3장 수출 다각화를 측정해보자#
출처: UNCTAD (2012), A Practical Guide to Trade Policy Analysis, Chapter 1.
1. 내연적 마진과 외연적 마진#
Hummels와 Klenow(2005)는 무역 데이터 분석에서 내연적 마진(intensive margin)과 외연적 마진(extensive margin)이라는 개념을 도입했다.(Hummels, D., & Klenow, P. J. (2005). The variety and quality of a nation’s exports. American economic review, 95(3), 704-723.) 이 개념들은 나라들의 무역 성과를 더 정교하게 평가하기 위해 사용된다.
정의#
어떤 나라의 내연적 마진(intensive margin)은 그 나라가 이미 수출하고 있는 제품들에 있어서 시장 점유율이 어느 정도인지를 측정한 것이다. 어떤 나라 \(i\)의 내연적 마진을 식으로 표현하면 다음과 같다.
여기서, \(K_i\)는 \(i\)국이 수출하는 제품의 집합이고, \(X_{i,k}\)는 \(i\)국의 \(k\)재 수출액이며, \(X_{W,k}\)는 세계 전체의 \(k\)재 수출액이다. 따라서 위 식의 분자는 \(i\)국의 총 수출액이고, 분모는 \(i\)국 수출 상품에 대해 세계 각국의 수출액을 모두 합친 것이다.
외연적 마진(extensive margin)은 어떤 나라가 수출하는 제품들이 세계 무역에서 차지하는 비중을 측정한 것이다. 이는 해당 국가가 새로운 제품을 수출하거나 새로운 시장에 진출함으로써 무역을 확장할 수 있는 잠재력을 나타낸다. 식으로 표현하면 다음과 같다.
여기서, \(K_W\)는 모든 수출 상품의 집합이다. 따라서 위 식의 분자는 \(i\)국 수출 상품에 대해 세계 각국 수출액을 모두 합친 것이고, 분모는 모든 수출 상품에 대해 세계 각국 수출액을 모두 합친 것이다.
시장별 다각화#
Hummels와 Klenow의 접근 방식은 제품이 아니라 지리적 시장에 적용할 수도 있다. \(i\)국이 수출하는 목적지 시장의 집합을 \(D_i\)라 하자. 특정 목적지 \(d\)국에 대한 \(i\)국의 총수출액을 \(X_d^i\), 그리고 해당 목적지로의 세계 총수출액(즉, 해당 국가의 총 수입액)을 \(X_d^W\)라고 하자.
이 경우 (제품이 아니라 시장에 대한) 내연적 마진은 다음과 같이 정의된다.
여기서 \(D_W\)는 모든 목적지 국가의 집합이다. 즉, 이는 \(i\)국이 수출하는 목적지에서의 시장 점유율, 즉 해당 국가들의 전체 수입에서 차지하는 비중을 의미한다.
마찬가지로 (제품이 아니라 시장에 대한) 외연적 마진은 다음과 같이 정의된다.
이는 \(i\)국이 수출하는 목적지 시장들이 세계 무역에서 차지하는 비중(즉, 해당 목적지들의 세계 총수입에서 차지하는 비중)을 나타낸다.
의의#
Hummels와 Klenow의 내연적 마진과 외연적 마진은 전통적인 무역 측정 방법에 비해 몇 가지 중요한 이점을 제공한다.
기존의 단순한 무역량 분석에서 벗어나, 특정 국가가 기존 수출품목을 통해 얼마나 많은 시장 점유율을 차지하고 있는지를 파악할 수 있다. 이는 특정 산업이나 제품군에서의 경쟁력을 평가하는 데도 유용하다.
국가가 새로운 제품을 수출하거나 새로운 시장에 진출하는 능력을 평가할 수 있다. 이는 정책 결정자들이 무역 다변화 전략을 수립하는 데 중요한 정보를 제공한다.
내연적 마진은 기존 제품 및 시장에 있어서의 점유율 증대를 목표로 하는 정책의 효과를 측정할 수 있으며, 외연적 마진은 새로운 제품과 시장을 개척(다각화)하는 정책의 효과를 평가하는 데 유용하다.
2. 간단한 숫자 예#
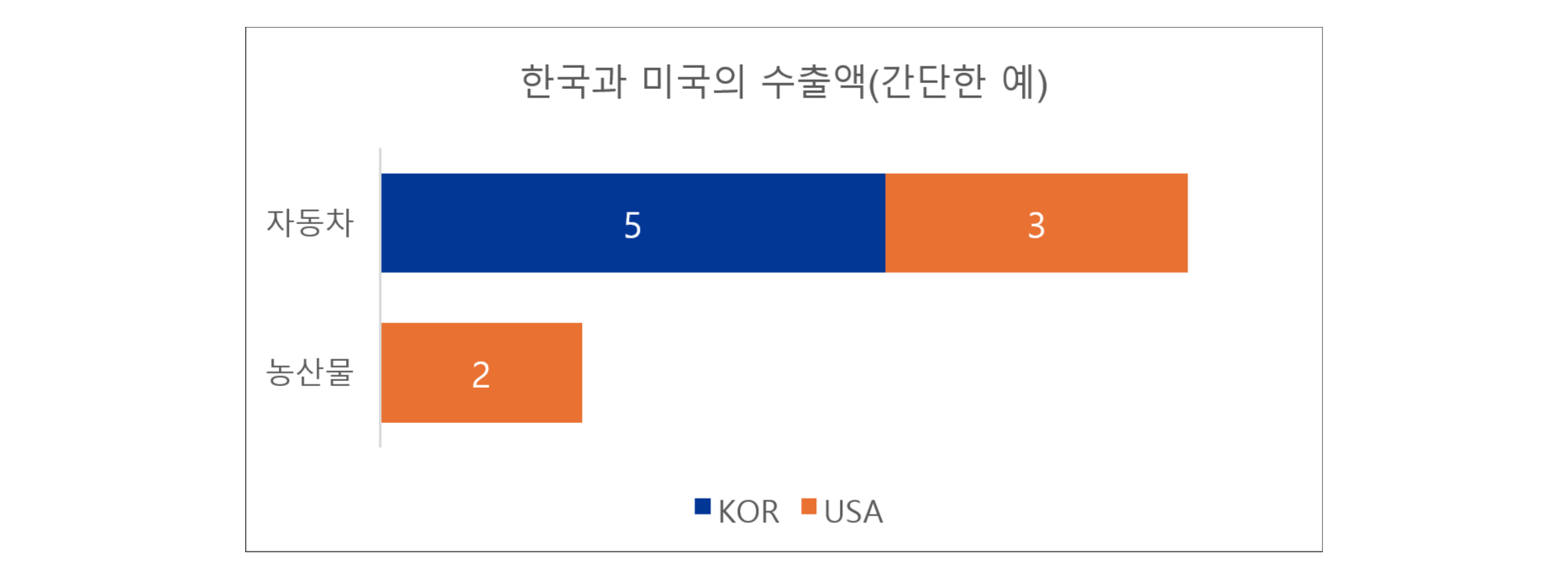
한국(KOR)
내연적 마진: 한국의 수출 품목(자동차)만을 대상으로 한국의 수출이 차지하는 비율을 계산함. 즉, \(\frac{5}{5+3}=0.625\), 즉 62.5%.
외연적 마진: 전체 품목(자동차, 농산물)을 대상으로 한국이 참여하는 품목(자동차)이 전체 품목에서 차지하는 비율을 계산함. 즉, \(\frac{5+3}{5+3+2}=0.8\), 즉 80%.
미국(USA)
내연적 마진: 미국의 수출 품목(자동차, 농산물)을 대상으로 미국의 수출이 차지하는 비율을 계산함. 즉, \(\frac{3+2}{5+3+2}=0.5\), 즉 50%.
외연적 마진: 전체 품목(자동차, 농산물)을 대상으로 미국이 참여하는 품목(자동차, 농산물)이 전체 품목에서 차지하는 비율을 계산함. \(\frac{5+3+2}{5+3+2}=1\), 즉 100%.
IM & EM 계산 코딩#
import pandas as pd
import numpy as np
# Creating the DataFrame
data = {
'reporter': ['KOR', 'USA', 'USA', 'All', 'All'],
'partner': ['WLD', 'WLD', 'WLD', 'WLD', 'WLD'],
'year': [2000, 2000, 2000, 2000, 2000],
'product': ['자동차', '자동차', '농산물', '자동차', '농산물'],
'trade_value': [5, 3, 2, 8, 2]
}
df = pd.DataFrame(data)
df
| reporter | partner | year | product | trade_value | |
|---|---|---|---|---|---|
| 0 | KOR | WLD | 2000 | 자동차 | 5 |
| 1 | USA | WLD | 2000 | 자동차 | 3 |
| 2 | USA | WLD | 2000 | 농산물 | 2 |
| 3 | All | WLD | 2000 | 자동차 | 8 |
| 4 | All | WLD | 2000 | 농산물 | 2 |
# 'trade_value를 x_i_k'로
df['x_i_k'] = df['trade_value']
# 각 reporter와 year별, 모든 제품에 대한 수출액 합계: sum_i_x_i_k
df['sum_i_x_i_k'] = df.groupby(['reporter', 'year'])['x_i_k'].transform('sum')
# 연도별로, reporter가 "All"인 행에서(만) temp1 생성 (즉, 해당 product의 세계 수출액)
df['temp1'] = np.where(df['reporter'] == "All", df['x_i_k'], np.nan)
# 연도와 product별로 temp1의 최댓값을 구해, 해당 product의 세계 수출액(temp2) 산출
df['temp2'] = df.groupby(['year', 'product'])['temp1'].transform('max')
# 각 reporter와 year별로, 자신이 수출하는 모든 제품에 대한 세계 수출액의 합: sum_i_x_w_k
df['sum_i_x_w_k'] = df.groupby(['reporter', 'year'])['temp2'].transform('sum')
# 연도별로, 모든 제품의 세계 수출액 합계: sum_w_x_w_k
df['sum_w_x_w_k'] = df.groupby('year')['temp1'].transform('sum')
# Intensive margin: im_i = (자국의 수출액 합계) / (해당 국가가 수출하는 제품의 세계 수출액 합계)
df['im_i'] = df['sum_i_x_i_k'] / df['sum_i_x_w_k']
# Extensive margin: em_i = (해당 국가가 수출하는 제품의 세계 수출액 합계) / (전세계 수출액 합계)
df['em_i'] = df['sum_i_x_w_k'] / df['sum_w_x_w_k']
# 결과 확인
df
| reporter | partner | year | product | trade_value | x_i_k | sum_i_x_i_k | temp1 | temp2 | sum_i_x_w_k | sum_w_x_w_k | im_i | em_i | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | KOR | WLD | 2000 | 자동차 | 5 | 5 | 5 | NaN | 8.0 | 8.0 | 10.0 | 0.625 | 0.8 |
| 1 | USA | WLD | 2000 | 자동차 | 3 | 3 | 5 | NaN | 8.0 | 10.0 | 10.0 | 0.500 | 1.0 |
| 2 | USA | WLD | 2000 | 농산물 | 2 | 2 | 5 | NaN | 2.0 | 10.0 | 10.0 | 0.500 | 1.0 |
| 3 | All | WLD | 2000 | 자동차 | 8 | 8 | 10 | 8.0 | 8.0 | 10.0 | 10.0 | 1.000 | 1.0 |
| 4 | All | WLD | 2000 | 농산물 | 2 | 2 | 10 | 2.0 | 2.0 | 10.0 | 10.0 | 1.000 | 1.0 |
3. 제품 기준 IM & EM 계산 사례#
데이터#
2000년 161개국
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 데이터 불러오기
df = pd.read_stata("../Data/comtrade_exports_all_countries_2000.dta")
df
| reporter | reporter_name | partner | partner_name | year | product_name | flow_name | trade_value | product | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | AIA | Anguila | WLD | World | 2000 | Bananas, including plantains, fresh | Gross Exp. | 0.346000 | 080300 |
| 1 | AIA | Anguila | WLD | World | 2000 | Coconut copra oil (excl. crude) and | Gross Exp. | 2.240000 | 151319 |
| 2 | AIA | Anguila | WLD | World | 2000 | Margarine (excl. liquid) | Gross Exp. | 3.332000 | 151710 |
| 3 | AIA | Anguila | WLD | World | 2000 | Prepared or preserved fish (excl. m | Gross Exp. | 0.001000 | 160419 |
| 4 | AIA | Anguila | WLD | World | 2000 | Mixtures of juices, unfermented, no | Gross Exp. | 1.252000 | 200990 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 358866 | ZWE | Zimbabwe | WLD | World | 2000 | Original engravings, prints and lit | Gross Exp. | 1.230000 | 970200 |
| 358867 | ZWE | Zimbabwe | WLD | World | 2000 | Original sculptures and statuary, i | Gross Exp. | 5650.151855 | 970300 |
| 358868 | ZWE | Zimbabwe | WLD | World | 2000 | Used postage or revenue stamps and | Gross Exp. | 0.003000 | 970400 |
| 358869 | ZWE | Zimbabwe | WLD | World | 2000 | Coll & coll pce of zoo,bot,mineral, | Gross Exp. | 10756.884766 | 970500 |
| 358870 | ZWE | Zimbabwe | WLD | World | 2000 | Antiques of an age exceeding one hu | Gross Exp. | 0.358000 | 970600 |
358871 rows × 9 columns
변수 설명
reporter: 무역 거래를 보고한 국가의 코드reporter_name: 무역 거래를 보고한 국가의 이름partner: 거래 상대국의 코드 (WLD는 전세계)partner_name: 거래 상대국의 이름year: 무역 거래가 발생한 연도product_name: 제품 이름flow_name: 무역 흐름의 유형(Gross Exp.는 총수출)trade_value: 거래 금액product: 상품 분류 코드
df['reporter'].unique()
array(['AIA', 'ALB', 'All', 'AND', 'ARG', 'ARM', 'ATG', 'AUS', 'AUT',
'AZE', 'BDI', 'BEL', 'BEN', 'BFA', 'BGD', 'BGR', 'BHR', 'BHS',
'BLR', 'BLZ', 'BOL', 'BRA', 'BRB', 'BWA', 'CAF', 'CAN', 'CHE',
'CHL', 'CHN', 'CIV', 'CMR', 'COL', 'COM', 'CPV', 'CRI', 'CUB',
'CYP', 'CZE', 'DEU', 'DMA', 'DNK', 'DZA', 'ECU', 'EGY', 'ESP',
'EST', 'ETH', 'EUN', 'FIN', 'FJI', 'FRA', 'FRO', 'GAB', 'GBR',
'GEO', 'GHA', 'GIN', 'GMB', 'GRC', 'GRD', 'GRL', 'GTM', 'GUY',
'HKG', 'HND', 'HRV', 'HUN', 'IDN', 'IND', 'IRL', 'IRN', 'ISL',
'ISR', 'ITA', 'JAM', 'JOR', 'JPN', 'KAZ', 'KEN', 'KGZ', 'KHM',
'KNA', 'KOR', 'KWT', 'LBN', 'LCA', 'LSO', 'LTU', 'LUX', 'LVA',
'MAC', 'MAR', 'MDA', 'MDG', 'MDV', 'MEX', 'MKD', 'MLI', 'MLT',
'MNG', 'MOZ', 'MRT', 'MSR', 'MUS', 'MWI', 'MYS', 'MYT', 'NAM',
'NCL', 'NER', 'NGA', 'NIC', 'NLD', 'NOR', 'NPL', 'NZL', 'OMN',
'PAN', 'PER', 'PHL', 'PNG', 'POL', 'PRT', 'PRY', 'PYF', 'QAT',
'ROM', 'RUS', 'SAU', 'SDN', 'SEN', 'SER', 'SGP', 'SLV', 'STP',
'SUR', 'SVK', 'SVN', 'SWE', 'SWZ', 'SYC', 'TCA', 'TGO', 'THA',
'TKM', 'TON', 'TTO', 'TUN', 'TUR', 'TWN', 'TZA', 'UGA', 'UKR',
'URY', 'USA', 'VCT', 'VEN', 'VNM', 'ZAF', 'ZMB', 'ZWE'],
dtype=object)
보고국 중에 나라가 아닌 All(세계 전체), EUN(유럽연합)이 포함돼있는 것에 유의해야 함(IM & EM 계산 코드 작성에서).
IM & EM 계산#
# 'trade_value를 x_i_k'로
df['x_i_k'] = df['trade_value']
# 각 reporter와 year별, 모든 제품에 대한 수출액 합계: sum_i_x_i_k
df['sum_i_x_i_k'] = df.groupby(['reporter', 'year'])['x_i_k'].transform('sum')
# 연도별로, reporter가 "All"인 행에서(만) temp1 생성 (즉, 해당 product의 세계 수출액)
df['temp1'] = np.where(df['reporter'] == "All", df['x_i_k'], np.nan)
# 연도와 product별로 temp1의 최댓값을 구해, 해당 product의 세계 수출액(temp2) 산출
df['temp2'] = df.groupby(['year', 'product'])['temp1'].transform('max')
# 각 reporter와 year별로, 자신이 수출하는 모든 제품에 대한 세계 수출액의 합: sum_i_x_w_k
df['sum_i_x_w_k'] = df.groupby(['reporter', 'year'])['temp2'].transform('sum')
# 연도별로, 모든 제품의 세계 수출액 합계: sum_w_x_w_k('x_i_k'가 아닌 'temp1'을 합쳐야 함)
df['sum_w_x_w_k'] = df.groupby('year')['temp1'].transform('sum')
# Intensive margin: im_i = (자국의 수출액 합계) / (해당 국가가 수출하는 제품의 세계 수출액 합계)
df['im_i'] = df['sum_i_x_i_k'] / df['sum_i_x_w_k']
# Extensive margin: em_i = (해당 국가가 수출하는 제품의 세계 수출액 합계) / (전세계 수출액 합계)
df['em_i'] = df['sum_i_x_w_k'] / df['sum_w_x_w_k']
# 데이터 확인
df.tail()
| reporter | reporter_name | partner | partner_name | year | product_name | flow_name | trade_value | product | x_i_k | sum_i_x_i_k | temp1 | temp2 | sum_i_x_w_k | sum_w_x_w_k | im_i | em_i | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 358866 | ZWE | Zimbabwe | WLD | World | 2000 | Original engravings, prints and lit | Gross Exp. | 1.230000 | 970200 | 1.230000 | 1924812.875 | NaN | 1.737249e+05 | 4.551984e+09 | 5.946530e+09 | 0.000423 | 0.765486 |
| 358867 | ZWE | Zimbabwe | WLD | World | 2000 | Original sculptures and statuary, i | Gross Exp. | 5650.151855 | 970300 | 5650.151855 | 1924812.875 | NaN | 7.558062e+05 | 4.551984e+09 | 5.946530e+09 | 0.000423 | 0.765486 |
| 358868 | ZWE | Zimbabwe | WLD | World | 2000 | Used postage or revenue stamps and | Gross Exp. | 0.003000 | 970400 | 0.003000 | 1924812.875 | NaN | 1.566295e+05 | 4.551984e+09 | 5.946530e+09 | 0.000423 | 0.765486 |
| 358869 | ZWE | Zimbabwe | WLD | World | 2000 | Coll & coll pce of zoo,bot,mineral, | Gross Exp. | 10756.884766 | 970500 | 10756.884766 | 1924812.875 | NaN | 3.472393e+05 | 4.551984e+09 | 5.946530e+09 | 0.000423 | 0.765486 |
| 358870 | ZWE | Zimbabwe | WLD | World | 2000 | Antiques of an age exceeding one hu | Gross Exp. | 0.358000 | 970600 | 0.358000 | 1924812.875 | NaN | 2.053812e+06 | 4.551984e+09 | 5.946530e+09 | 0.000423 | 0.765486 |
결과 요약#
# 필요한 변수만 선택 및 중복 제거
df_sector = df[['reporter', 'year', 'im_i', 'em_i']].drop_duplicates()
# 백분율로 환산
df_sector['im_i'] = df_sector['im_i'] * 100
df_sector['em_i'] = df_sector['em_i'] * 100
print("=== Sectoral Decomposition Summary ===")
print(df_sector.describe())
=== Sectoral Decomposition Summary ===
year im_i em_i
count 161.0 161.000000 161.000000
mean 2000.0 1.402866 61.412716
std 0.0 8.043442 29.487625
min 2000.0 0.000124 0.169205
25% 2000.0 0.021842 36.418358
50% 2000.0 0.074172 62.131310
75% 2000.0 0.581469 89.974213
max 2000.0 100.000000 100.000000
4. 시장 기준 IM & EM 계산 사례#
데이터#
# UNCTAD (2012) 원래 데이터세트가 용량이 너무 큼
# BilateralTrade.dta 파일 불러오기
BilateralTrade = pd.read_stata("../Data/BilateralTrade.dta")
BilateralTrade = BilateralTrade[BilateralTrade['year'] > 2000]
BilateralTrade.to_csv("../Data/BilateralTrade.csv")
# BilateralTrade.csv 파일 불러오기
df = pd.read_csv("../Data/BilateralTrade.csv")
df
| Unnamed: 0 | ccode | pcode | year | isic2_3d | imp_tv | imp_q | imp_uv | exp_tv | exp_q | exp_uv | id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | ABW | AIA | 2002 | 311 | 0.000 | NaN | NaN | 773.574 | 433812.0 | 1.783201 | 1.0 |
| 1 | 1 | ABW | AIA | 2003 | 311 | 0.000 | NaN | NaN | 63.463 | 50000.0 | 1.269260 | 1.0 |
| 2 | 2 | ABW | ALB | 2004 | 351 | 8.452 | 11125.0 | NaN | 0.000 | NaN | NaN | 2.0 |
| 3 | 3 | ABW | ALB | 2004 | 352 | 1.363 | 1312.0 | NaN | 0.000 | NaN | NaN | 3.0 |
| 4 | 28 | ABW | ARE | 2003 | 311 | 0.000 | NaN | NaN | 79.050 | 127609.0 | NaN | 10.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1189499 | 5563250 | ZWE | ZMB | 2002 | 385 | 52.346 | NaN | NaN | 518.514 | NaN | NaN | 545571.0 |
| 1189500 | 5563251 | ZWE | ZMB | 2004 | 385 | 46.147 | 942.0 | 48.988320 | 121.252 | 19096.0 | 6.206012 | 545571.0 |
| 1189501 | 5563265 | ZWE | ZMB | 2001 | 390 | 61.541 | NaN | NaN | 7.266 | NaN | NaN | 545572.0 |
| 1189502 | 5563266 | ZWE | ZMB | 2002 | 390 | 32.965 | NaN | NaN | 720.208 | NaN | NaN | 545572.0 |
| 1189503 | 5563267 | ZWE | ZMB | 2004 | 390 | 51.433 | 18167.0 | 2.831122 | 195.610 | 127486.0 | 1.534365 | 545572.0 |
1189504 rows × 12 columns
df['year'].unique()
array([2002, 2003, 2004, 2001], dtype=int64)
변수 설명
ccode: 보고국 코드pcode: 상대국(파트너) 코드year: 연도isic2_3d: 국제표준산업분류(ISIC)의 3자리 코드imp_tv: 수입 무역 가치(import trade value)imp_q: 수입 수량(import quantity)imp_uv: 수입 단위 가치(import unit value)exp_tv: 수출 무역 가치(export trade value)exp_q: 수출 수량(export quantity)exp_uv: 수출 단위 가치(export unit value)
IM & EM 계산#
# (collapse) reporter, pcode, year별로 exp_tv, imp_tv의 합계 계산
df = df.groupby(['ccode', 'pcode', 'year'], as_index=False)[['exp_tv', 'imp_tv']].sum()
# x_i_d = exp_tv (각 행에서 정의)
df['x_i_d'] = df['exp_tv']
# 각 ccode, year별로, 해당 국가(ccode)가 모든 목적지에 대해 수출한 exp_tv 합계: sum_i_x_i_d
df['sum_i_x_i_d'] = df.groupby(['ccode', 'year'])['exp_tv'].transform('sum')
# 각 pcode, year별로, 해당 목적지에 대해 전세계의 exp_tv 합계: x_w_d
df['x_w_d'] = df.groupby(['pcode', 'year'])['exp_tv'].transform('sum')
# 각 ccode, year별로, 자신이 수출한 각 목적지의 x_w_d 합계: sum_i_x_w_d
df['sum_i_x_w_d'] = df.groupby(['ccode', 'year'])['x_w_d'].transform('sum')
# 연도별로, 전세계 모든 목적지에 대한 exp_tv 합계: sum_w_x_w_d
df['sum_w_x_w_d'] = df.groupby('year')['exp_tv'].transform('sum')
# 데이터 확인
df.tail()
| ccode | pcode | year | exp_tv | imp_tv | x_i_d | sum_i_x_i_d | x_w_d | sum_i_x_w_d | sum_w_x_w_d | |
|---|---|---|---|---|---|---|---|---|---|---|
| 85671 | ZWE | ZAR | 2002 | 20254.741 | 131.937 | 20254.741 | 1512363.342 | 646382.879 | 5.037634e+09 | 5.192053e+09 |
| 85672 | ZWE | ZAR | 2004 | 9353.682 | 227.687 | 9353.682 | 886468.378 | 919016.986 | 6.976600e+09 | 7.205177e+09 |
| 85673 | ZWE | ZMB | 2001 | 9792.664 | 12135.245 | 9792.664 | 423323.647 | 832394.133 | 4.882801e+09 | 5.044125e+09 |
| 85674 | ZWE | ZMB | 2002 | 175256.749 | 17891.871 | 175256.749 | 1512363.342 | 938409.948 | 5.037634e+09 | 5.192053e+09 |
| 85675 | ZWE | ZMB | 2004 | 59845.738 | 18475.594 | 59845.738 | 886468.378 | 1168250.907 | 6.976600e+09 | 7.205177e+09 |
결과 요약#
# Geographical margins:
# Extensive margin (em_i_geo) = sum_i_x_w_d / sum_w_x_w_d
# Intensive margin (im_i_geo) = sum_i_x_i_d / sum_w_x_w_d
df['em_i_geo'] = df['sum_i_x_w_d'] / df['sum_w_x_w_d']
df['im_i_geo'] = df['sum_i_x_i_d'] / df['sum_w_x_w_d']
# 필요한 변수만 선택 및 중복 제거
df_geo = df[['ccode', 'year', 'im_i_geo', 'em_i_geo']].drop_duplicates()
# 백분율로 환산
df_geo['im_i_geo'] = df_geo['im_i_geo'] * 100
df_geo['em_i_geo'] = df_geo['em_i_geo'] * 100
print("=== Geographical Decomposition Summary ===")
print(df_geo.describe())
=== Geographical Decomposition Summary ===
year im_i_geo em_i_geo
count 576.000000 576.000000 576.000000
mean 2002.397569 0.694444 95.994293
std 1.100163 1.762331 5.154997
min 2001.000000 0.000000 52.361689
25% 2001.000000 0.005416 95.758290
50% 2002.000000 0.033377 97.642437
75% 2003.000000 0.360029 98.684235
max 2004.000000 13.005763 99.936176
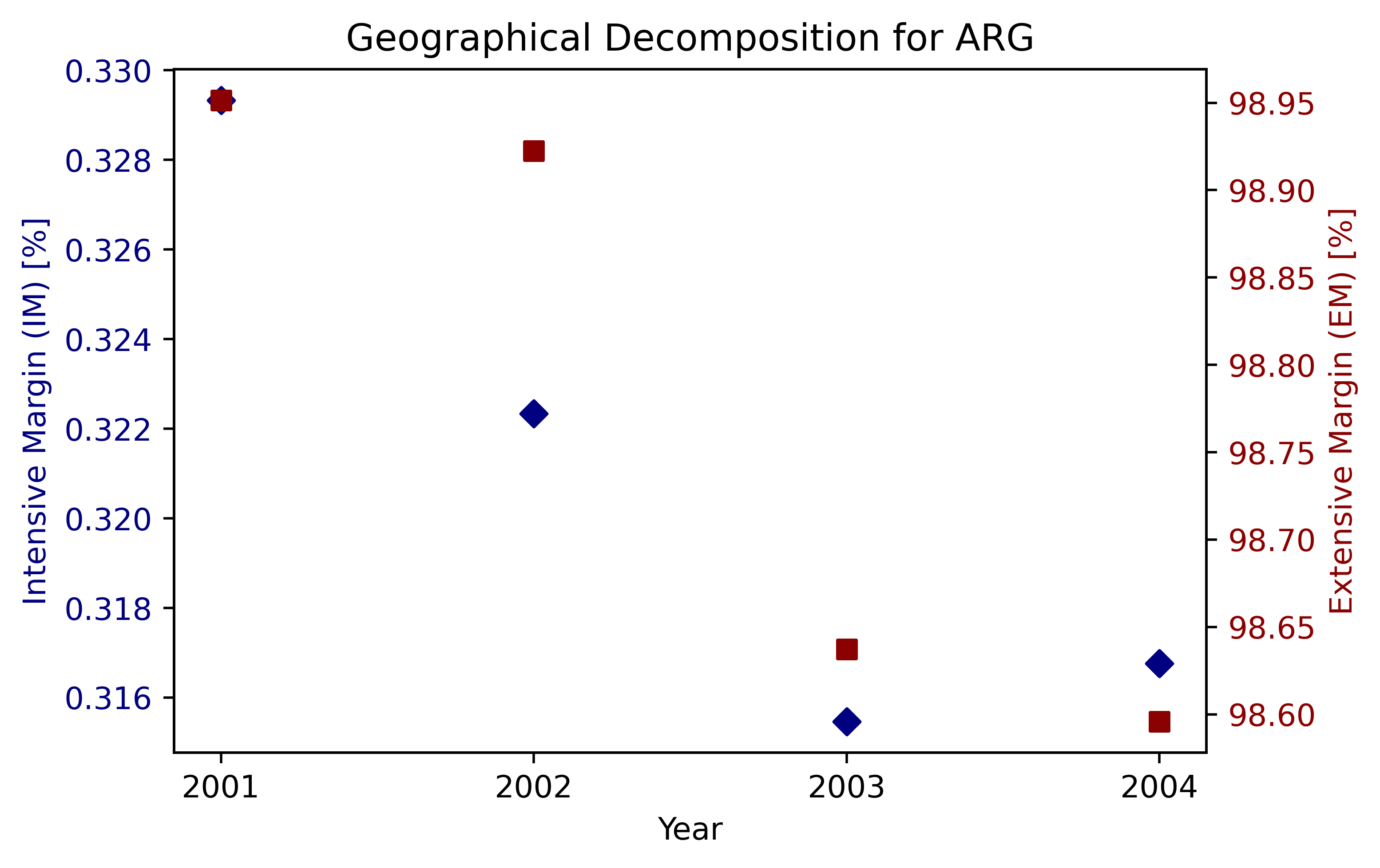
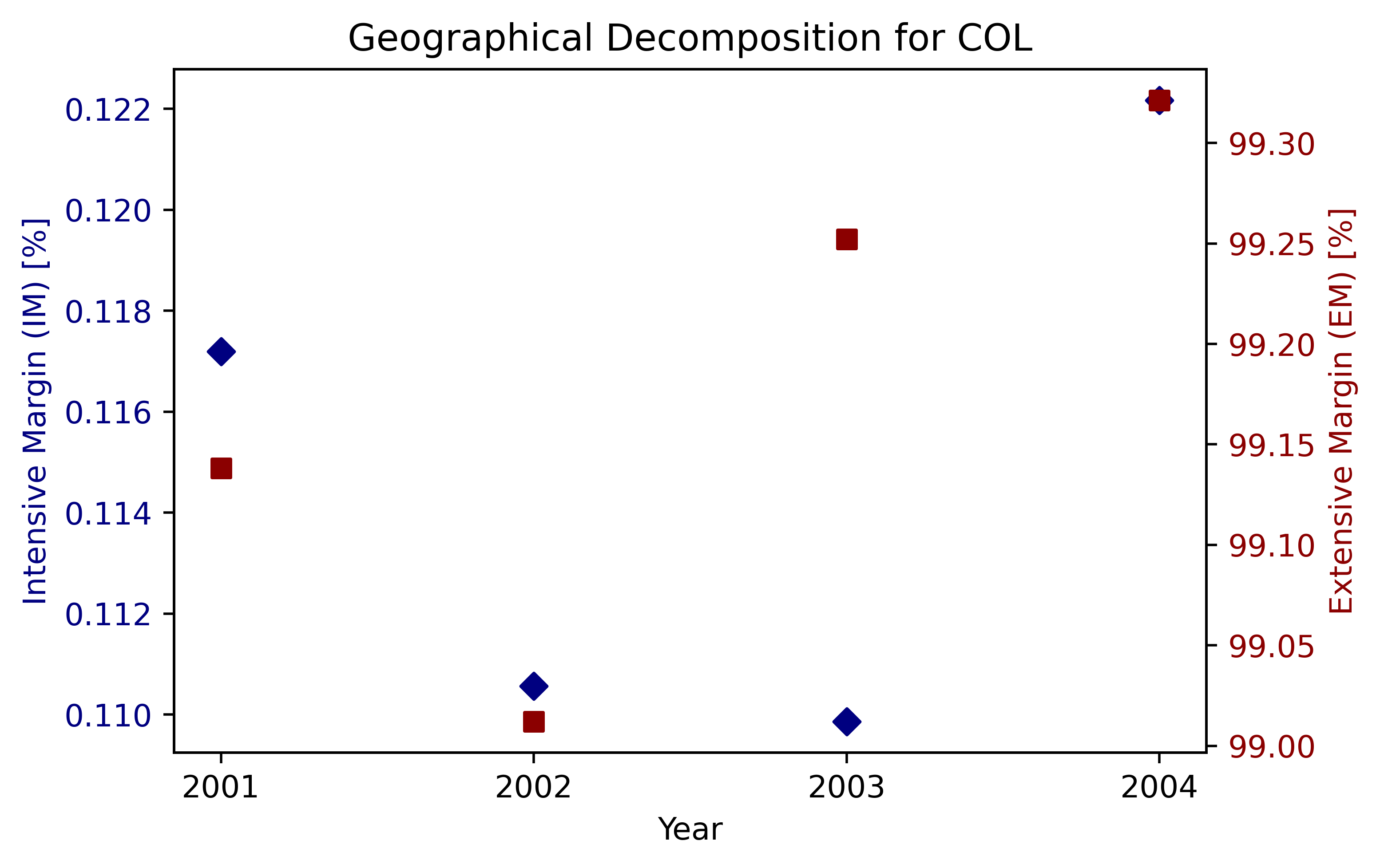
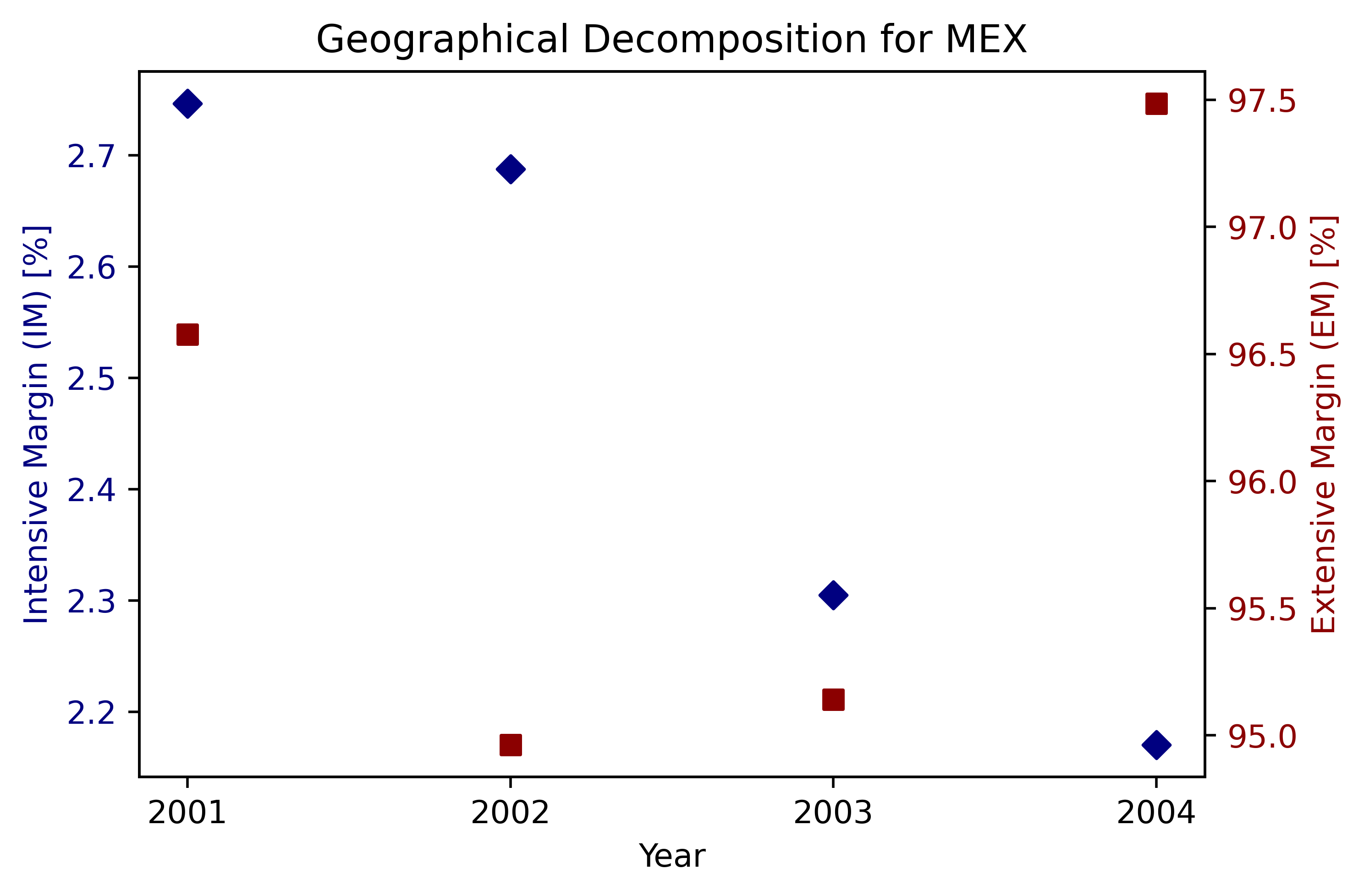
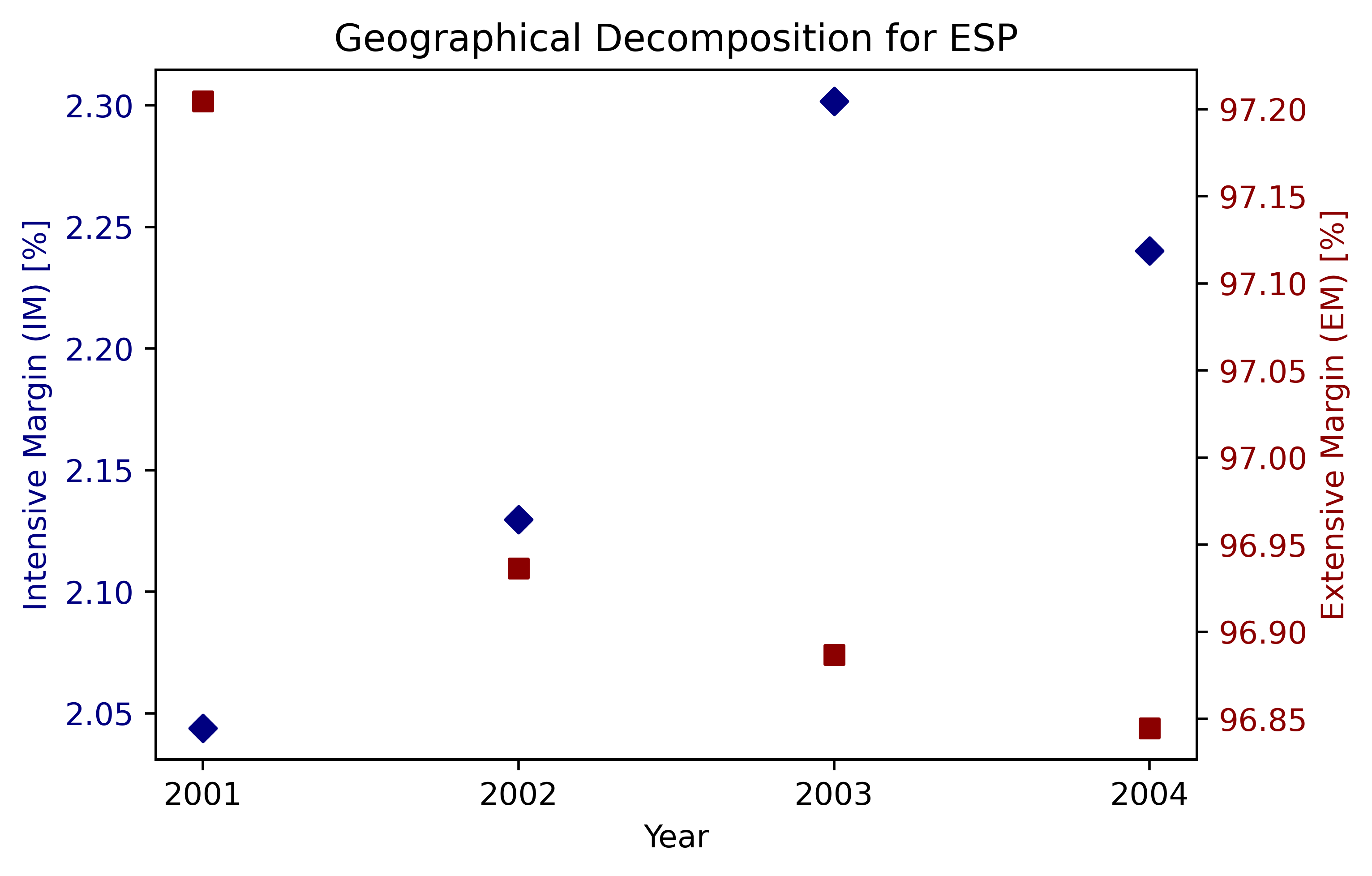
4개국(ARG, COL, MEX, ESP) 결과 그림#
countries = ['ARG', 'COL', 'MEX', 'ESP']
for country in countries:
subset = df_geo[df_geo['ccode'] == country]
if not subset.empty:
fig, ax1 = plt.subplots(figsize=(6, 4), dpi=500)
ax1.scatter(subset['year'], subset['im_i_geo'], marker='D', color='navy', label="IM")
ax1.set_xlabel("Year")
ax1.set_ylabel("Intensive Margin (IM) [%]", color='navy')
ax1.tick_params(axis='y', labelcolor='navy')
# Set x-ticks to only those years present in the subset
ax1.set_xticks(sorted(subset['year'].unique()))
ax2 = ax1.twinx()
ax2.scatter(subset['year'], subset['em_i_geo'], marker='s', color='darkred', label="EM")
ax2.set_ylabel("Extensive Margin (EM) [%]", color='darkred')
ax2.tick_params(axis='y', labelcolor='darkred')
plt.title(f"Geographical Decomposition for {country}")
plt.show()