\)값만 추정하면 그에 따른 생존함수, 즉 \(\hat{S}(t)=\exp(-\hat\lambda t)\)를 바로 얻게 된다. 지수 분포뿐 아니라 좀 더 유연한 분포인 와이블(Weibull) 분포를 사용할 수도 있다. 또 다른 가능성은 우리가 이미 앞 절에서 살펴본 것처럼 카플란-마이어 접근과 같은 비파라미터형(non-parametrical) 방식으로 생존함수를 추정하는 것이다.
그러나 우리가 이 절에서 살펴보고자 하는 것은 생존시간을 \(X\)의 함수로 모델링하는 것이다. 이를 위해서는 확률밀도함수가 아닌 위험함수로 직접 작업하는 것이 편리하다. 한 가지 가능한 접근 방식은 위험함수 \(h(t \mid x_i)\)에 대한 함수 형식을 가정하는 것이다. 가령 \(h(t \mid x_i) = \exp \left( \beta_0 + \sum^p_{j=1} \beta_j x_{ij} \right)\)로 설정하는 것이다. 이렇게 하면 위험함수 값이 항상 양수가 된다. 위험함수 값은 사망률이기 때문에 음수가 될 수 없는데, 지수 함수 \(\exp()\)가 그것을 보장하는 것이다.
\(h(t \mid x_i)\)를 위와 같이 설정할 경우 \(S(t \mid x_i)\)를 계산할 수 있다. 따라서 이것들을 식 17.13에 대입하여 가능도를 최대화하는 파라미터 \(\beta = (\beta_0,\beta_1,...,\beta_p)^T\)를 추정할 수 있다. 그러나 이 접근 방식은 위험함수 \(h(t \mid x_i)\)의 형태에 대해 매우 엄격한 가정을 해야 한다는 점에서 상당히 제한적이다. 다음 절에서는 훨씬 더 유연한 접근 방식을 살펴본다.
비례위험#
비례위험(proportional hazard) 가정은 다음을 의미한다.
여기서 \(h_0(t) \ge 0\)은 기준위험(baseline hazard)으로서 모든 특성의 값이 0일 때(즉 \(x_{i1}=...=x_{ip} = 0\))의 위험함수이다. 비례위험 모형에서는 \(h_0(t)\)에 대해 함수 형태를 지정하지 않는다. “비례”위험이라는 이름은 위험함수가 \(h_0(t)\)에다 \(\exp \left( \sum^p_{j=1} \beta_j x_{ij} \right)\)을 곱한 것이라는 사실에서 유래했다. 여기에서 \(h_0(t)\)는 특성 \(x_i = (0, . . . , 0)\)에 대한 위험함수이고, \(\exp \left( \sum^p_{j=1} \beta_j x_{ij} \right)\)는 특성 \(x_i = (x_{i1},...,x_{ip})\)일 때의 상대적 위험(relative risk)을 의미한다. 즉 특성이 \((x_{i1},...,x_{ip})\)일 때 특성이 \(x_i = (0, . . . , 0)\)인 것에 비해 \(\exp \left( \sum^p_{j=1} \beta_j x_{ij} \right)\) 배수만큼 위험이 커진다는 의미이다. 만약 여러 특성 중 \(x_j\)가 1만큼 증가하는 경우 위험함수 값은 \(\exp(\beta_j)\) 배만큼 증가한다. 왜냐하면 \(x_j\)가 1만큼 증가하는 경우 위험함수 값은 다음과 같이 되기 때문이다.(아래 식을 식 17.14와 비교하면 위험함수 값이 \(\exp(\beta_j)\) 배만큼 크다는 것을 알 수 있다.)
식 17.14에서 기준위험함수 \(h_0(t)\)의 형태를 지정하지 않는다는 것은 기본적으로 위험함수 \(h(t)\)의 구체적 형태에 대해 특별히 가정을 하지 않는다는 것을 의미한다. \(t\) 시점까지 생존한 사람이 \(t\) 시점에 순간 사망할 확률은 어떤 형태를 취해도 된다. 이는 위험함수가 매우 유연하고 공변량과 생존시간 간의 광범위한 관계를 모델링할 수 있음을 의미한다. 우리의 유일한 가정은 \(x_{j}\)가 1단위 증가할 때, \(h(t\mid x)\)이 \(\exp(\beta_j)\) 배만큼 증가한다는 것이다.
비례위험 가정(식 17.14)의 예시가 그림 17.3에 나와 있다. 단순화를 위해 생존시간을 설명하는 변수, 즉 공변량(\(x\))이 하나만 있고, 더구나 연속형 변수가 아니라 0과 1의 값만을 갖는 이진 변수라고 해보자. 앞에서 예를 든 남성과 여성 그룹을 구분하는 더미변수가 그 예이다. 그림 17.3에서 위쪽 두 개 그림은 비례위험 가정을 부과한 경우이고, 아래쪽 두 개는 비례위험 가정이 성립하지 않는 경우이다. 그리고 각 가정 하에서 왼쪽은 (로그를 취한)위험함수를 그린 것이고, 오른쪽은 생존함수를 그린 것이다. 4개의 그림 모두 \(x=0\)인 그룹과 \(x=1\)인 그룹의 위험함수와 생존함수를 따로 그려 검정과 녹색으로 구분해놓았다. 먼저 비례위험 가정이 부과된 로그 위험함수(즉 왼쪽 위 그림)를 보면, 비례위험 가정 하에서는 두 그룹의 위험함수는 서로 배수의 관계가 있으므로 로그 척도에서 두 그룹 사이의 간격은 일정하며, 그림에 그것이 표현돼있다. 이럴 경우 두 그룹의 생존곡선은 절대 교차하지 않으며, 생존곡선 사이의 간격은 시간이 지남에 따라 커지게 된다. 반면, 비례위험 가정을 부과하지 않은 아래쪽 두 개 그림에서는 두 그룹의 로그 위험함수와 생존곡선이 모두 교차할 수 있다.
그림 17.3. 공변량(\(x\))이 하나만 있고 0과 1의 값만을 갖는 이진 변수라는 가정 하에서 비례위험을 부과한 경우(위쪽 2개 그림)와 그렇지 않은 경우(아래쪽 2개 그림)로 구분해 각각 위험함수(왼쪽 그림)와 생존함수(오른쪽 그림)를 그려놓은 것이다.
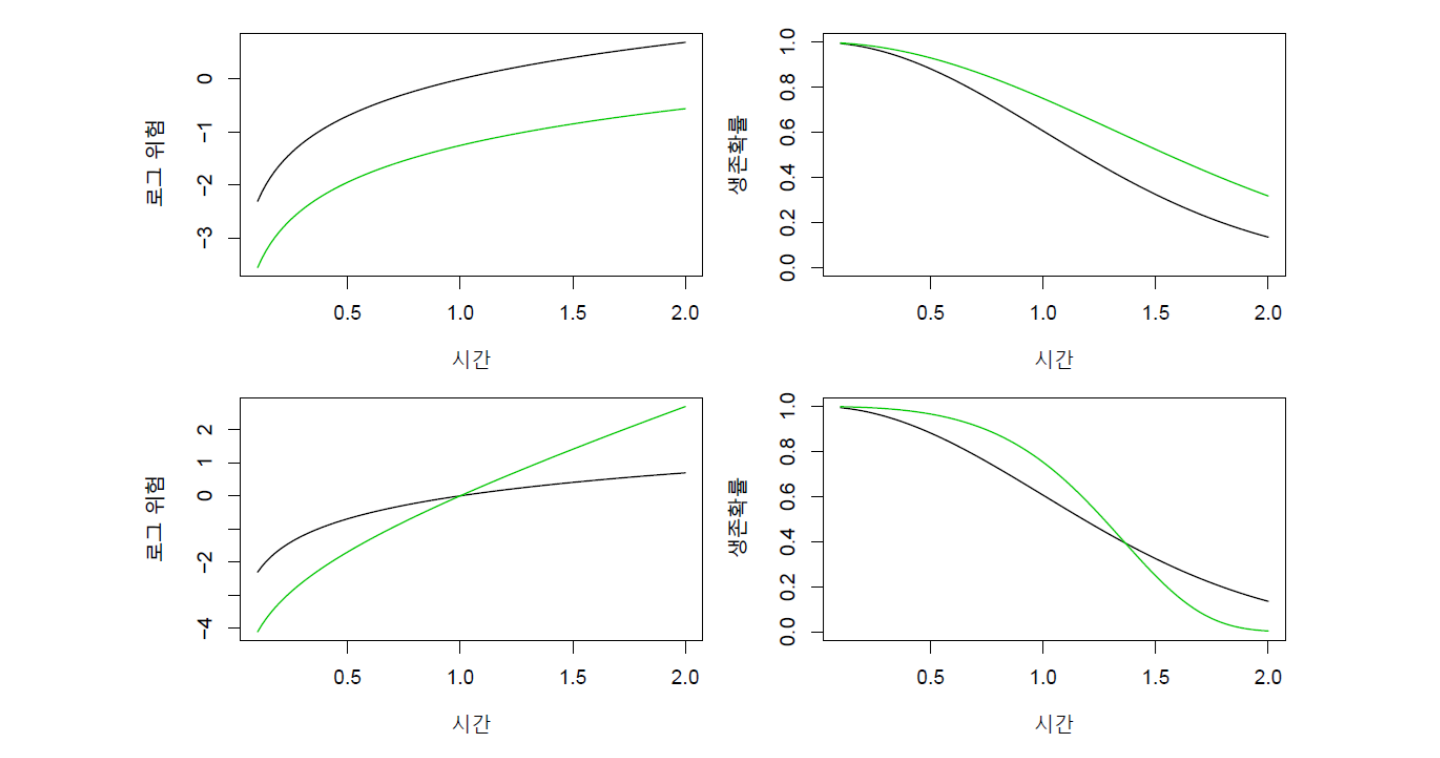
그림 출처: ISLP, FIGURE 11.4
Cox 비례위험 모델#
비례위험 가정(식 17.14)에서 \(h_0(t)\)의 형태를 규정하지 않기 때문에 우리는 \(h(t\mid x_i)\)를 가능도(식 17.13)에 집어넣어 최대가능도 방법으로 \(\beta = (\beta_1, . . . ,\beta_p)\)를 추정할 수 없다. Cox 비례위험 모델의 마법은 \(h_0(t)\)의 형식을 지정하지 않고도 \(\beta\)를 추정할 수 있다는 사실에 있다.
이를 위해 우리는 카플란-마이어 생존곡선과 로그순위 검정에서 사용한 것과 동일한 “시간 순차(sequential in time)” 기법을 사용한다. 단순화를 위해 실패(또는 사망) 시간들 사이에 상관성이 없다고 가정한다. 즉, 각 실패는 독립적으로 발생한다.
일단 \(\delta_i = 1\)인 경우를 생각해보자. 즉 \(i\)번째 관측은 중도절단되지 않았고, 따라서 \(y_i\)는 생존시간이다. 그러면 \(y_i\) 시점에 \(i\)번째 관측에 대한 위험함수는 \(h(y_i\mid x_i) = h_0(y_i) \exp \left( \sum^p_{j=1} \beta_j x_{ij} \right)\)이다. 또한 \(y_i\) 시점 위기관측(at risk)들의 위험을 모두 합친 총위험(total hazard)은 다음과 같다.(\(y_i\) 시점의 위기관측은 해당 시점에서 여전히 실패 위험에 처해있는 관측, 즉 \(y_i\) 시점에 아직 실패하지 않았거나 중도절단되지 않은 관측이다.)
여기에서 \(i^\prime\)은 위기관측을 의미한다. 결국 \(i\)번째 관측이 \(y_i\) 시점에 실패할 확률은 다음과 같다.
바로 여기에서 기준위험함수 \(h_0(y_i)\)가 분자와 분모에서 상쇄되는 것이다!
부분가능도(partial likelihood)는 중도절단되지 않은 모든 관측에 대해 이러한 확률을 곱한 것이다.
결국 \(h_0(t)\)의 형태와 값에 관계없이 부분가능도를 사용할 수 있기 때문에 모델이 매우 유연하고(fexible) 강건하다(robust).(일반적으로 부분가능도는 모든 파라미터에 대한 전체가능도를 계산하기 어려운 상황에서 사용된다. 주요 관심 파라미터에 대해서만 가능도를 계산하며, 이 경우에는 \(\beta_1,...,\beta_p\)이다. 식 17.16을 최대화하면 이들 파라미터에 대한 추정치를 구할 수 있다.)
\(\beta\)에 대한 부분가능도인 식 17.16을 최대화하는 방식으로 \(\beta\)를 추정한다. 폐쇄형 해(solution)가 없으므로 반복적 알고리즘(iterative algorithm)을 사용한다.
Cox 비례위험 모델 부연 설명
식 17.14를 보면 절편항이 없다. 기준위험 \(h_0(t)\)이 절편 역할을 하기 때문이다.
실패시간이 겹치지 않는다고 가정했다. 겹치는 관측이 있는 경우 부분가능도(식 17.16)가 좀 더 복잡해지며 여러 근사적 계산을 사용해야 한다.
식 17.16은 정확한 가능도는 아니다. 즉 식 17.14 가정 하에서 계산한 데이터의 확률과 정확히 일치하지는 않는다. 이 때문에 부분가능도라고 부르며, 정확한 가능도의 매우 좋은 근사치이다.
우리는 계수 \(\beta = (\beta_1,...,\beta_p)\)의 추정에만 초점을 맞췄다. 그러나 때때로 우리는 예를 들어 특정 \(x\) 특성을 지닌 환자의 생존곡선 \(S(t\mid x)\)를 추정할 필요가 있다. 이럴 때는 기준위험 \(h_0(t)\)를 추정해야 한다. 이것 역시 가능한데, \(h_0(t)\)의 추정은 R의
survival이나 파이썬lifelines모듈을 사용한다.
BrainCancer 데이터#
이제 lifelines에서 제공하는 CoxPHFitter() 함수를 사용하여 BrainCancer 데이터세트에 대해 Cox 비례위험 모형을 피팅시켜보자. 먼저, sex 변수 하나만을 예측변수로 사용하는 모델을 추정해보자.
아래에서 보겠지만, CoxPHFitter() 함수로 피팅하기 위해서는 설명변수(sex)와 관측시간 변수(time), 지표변수(status) 등이 들어있는 데이터프레임을 만들어 fit() 메서드에 입력해야 한다. 이 작업을 쉽게 해주는 것이 아래 나와 있는 ModelSpec 즉, MS 함수이다.
ModelSpec은 ISLP 모듈에 들어있는 함수 중의 하나로, 주어진 데이터 프레임을 이용해 회귀 및 분류 작업을 위한 설계행렬(design matrix), 즉 설명변수 행렬을 구축하는 기능을 제공한다. 설명변수 중 범주형 변수가 들어있을 때나 상호작용항을 만들 때 유용하게 사용할 수 있다.
from ISLP.models import ModelSpec as MS
sex_df = BrainCancer[['time', 'status', 'sex']]
model_df = MS(['time', 'status', 'sex'],
intercept=False).fit_transform(sex_df)
아래 결과를 보면, 원래의 설명변수 행렬인 sex_df에서는 sex 변수가 Male/Female의 범주형 변수인데, MS 함수를 사용해 만들어진 model_df 설명변수 행렬에서는 sex[Male] 이름의 0/1의 값을 가진 더미변수로 바뀐 것을 알 수 있다.
from IPython.display import display_html
def display_side_by_side(*args, space=10):
html_str = ''
for df in args:
html_str += df.to_html().replace(
'table','table style="display:inline;margin-right:{}px"'.format(space))
display_html(html_str, raw=True)
display_side_by_side(sex_df.head(), model_df.head(), space=50)
| time | status | sex | |
|---|---|---|---|
| 0 | 57.64 | 0 | Female |
| 1 | 8.98 | 1 | Male |
| 2 | 26.46 | 0 | Female |
| 3 | 47.80 | 1 | Female |
| 4 | 6.30 | 1 | Male |
| time | status | sex[Male] | |
|---|---|---|---|
| 0 | 57.64 | 0 | 0.0 |
| 1 | 8.98 | 1 | 1.0 |
| 2 | 26.46 | 0 | 0.0 |
| 3 | 47.80 | 1 | 0.0 |
| 4 | 6.30 | 1 | 1.0 |
Cox 비례위험 모형 피팅
coxph = CoxPHFitter # shorthand
cox_fit = coxph().fit(model_df, 'time', 'status')
cox_fit.summary[['coef', 'exp(coef)', 'p']]
| coef | exp(coef) | p | |
|---|---|---|---|
| covariate | |||
| sex[Male] | 0.407668 | 1.503309 | 0.233262 |
fit 함수에서 첫 번째 인자(model_df)는 설명변수(sex[Male]), 사건시간 변수(time), 지표변수(status)가 들어있는 데이터프레임이다. Cox 모델은 상수항을 포함하지 않기 때문에 앞의 ModelSpec에서 intercept=False 옵션을 사용했다. summary() 메서드는 많은 열을 제공하는데, 여기서는 일부 출력만을 요구했다.
아래와 같이 이 모델을 특성(feature)이 들어있지 않은 모델과 비교하는 가능도 비율 검정(likelihood ratio test)을 얻는 것도 가능하다.
cox_fit.log_likelihood_ratio_test()
| null_distribution | chi squared |
|---|---|
| degrees_freedom | 1 |
| test_name | log-likelihood ratio test |
| test_statistic | p | -log2(p) | |
|---|---|---|---|
| 0 | 1.44 | 0.23 | 2.12 |
위 결과를 보면, 남성과 여성의 생존에 차이가 있다고 볼 명백한 증거는 없는 것으로 나왔다. Cox 모델의 점수검정(score test)은 앞의 로그순위 검정 결과와 정확히 같다!
모든 예측변수 사용
이제 주어진 예측변수를 모두 사용하여 모델을 피팅시켜보자. 먼저 diagnosis 값 중 하나가 누락되었기 때문에 해당 관측값을 삭제한 후 피팅을 수행한다.
cleaned = BrainCancer.dropna()
all_MS = MS(cleaned.columns, intercept=False)
all_df = all_MS.fit_transform(cleaned)
fit_all = coxph().fit(all_df, 'time', 'status')
fit_all.summary[['coef', 'exp(coef)', 'p']]
| coef | exp(coef) | p | |
|---|---|---|---|
| covariate | |||
| sex[Male] | 0.183748 | 1.201712 | 0.610119 |
| diagnosis[LG glioma] | -1.239530 | 0.289520 | 0.032455 |
| diagnosis[Meningioma] | -2.154566 | 0.115954 | 0.000002 |
| diagnosis[Other] | -1.268870 | 0.281149 | 0.039949 |
| loc[Supratentorial] | 0.441195 | 1.554563 | 0.530665 |
| ki | -0.054955 | 0.946527 | 0.002693 |
| gtv | 0.034293 | 1.034887 | 0.124661 |
| stereo[SRT] | 0.177778 | 1.194560 | 0.767597 |
위 결과를 보면, 가령 남성 환자의 추정 위험이 여성 환자보다 \(e^{0.18} = 1.20\)배(즉 20%) 더 크다. 이는 다른 모든 특성이 고정된 상태에서 남성은 어느 시점에서든 여성보다 사망확률이 1.2배 더 높은 것을 의미한다. 그러나 해당 변수의 \(p\)-값이 0.61로 남성과 여성의 차이가 통계적으로 유의하지 않다.
다음으로 diagnosis 변수는 HG glioma가 기준범주로 처리됐다. 결과적으로 HG glioma 환자의 추정 위험이 가장 높은데, 다른 예측변수를 통제한 상태에서 Meningioma 환자의 위험이 기준범주인 HG glioma 환자의 0.12배(즉, \(e^{-2.15}=0.12\))이다. 거꾸로 말하면, HG glioma 환자의 위험이 Meningioma 환자보다 8.58배(즉, \(e^{2.15}=8.58\)) 더 크다는 것을 의미한다.
또 다른 예로 Karnofsky 지수가 1단위 증가할 때, 순간 사망확률이 \(e^{-0.05} = 0.95\)배가 된다는 것을 알 수 있다. 즉 Karnofsky 지수가 높을수록 어느 시점에서든 사망확률이 5% 낮아진다. 이 효과는 \(p\)-값이 0.0027로 통계적으로 매우 유의하다.
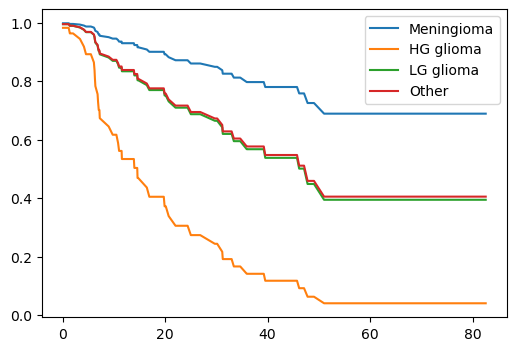
다른 예측변수를 통제한 상태에서 각 diagnosis 범주에 대한 추정 생존곡선을 그려보자. 이를 위해 다른 예측변수 중 정량적 변수들은 평균값을 취하고, 범주형 변수는 최빈값을 취하는 것으로 설정한다. 이를 위해 apply() 메서드를 사용하여 행을 따라(즉, axis=0) representative 함수를 사용하여 열이 범주형인지 확인한다.
levels = cleaned['diagnosis'].unique()
def representative(series):
if hasattr(series.dtype, 'categories'):
return pd.Series.mode(series)
else:
return series.mean()
modal_data = cleaned.apply(representative, axis=0)
그런 다음, 열의 평균(또는 최빈값) 결과를 4개 행으로 복사하고 diagnosis에 대해서만은 (최빈값이 아니라) 주어진 네 가지 다른 범주를 집어넣는다.
modal_df = pd.DataFrame([modal_data.iloc[0] for _ in range(len(levels))])
modal_df['diagnosis'] = levels
modal_df
| sex | diagnosis | loc | ki | gtv | stereo | status | time | |
|---|---|---|---|---|---|---|---|---|
| 0 | Female | Meningioma | Supratentorial | 80.91954 | 8.687011 | SRT | 0.402299 | 27.188621 |
| 0 | Female | HG glioma | Supratentorial | 80.91954 | 8.687011 | SRT | 0.402299 | 27.188621 |
| 0 | Female | LG glioma | Supratentorial | 80.91954 | 8.687011 | SRT | 0.402299 | 27.188621 |
| 0 | Female | Other | Supratentorial | 80.91954 | 8.687011 | SRT | 0.402299 | 27.188621 |
그런 다음, 모델 피팅에 사용된 all_MS 모델 설정을 기반으로 모델 행렬을 만들고, 행의 이름(즉 인덱스)을 diagnosis의 4개 범주로 지정한다.
modal_X = all_MS.transform(modal_df)
modal_X.index = levels
modal_X
| sex[Male] | diagnosis[LG glioma] | diagnosis[Meningioma] | diagnosis[Other] | loc[Supratentorial] | ki | gtv | stereo[SRT] | status | time | |
|---|---|---|---|---|---|---|---|---|---|---|
| Meningioma | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 80.91954 | 8.687011 | 1.0 | 0.402299 | 27.188621 |
| HG glioma | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 80.91954 | 8.687011 | 1.0 | 0.402299 | 27.188621 |
| LG glioma | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 80.91954 | 8.687011 | 1.0 | 0.402299 | 27.188621 |
| Other | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 80.91954 | 8.687011 | 1.0 | 0.402299 | 27.188621 |
predict_survival_function() 메서드를 사용하여 추정된 생존함수를 얻을 수 있다.
predicted_survival = fit_all.predict_survival_function(modal_X)
predicted_survival
| Meningioma | HG glioma | LG glioma | Other | |
|---|---|---|---|---|
| 0.07 | 0.997947 | 0.982430 | 0.994881 | 0.995029 |
| 1.18 | 0.997947 | 0.982430 | 0.994881 | 0.995029 |
| 1.41 | 0.995679 | 0.963342 | 0.989245 | 0.989555 |
| 1.54 | 0.995679 | 0.963342 | 0.989245 | 0.989555 |
| 2.03 | 0.995679 | 0.963342 | 0.989245 | 0.989555 |
| ... | ... | ... | ... | ... |
| 65.02 | 0.688772 | 0.040136 | 0.394181 | 0.404936 |
| 67.38 | 0.688772 | 0.040136 | 0.394181 | 0.404936 |
| 73.74 | 0.688772 | 0.040136 | 0.394181 | 0.404936 |
| 78.75 | 0.688772 | 0.040136 | 0.394181 | 0.404936 |
| 82.56 | 0.688772 | 0.040136 | 0.394181 | 0.404936 |
85 rows × 4 columns
반환된 데이터프레임을 plot 메서드를 사용해 그림으로 그린다.
fig, ax = subplots(figsize=(6, 4))
predicted_survival.plot(ax=ax)
plt.show()
Publication 데이터#
이제 ISLP에서 제공하는 Publication 데이터세트를 분석해보자. 이 데이터세트는 미국 국립심폐혈연구소(NHLBI: National Heart, Lung, and Blood Institute)의 자금지원을 받고 수행된 임상시험 결과가 학술지 논문으로 출판되기까지 걸린 시간을 다룬다.(이 데이터세트는 다음 논문에 설명돼있다: Gordon et al. (2013), “Publication of trials funded by the National Heart, Lung, and Blood Institute,” New England Journal of Medicine, 369(20):1926–1934.)
데이터세트에는 총 244건의 논문 투고에 대해 출판(성공)까지 걸린 시간(개월)이 기록돼있다. 분석 기간 내에 244건 중 156건만 출판이 확인됐고, 나머지 연구는 출판(까지 걸린) 시간이 중도절단됐다.
공변량 설명
clinend: 임상시험이 임상적 결과변수(clinical endpoint)에 초점을 맞춘 것인지 여부multi: 임상시험이 복수의 센터에서 진행되었는지 여부mech: 미국 국립보건원(NIH) 펀딩 메커니즘sampsize: 임상시험 표본 크기budget: 예산impact: 학술지의 권위posres: 임상시험 결과가 긍정적(positive)인지 여부
마지막 공변량은 특히 흥미롭다. 왜냐하면 몇몇 선행 연구에서 결과가 긍정적인 임상시험인 경우 논문의 출판 성공률이 더 높다고 주장한 바 있기 때문이다.
Publication = load_data('Publication')
Publication
| posres | multi | clinend | mech | sampsize | budget | impact | time | status | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | R01 | 39876 | 8.016941 | 44.016 | 11.203285 | 1 |
| 1 | 0 | 0 | 1 | R01 | 39876 | 8.016941 | 23.494 | 15.178645 | 1 |
| 2 | 0 | 0 | 1 | R01 | 8171 | 7.612606 | 8.391 | 24.410678 | 1 |
| 3 | 0 | 0 | 1 | Contract | 24335 | 11.771928 | 15.402 | 2.595483 | 1 |
| 4 | 0 | 0 | 1 | Contract | 33357 | 76.517537 | 16.783 | 8.607803 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 239 | 0 | 0 | 0 | R01 | 4105 | 2.703653 | 5.355 | 65.018480 | 1 |
| 240 | 1 | 0 | 0 | R44 | 181 | 1.117084 | 0.000 | 66.989733 | 0 |
| 241 | 0 | 0 | 0 | K23 | 104 | 0.472321 | 0.000 | 9.987680 | 0 |
| 242 | 0 | 0 | 0 | R21 | 69 | 0.404710 | 0.000 | 21.979466 | 0 |
| 243 | 1 | 0 | 0 | R01 | 1699 | 2.957751 | 0.000 | 4.632444 | 0 |
244 rows × 9 columns
우선, posres 변수를 기준으로 Kaplan-Meier 곡선을 그려보자. 이 변수는 임상시험이 긍정적(posres\(=1\)) 결과를 보였는지 부정적(posres\(=0\)) 결과를 보였는지를 분류한 것이다. 아래 결과를 보면, 긍정적 결과를 얻은 연구의 경우 출판까지의 시간이 약간 더 짧은 경향이 있다고도 볼 수 있지만, 로그순위 검정의 \(p\)-값은 0.36으로서 그 증거가 아주 미약하다.
fig, ax = subplots(figsize=(6,4))
by_result = {}
for result, df in Publication.groupby('posres'):
by_result[result] = df
kmf_result = kmf.fit(df['time'], df['status'])
kmf_result.plot(label='Result=%d' % result, ax=ax, ci_show=False)
plt.show()
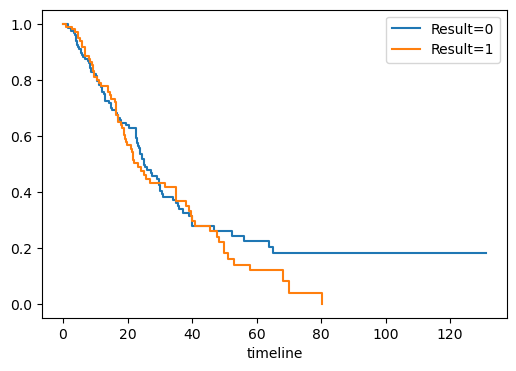
from lifelines.statistics import logrank_test
logrank_test(by_result[1]['time'],
by_result[0]['time'],
by_result[1]['status'],
by_result[0]['status'])
| t_0 | -1 |
|---|---|
| null_distribution | chi squared |
| degrees_of_freedom | 1 |
| test_name | logrank_test |
| test_statistic | p | -log2(p) | |
|---|---|---|---|
| 0 | 0.84 | 0.36 | 1.48 |
로그순위 검정과 동일한 결과를 다음과 같이 Cox 비례위험 모형 추정으로도 얻을 수 있다. posres 변수를 사용해 Cox 모형을 피팅한 결과 \(p\)-값이 0.36이 나와 연구결과가 긍정적이든 부정적이든 출판까지의 시간에 통계적으로 유의한 차이가 없음을 시사한다.
posres_df = MS(['posres', 'time', 'status'], intercept=False).fit_transform(Publication)
posres_fit = coxph().fit(posres_df, 'time', 'status')
posres_fit.summary[['coef', 'se(coef)', 'p']]
| coef | se(coef) | p | |
|---|---|---|---|
| covariate | |||
| posres | 0.148076 | 0.161625 | 0.359579 |
Publication 데이터세트의 모든 가능한 예측변수를 사용하여 Cox의 비례위험 모델을 피팅한 결과가 아래 나와 있다. 특성 중 posres, multi, clinend는 이진형이다. mech는 14개 범주를 가진 정성적 변수로서 Contract가 기준범주로 코드화되었다.
아래 결과에서 posres 변수를 보면, 다른 모든 공변량이 동일하다고 했을 때, 긍정적 결과를 얻은 연구의 출판성공 확률이 부정적 결과를 지닌 연구보다 어느 시점에서나 \(e^{0.55} = 1.74\)배 높은 것으로 나타났다. 또한 posres의 \(p\)-값이 0.0025로서 통계적으로 매우 유의하다. 이는 앞의 로그순위 검정 결과와 크게 다르다. 이 차이를 어떻게 이해할 수 있을까? 답은 로그순위 검정은 다른 공변량을 고려하지 않았다는 사실에서 비롯된다. 반면 아래 결과는 모든 가능한 공변량을 사용하여 Cox 모형을 추정한 것이다. 다시 말해 모든 다른 공변량을 통제한 후에 연구의 긍정적 결과 여부가 출판까지의 시간에 영향을 미치는지를 분석한 것이다.
model = MS(Publication, intercept=False)
coxph().fit(model.fit_transform(Publication),
'time', 'status').summary[['coef', 'se(coef)', 'p']]
| coef | se(coef) | p | |
|---|---|---|---|
| covariate | |||
| posres | 0.551640 | 0.182717 | 2.535382e-03 |
| multi | 0.145992 | 0.308381 | 6.359175e-01 |
| clinend | 0.511395 | 0.270431 | 5.861968e-02 |
| mech[K01] | 1.052064 | 1.056043 | 3.191371e-01 |
| mech[K23] | -0.476995 | 1.052992 | 6.505557e-01 |
| mech[P01] | -0.308363 | 0.777526 | 6.916659e-01 |
| mech[P50] | 0.599473 | 1.055111 | 5.699254e-01 |
| mech[R01] | 0.095584 | 0.318222 | 7.638953e-01 |
| mech[R18] | 1.045022 | 1.054980 | 3.219001e-01 |
| mech[R21] | -0.045080 | 1.056565 | 9.659673e-01 |
| mech[R24, K24] | 0.807824 | 1.053419 | 4.431653e-01 |
| mech[R42] | -15.335014 | 4516.579075 | 9.972910e-01 |
| mech[R44] | -0.566349 | 0.773507 | 4.640565e-01 |
| mech[RC2] | -15.594607 | 3144.460755 | 9.960430e-01 |
| mech[U01] | -0.223964 | 0.319267 | 4.829949e-01 |
| mech[U54] | 0.468824 | 1.068121 | 6.607167e-01 |
| sampsize | 0.000003 | 0.000015 | 8.483310e-01 |
| budget | 0.004195 | 0.002508 | 9.434070e-02 |
| impact | 0.060104 | 0.007301 | 1.841051e-16 |
앞에서 BrainCancer 데이터세트에서 (diagnosis 범주에 대해) 행했던 것처럼 다른 예측변수를 통제한 상태에서 posres의 두 가지 범주에 대한 생존곡선을 그려보자. 이를 위해서는 기준위험 \(h_0(t)\)를 추정하고, posres 이외의 다른 예측변수에 대한 대표값을 선택해야 하는데, mech를 제외한 다른 변수들에 대해서는 평균값을 사용했으며, 범주형 변수인 mech에 대해서는 빈도수가 가장 많은 범주(R01)를 사용했다. 아래 결과를 보면, 이제 긍정적 결과를 지닌 연구와 부정적 결과를 지닌 연구의 생존곡선에 명확한 차이가 있는 것을 볼 수 있다.
그림 17.3. Publication 데이터에 대해 모든 다른 공변량을 통제한 후, 연구가 긍정적인 결과를 도출했는지 여부에 따라 출판(성공)까지 걸리는 시간에 대한 생존곡선을 그린 것이다.
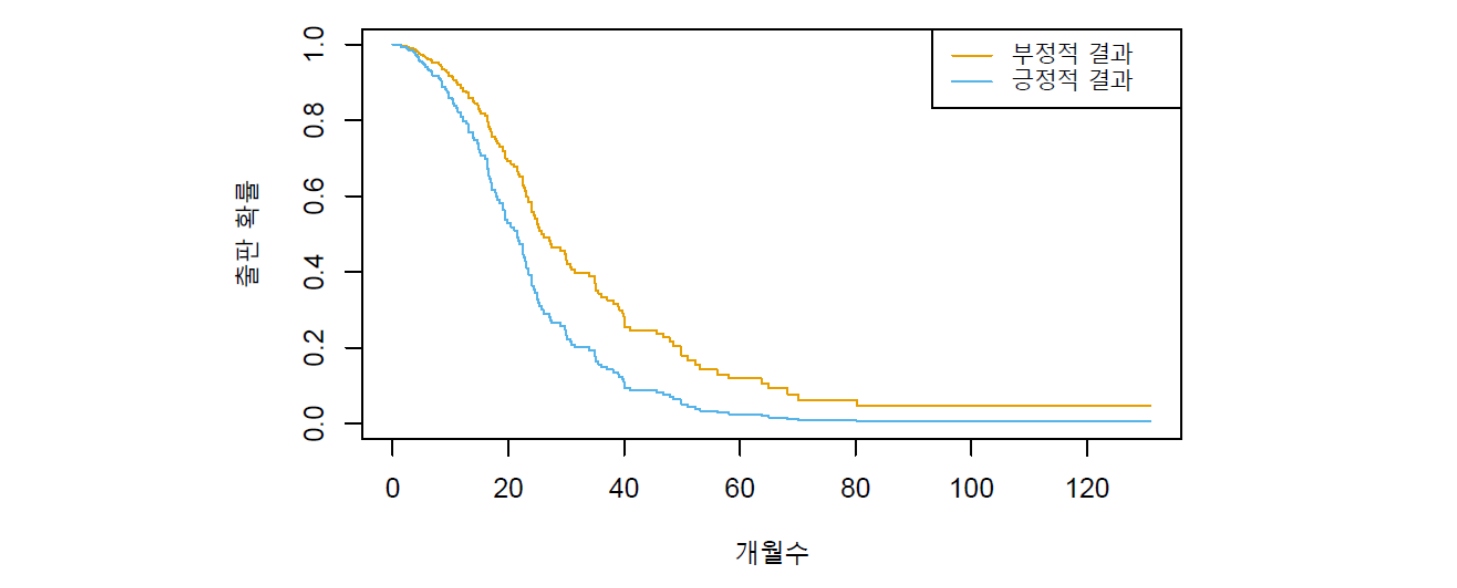
그림 출처: ISLP, FIGURE 11.6
한편, 앞의 Cox 비례위험 모형 추정 결과를 보면 또 다른 흥미로운 통찰력을 얻을 수 있는데, 예를 들어, 임상적 결과변수(clinend)가 있는 연구는 출판될 가능성이 더 높은 반면, 펀딩 메커니즘은 전체적으로 출판까지의 시간과 유의한 관련성이 없는 것으로 나타났다.
콜센터 데이터#
이번에는 누적위험(cumulative hazard) 함수와 생존함수 간의 관계를 활용하여 생존 데이터를 가상으로 생성한다. 생성된 가상 데이터는 콜센터에 전화를 건 2,000명 고객의 관측된 대기시간(초)을 나타낸다. 이 상황에서 중도절단은 대기하던 고객이 통화가 성사되기 전에 전화를 끊는 경우다.
다음 세 가지 공변량이 있다.
Operators: 통화 시점에 서비스가 가능한 콜센터 상담원 수(5명~15명)Center: A, B, CTime: 통화 시점(아침, 오후, 저녁)
시뮬레이션 데이터 생성
이러한 공변량을 가진 데이터를 생성하는데, 모든 가능성이 동일한 것으로 설정하자. 즉, 아침/오후/저녁 통화가 동일한 확률로 발생하고, \(5\)명에서 \(15\)명까지의 상담원 수가 모두 동일한 확률로 발생한다.
rng = np.random.default_rng(10)
N = 2000
Operators = rng.choice(np.arange(5, 16), N, replace=True)
Center = rng.choice(['A', 'B', 'C'], N, replace=True)
Time = rng.choice(['Morn.', 'After.', 'Even.'], N, replace=True)
D = pd.DataFrame({'Operators': Operators,
'Center': pd.Categorical(Center),
'Time': pd.Categorical(Time)})
먼저 모델을 설정한다.(절편은 없음)
model = MS(['Operators', 'Center', 'Time'], intercept=False)
X = model.fit_transform(D)
X를 확인해보자. Center와 Time 변수의 경우 각각 기준범주를 제거했다.
X[:5]
| Operators | Center[B] | Center[C] | Time[Even.] | Time[Morn.] | |
|---|---|---|---|---|---|
| 0 | 13 | 0.0 | 1.0 | 0.0 | 0.0 |
| 1 | 15 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | 7 | 1.0 | 0.0 | 0.0 | 1.0 |
| 3 | 7 | 0.0 | 1.0 | 0.0 | 1.0 |
| 4 | 13 | 0.0 | 1.0 | 1.0 | 0.0 |
다음으로 계수를 정하고 위험함수를 규정한다.
true_beta = np.array([0.04, -0.3, 0, 0.2, -0.2])
true_linpred = X.dot(true_beta)
hazard = lambda t: 1e-5 * t
여기서는 Operators와 관련된 계수를 \(0.04\)로 설정했다. 다시 말해, 각 추가적인 상담사는 Center 및 Time 공변량이 주어진 상황에서 통화가 응답될 “위험”을 \(e^{0.04}=1.041\)배 증가시킨다. 이는 상담사 숫자가 많을수록 대기시간이 짧아진다는 의미이다! Center == B와 관련된 계수는 \(-0.3\)이며, Center == A는 기준범주로 간주된다. Center B에서 통화가 응답될 위험이 Center A에서 응답될 위험의 0.74배이다. 다시 말해 Center B에서 대기시간이 조금 더 길다는 것을 의미한다.
lambda를 사용하여 간단한 함수를 만들 수 있는데, ISLP.survival 패키지의 sim_time() 함수를 이용한다. 이 함수는 생존함수와 누적위험함수 간의 관계, 즉 \(S(t) = \exp(-H(t))\)와 Cox 모델에서 누적위험함수의 구체적 형태를 사용한다. 그렇게 해서 예측변수인 true_linpred와 누적위험의 값에 기반해 시뮬레이션 데이터를 생성한다. 이를 위해 누적위험함수를 제공해야 하는데, 다음과 같이 규정했다.
cum_hazard = lambda t: 1e-5 * t**2 / 2
이제 Cox 비례위험 모델에서 데이터를 생성할 준비가 되었다. 시뮬레이션 대기시간을 합리적으로 만들기 위해 최대 시간을 1000초에서 절단했다. sim_time() 함수는 선형 예측값, 누적위험함수, 그리고 난수 생성기를 사용한다.
from ISLP.survival import sim_time
W = np.array([sim_time(l, cum_hazard, rng) for l in true_linpred])
D['Wait time'] = np.clip(W, 0, 1000)
이제 중도절단 변수를 시뮬레이션하는데, 90%의 통화가 고객이 전화를 끊기(Failed==0) 전에 응답(Failed==1)이 이루어졌다고 가정한다 .
D['Failed'] = rng.choice([1, 0], N, p=[0.9, 0.1])
D
| Operators | Center | Time | Wait time | Failed | |
|---|---|---|---|---|---|
| 0 | 13 | C | After. | 525.064979 | 1 |
| 1 | 15 | A | Even. | 254.677835 | 1 |
| 2 | 7 | B | Morn. | 487.739224 | 1 |
| 3 | 7 | C | Morn. | 308.580292 | 1 |
| 4 | 13 | C | Even. | 154.174608 | 1 |
| ... | ... | ... | ... | ... | ... |
| 1995 | 9 | A | Morn. | 219.225691 | 1 |
| 1996 | 12 | C | After. | 300.182766 | 0 |
| 1997 | 7 | C | Morn. | 253.019911 | 1 |
| 1998 | 12 | A | Even. | 485.481804 | 1 |
| 1999 | 7 | B | Even. | 258.815204 | 1 |
2000 rows × 5 columns
D['Failed'].mean()
0.9075
센터별 Kaplan-Meier 생존곡선
먼저 Center의 각 범주별로 Kaplan-Meier 생존곡선을 그린다. 그래프에서 한글이 깨지는 것을 막기 위해서는 아래 명령문을 실행해야 한다.
import platform
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
if platform.system() == 'Darwin': # Mac
rc('font', family='AppleGothic')
elif platform.system() == 'Windows': # Windows
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
else: # Linux (Colab 등)
# 별도 폰트 설치 필요
pass
# 축에 마이너스 부호 제대로 나오게 하기
plt.rcParams['axes.unicode_minus'] = False
fig, ax = subplots(figsize=(6, 4))
by_center = {}
for center, df in D.groupby('Center', observed=False):
by_center[center] = df
kmf_center = kmf.fit(df['Wait time'], df['Failed'])
kmf_center.plot(label='Center=%s' % center, ax=ax, ci_show=False)
ax.set_title("전화를 들고 있을 확률")
ax.set_xlabel("대기시간(초)")
plt.show()
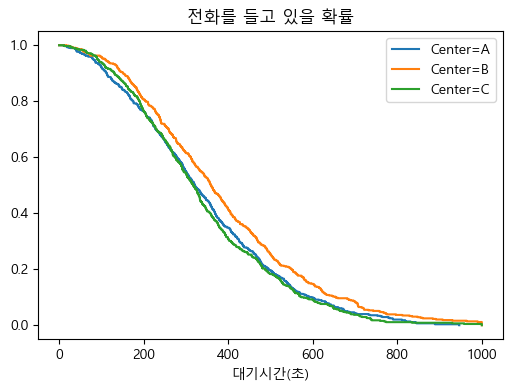
위 그림을 보면, Call Center B의 전화 응답 대기시간이 A 및 C 센터의 전화에 비해 더 오래 걸리는 것으로 보인다.
나절별 Kaplan-Meier 생존곡선
하루 중 전화를 건 나절(Time)에 따라 계층화한다.
fig, ax = subplots(figsize=(6,4))
by_time = {}
for time, df in D.groupby('Time', observed=False):
by_time[time] = df
kmf_time = kmf.fit(df['Wait time'], df['Failed'])
kmf_time.plot(label='Time=%s' % time, ax=ax, ci_show=False)
ax.set_title("전화를 들고 있을 확률")
ax.set_xlabel("대기시간(초)")
plt.show()
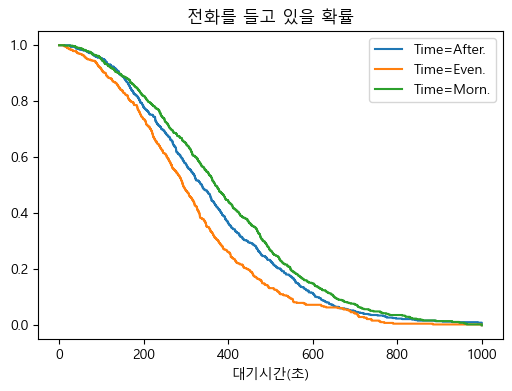
위 그림에서 보듯이 하루 나절별 대기시간은 아침이 가장 길고 저녁에 가장 짧은 것으로 나타났다.
통계적 유의성
multivariate_logrank_test() 함수를 사용해 센터별 및 나절별 차이가 통계적으로 유의한지 여부를 로그순위 검정으로 따져볼 수 있다. 아래 결과를 보면 센터별 차이가 통계적으로 유의하다.
multivariate_logrank_test(D['Wait time'], D['Center'], D['Failed'])
| t_0 | -1 |
|---|---|
| null_distribution | chi squared |
| degrees_of_freedom | 2 |
| test_name | multivariate_logrank_test |
| test_statistic | p | -log2(p) | |
|---|---|---|---|
| 0 | 20.30 | <0.005 | 14.65 |
나절별(Time) 차이 역시 아래 결과에서 보듯이 통계적으로 유의하다.
multivariate_logrank_test(D['Wait time'], D['Time'], D['Failed'])
| t_0 | -1 |
|---|---|
| null_distribution | chi squared |
| degrees_of_freedom | 2 |
| test_name | multivariate_logrank_test |
| test_statistic | p | -log2(p) | |
|---|---|---|---|
| 0 | 49.90 | <0.005 | 35.99 |
범주가 2개만 있는 변수와 마찬가지로 위의 로그순위 검정 결과는 Cox 비례위험 모델에서의 가능도비율 검정과 유사하다. 아래에서 보듯이 (로그순위 검정과 마찬가지로) 센터 간의 차이가 매우 유의하며, 또한 나절별 차이도 유의한 것으로 나타났다.
X = MS(['Wait time', 'Failed', 'Center'], intercept=False).fit_transform(D)
F = coxph().fit(X, 'Wait time', 'Failed')
F.log_likelihood_ratio_test()
| null_distribution | chi squared |
|---|---|
| degrees_freedom | 2 |
| test_name | log-likelihood ratio test |
| test_statistic | p | -log2(p) | |
|---|---|---|---|
| 0 | 20.58 | <0.005 | 14.85 |
X = MS(['Wait time', 'Failed', 'Time'], intercept=False).fit_transform(D)
F = coxph().fit(X, 'Wait time', 'Failed')
F.log_likelihood_ratio_test()
| null_distribution | chi squared |
|---|---|
| degrees_freedom | 2 |
| test_name | log-likelihood ratio test |
| test_statistic | p | -log2(p) | |
|---|---|---|---|
| 0 | 48.12 | <0.005 | 34.71 |
Cox의 비례위험 모델
마지막으로, 데이터에 Cox의 비례위험 모델을 피팅시켰다.
X = MS(D.columns, intercept=False).fit_transform(D)
fit_queuing = coxph().fit(X, 'Wait time', 'Failed')
fit_queuing.summary[['coef', 'se(coef)', 'p']]
| coef | se(coef) | p | |
|---|---|---|---|
| covariate | |||
| Operators | 0.043934 | 0.007520 | 5.143589e-09 |
| Center[B] | -0.236060 | 0.058113 | 4.864162e-05 |
| Center[C] | 0.012231 | 0.057518 | 8.316096e-01 |
| Time[Even.] | 0.268845 | 0.057797 | 3.294956e-06 |
| Time[Morn.] | -0.148217 | 0.057334 | 9.733557e-03 |
Center[B] 및 Time[Even.]에 대한 \(p\)-값이 매우 작다. 또한, 상담사 숫자와 함께 위험(통화가 이루어질 순간적인 위험)이 증가하는 것이 명확하다.
데이터를 직접 생성했기 때문에 우리는 Operators, Center = B, Center = C, Time = Even., Time = Morn.에 대한 계수 참값을 알고 있다. 각각 \(0.04\), \(-0.3\), \(0\), \(0.2\), \(-0.2\)이다. 위의 피팅 결과를 보면, Cox 모델의 계수 추정값이 상당히 정확한 편이다.