4장 자동차 수출입을 동시에 한다#
출처: UNCTAD (2012), A Practical Guide to Trade Policy Analysis, Chapter 1.
1. 산업내무역#
정의#
산업내무역(IIT: Intra-industry trade)이란 한 나라가 동일한 산업에서 비슷한 제품을 동시에 수출하고 수입하는 무역 형태를 의미한다. 예를 들어, 독일이 프랑스로 자동차를 수출하면서 동시에 프랑스로부터 자동차를 수입하는 경우가 이에 해당한다.
많은 나라에서, 높은 수준의 통계적 세분화가 이루어진 경우에도 동일한 산업 내에서 상당한 비중의 국제 무역이 발생한다. 산업내무역의 정도를 측정하는 대표적인 지표는 Grubel-Lloyd(GL) 지수다. 이 지수는 다음과 같이 정의된다.
여기서, \(X^{ij}_k\)는 상품(또는 산업) \(k\)에서 \(i\)국이 \(j\)국으로 수출하는 금액이며, \(M^{ij}_k\)는 해당 상품의 수입 금액이다. GL 지수는 \(0\)에서 \(1\) 사이의 값을 갖는다. 특정 산업에서 한 나라가 오직 수출국이거나 수입국일 경우, 분자가 분모와 같아지므로 GL 지수는 \(0\)이 되어 산업내무역이 존재하지 않음을 의미한다. 반면, 동일한 산업에서 한 나라가 수출과 수입을 모두 수행하면, GL 지수는 0이 아니다. 산업내무역이 많을수록 GL 지수는 1에 가까워진다.
소득 수렴과 산업내무역#
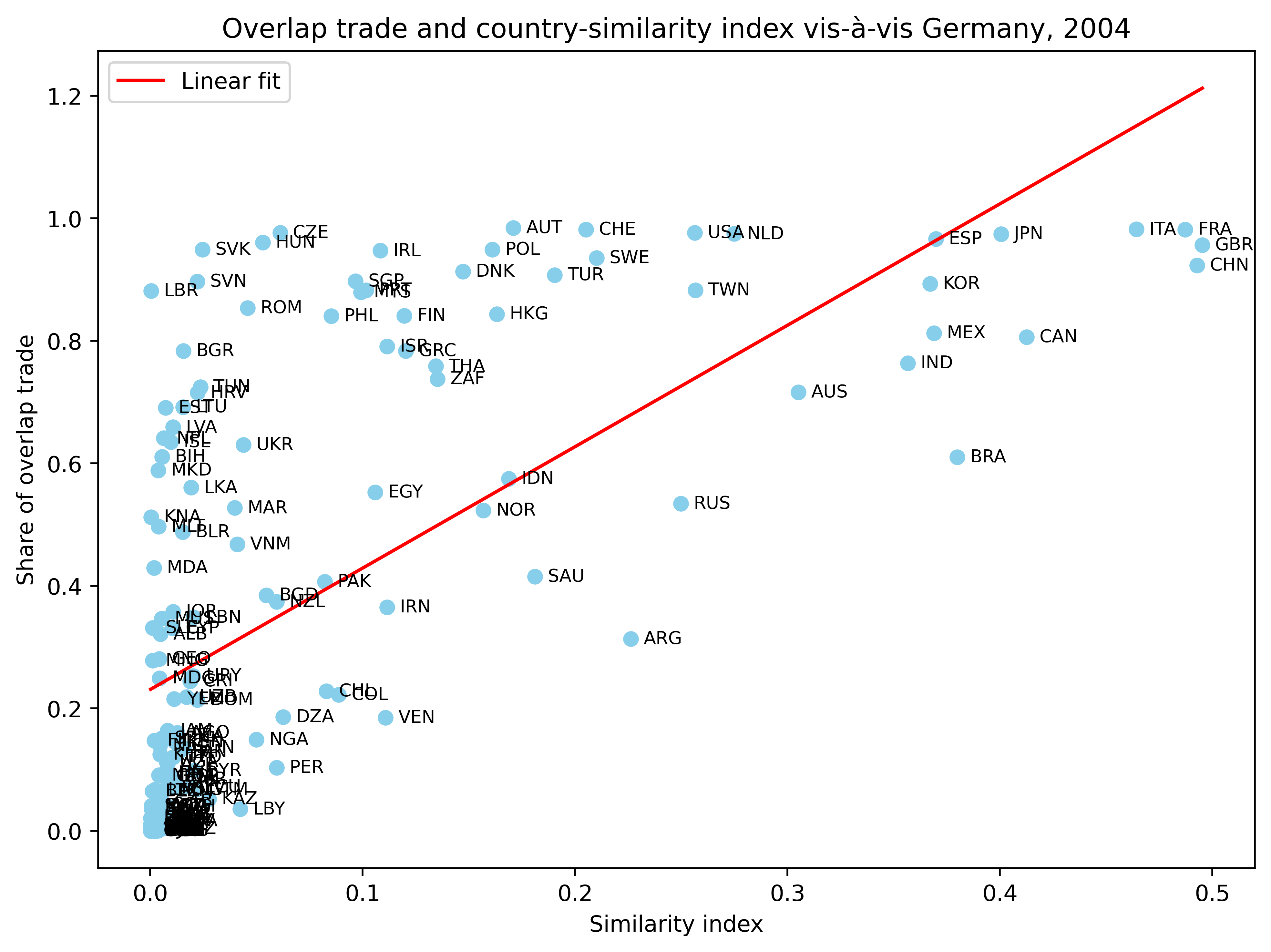
유사한 경제 규모(즉, GDP가 비슷한 나라들)일수록 산업내무역의 비중이 더 높아지는 경향이 있다. 이를 확인하기 위해 아래에서는 실제 데이터를 사용해 2004년 독일과 그 무역 상대국들 간의 무역중복 비중(share of overlap trade)과 유사성 지수(similarity index) 간의 관계를 산점도로 그린다. Helpman (1987)에 따라 유사성 지수는 다음과 같이 정의된다.
여기서, GDP는 실질값(real terms)이다.
한편, 무역중복 비중은 양방향 무역(즉, GL 지수 \(>\) 0)을 보이는 제품(HS 6자리 기준)의 수출입 합계를 전체 수출입 합계로 나눈 값으로 정의된다. 결국, 무역중복 비중은 산업내무역의 정도를 나라 전체적으로 평가한 것이다.
아래 결과에서 볼 수 있듯이, 독일과 1인당 GDP 수준이 유사한 국가일수록 무역중복 비중이 더 높다.
소득 수렴이 산업내무역을 촉진하는 이유 중 하나는 저소득 국가들이 고소득 국가를 따라잡으면서 동일한 유형의 제품을 생산하게 되기 때문이다. 기술 수준이 향상되면서, 차별화된 유사 상품의 교역(수평적 무역)이 증가하는데, 이는 독점적 경쟁 모델(monopolistic competition model) 과 일치하는 무역 구조를 형성한다. Krugman의 독점적 경쟁 모델(Monopolistic Competition Model)에서는 기업들이 차별화된 제품을 생산하며, 국가 간 무역이 서로 다른 품질이나 디자인의 유사한 제품(예: 독일과 일본이 자동차를 서로 교역) 간에 이루어질 수 있음을 설명한다.
경제통합과 산업내무역#
산업내무역 지수가 상승하는 또 다른 이유는 경제 통합이 진행되면서 수직적 무역(vertical trade)이 증가하기 때문이다. 예를 들어, 독일이 체코 공화국에 자동차 부품(엔진, 변속기, 브레이크 모듈 등)을 수출하고, 체코가 이를 조립하여 다시 독일로 완성차를 수출하는 경우를 생각해보자. 만약 GL 지수를 자동차 산업 전체(HS 2자리 수준)에서 계산하면, 독일과 체코 간의 자동차 부문 산업내무역이 상당히 높은 것으로 나타날 것이다. 그러나 이는 사실상 헥셔-올린(Heckscher-Ohlin) 무역, 즉 체코의 낮은 노동 비용(조립 공정은 부품 제조보다 노동집약적이므로, 비교우위에 따라 체코에서 조립하는 것이 더 효율적임)에 의해 발생하는 현상으로서 소득 수렴이나 독점적 경쟁과 직접적인 관련이 없다.
한편, GL 지수는 해석에 주의가 필요한데, 집계 수준이 높아질수록 GL 지수가 상승하는 경향이 있다. 이는 데이터가 세분화될수록 GL 지수는 낮아지는 것을 의미한다. 따라서 GL 지수를 비교할 때는 유사한 수준의 집계를 사용해야 한다.
2. 독일 사례 분석#
독일 2004년 유사성 지수 계산#
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# UNCTAD (2012) 원래 데이터세트가 용량이 너무 큼
# GravityData.dta 파일 불러오기
gravity = pd.read_stata("../Data/GravityData.dta")
# 필요한 변수만 유지
gravity = gravity[['ccode', 'pcode', 'year', 'cgdp_c2000', 'pgdp_c2000']]
gravity = gravity.drop_duplicates()
# CSV 파일로 저장
gravity.to_csv("../Data/GravityData1.csv")
# GravityData.csv 파일 불러오기
gravity = pd.read_csv("../Data/GravityData1.csv")
gravity
| Unnamed: 0 | ccode | pcode | year | cgdp_c2000 | pgdp_c2000 | |
|---|---|---|---|---|---|---|
| 0 | 0 | AGO | ARG | 1985 | 7.220000e+09 | 1.870000e+11 |
| 1 | 2 | AGO | AUS | 1985 | 7.220000e+09 | 2.360000e+11 |
| 2 | 4 | AGO | AUT | 1985 | 7.220000e+09 | 1.280000e+11 |
| 3 | 25 | AGO | BDI | 1985 | 7.220000e+09 | 6.730000e+08 |
| 4 | 26 | AGO | BEN | 1978 | NaN | 9.540000e+08 |
| ... | ... | ... | ... | ... | ... | ... |
| 259914 | 3950210 | ZWE | ZMB | 1999 | 7.570000e+09 | 3.130000e+09 |
| 259915 | 3950211 | ZWE | ZMB | 2000 | 7.200000e+09 | 3.240000e+09 |
| 259916 | 3950212 | ZWE | ZMB | 2001 | 6.600000e+09 | 3.400000e+09 |
| 259917 | 3950213 | ZWE | ZMB | 2002 | 6.230000e+09 | 3.510000e+09 |
| 259918 | 3950214 | ZWE | ZMB | 2004 | NaN | 3.860000e+09 |
259919 rows × 6 columns
# temp1, temp2 계산 및 유사성 지수(simil_index) 생성
gravity['temp1'] = gravity['cgdp_c2000'] / (gravity['cgdp_c2000'] + gravity['pgdp_c2000'])
gravity['temp2'] = gravity['pgdp_c2000'] / (gravity['cgdp_c2000'] + gravity['pgdp_c2000'])
gravity['simil_index'] = 1 - gravity['temp1']**2 - gravity['temp2']**2
# 필요한 변수만 유지하고, 2004년 및 ccode가 "DEU"인 행만 선택
sim_index = gravity[['ccode', 'pcode', 'year', 'simil_index']]
sim_index = sim_index[(sim_index['year'] == 2004) & (sim_index['ccode'] == "DEU")]
sim_index = sim_index.sort_values(by=['ccode', 'pcode', 'year'])
# 데이터 확인
sim_index
| ccode | pcode | year | simil_index | |
|---|---|---|---|---|
| 54195 | DEU | ABW | 2004 | NaN |
| 54222 | DEU | AFG | 2004 | NaN |
| 54249 | DEU | AGO | 2004 | 0.012751 |
| 54276 | DEU | ALB | 2004 | 0.004862 |
| 54303 | DEU | ARG | 2004 | 0.226260 |
| ... | ... | ... | ... | ... |
| 58325 | DEU | YEM | 2004 | 0.011226 |
| 58366 | DEU | ZAF | 2004 | 0.135191 |
| 58393 | DEU | ZAR | 2004 | 0.005078 |
| 58420 | DEU | ZMB | 2004 | 0.004005 |
| 58445 | DEU | ZWE | 2004 | NaN |
173 rows × 4 columns
독일 2004년 HS6 무역 데이터#
# germany_trade_2004_hs6.dta 파일 불러오기
germany_trade = pd.read_stata("../Data/germany_trade_2004_hs6.dta")
germany_trade
| nomen | reporter | reporter_name | partner | partner_name | year | product | product_name | flow_name | trade_value | rownum | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | H0 | DEU | Germany | ABW | Aruba | 2004 | Total | Total Trade | Gross Exp. | 4674 | 1 |
| 1 | H0 | DEU | Germany | ABW | Aruba | 2004 | Total | Total Trade | Gross Imp. | 5536 | 2 |
| 2 | H0 | DEU | Germany | ABW | Aruba | 2004 | 02 | Meat and edible meat offal | Gross Exp. | 9 | 3 |
| 3 | H0 | DEU | Germany | ABW | Aruba | 2004 | 0206 | Edible offal of bovine animals..., | Gross Exp. | 9 | 4 |
| 4 | H0 | DEU | Germany | ABW | Aruba | 2004 | 020649 | Frozen edible swine offal (excl. li | Gross Exp. | 9 | 5 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 874970 | S1 | DEU | Germany | ZWE | Zimbabwe | 2004 | 9 | Commod. & transacts. not class. acc | Gross Exp. | 779 | 874971 |
| 874971 | S1 | DEU | Germany | ZWE | Zimbabwe | 2004 | 9 | Commod. & transacts. not class. acc | Gross Imp. | 102 | 874972 |
| 874972 | S1 | DEU | Germany | ZWE | Zimbabwe | 2004 | 94 | Animals, nes, incl. zoo animals, do | Gross Imp. | 102 | 874973 |
| 874973 | S1 | DEU | Germany | ZWE | Zimbabwe | 2004 | 941 | Animals, nes-incl.zoo animals,dogs | Gross Imp. | 102 | 874974 |
| 874974 | S1 | DEU | Germany | ZWE | Zimbabwe | 2004 | 9410 | Animals,n.e.s. | Gross Imp. | 102 | 874975 |
874975 rows × 11 columns
# 변수명 변경: reporter -> ccode, partner -> pcode
germany_trade = germany_trade.rename(columns={'reporter': 'ccode', 'partner': 'pcode'})
# 'nomen' 변수 삭제 (존재하지 않으면 무시)
germany_trade = germany_trade.drop(columns=['nomen'], errors='ignore')
# flow_name 수정: "Gross Exp." → "Exports", "Gross Imp." → "Imports"
germany_trade['flow_name'] = germany_trade['flow_name'].replace({
"Gross Exp.": "Exports",
"Gross Imp.": "Imports"
})
# product 변수의 공백 제거 후 재명명
germany_trade['a'] = germany_trade['product'].str.strip()
germany_trade = germany_trade.drop(columns=['product'])
germany_trade = germany_trade.rename(columns={'a': 'product'})
# product가 "Total" 인 행 삭제 및 product 길이가 6 이상인 행만 유지
germany_trade = germany_trade[germany_trade['product'] != "Total"]
germany_trade = germany_trade[germany_trade['product'].str.len() >= 6]
# 'rownum' 변수 삭제 (존재하지 않으면 무시)
germany_trade = germany_trade.drop(columns=['rownum'], errors='ignore')
# 데이터를 wide 형태로 피벗: index = (ccode, pcode, year, product), columns = flow_name, values = trade_value
overlap_temp = germany_trade.pivot_table(index=['ccode', 'pcode', 'year', 'product'],
columns='flow_name',
values='trade_value',
aggfunc='first').reset_index()
# 데이터 확인
overlap_temp
| flow_name | ccode | pcode | year | product | Exports | Imports |
|---|---|---|---|---|---|---|
| 0 | DEU | ABW | 2004 | 020649 | 9.0 | NaN |
| 1 | DEU | ABW | 2004 | 040110 | 20.0 | NaN |
| 2 | DEU | ABW | 2004 | 040120 | 213.0 | NaN |
| 3 | DEU | ABW | 2004 | 110710 | 9.0 | NaN |
| 4 | DEU | ABW | 2004 | 121020 | 7.0 | NaN |
| ... | ... | ... | ... | ... | ... | ... |
| 321069 | DEU | ZWE | 2004 | 960899 | 1.0 | NaN |
| 321070 | DEU | ZWE | 2004 | 961210 | 8.0 | NaN |
| 321071 | DEU | ZWE | 2004 | 970110 | 5.0 | NaN |
| 321072 | DEU | ZWE | 2004 | 970300 | NaN | 139.0 |
| 321073 | DEU | ZWE | 2004 | 970400 | NaN | 7.0 |
321074 rows × 6 columns
Overlap Trade 계산 및 유사성 지수와 병합#
# 각 (pcode, product) 단위에서 Grubel–Lloyd 지수 계산
# GL = 1 - (|Exports - Imports| / (Exports + Imports))
overlap_temp['gl_i_j_k'] = 1 - (np.abs(overlap_temp['Exports'] - overlap_temp['Imports']) /
(overlap_temp['Exports'] + overlap_temp['Imports']))
# 결측치(NaN)가 발생하면 0으로 대체
overlap_temp['gl_i_j_k'] = overlap_temp['gl_i_j_k'].fillna(0)
# pcode별로 총 Exports, 총 Imports 합계 계산
overlap_temp['x1'] = overlap_temp.groupby('pcode')['Exports'].transform('sum')
overlap_temp['x2'] = overlap_temp.groupby('pcode')['Imports'].transform('sum')
overlap_temp['denom'] = overlap_temp['x1'] + overlap_temp['x2']
overlap_temp['dd'] = overlap_temp.groupby('pcode')['denom'].transform('max')
# pcode별, gl_i_j_k > 0 인 경우에 한해 Exports, Imports 합계 계산
overlap_temp['x11'] = overlap_temp.groupby('pcode')['Exports'].transform(lambda x: x.where(overlap_temp['gl_i_j_k'] > 0).sum())
overlap_temp['x22'] = overlap_temp.groupby('pcode')['Imports'].transform(lambda x: x.where(overlap_temp['gl_i_j_k'] > 0).sum())
overlap_temp['numer'] = overlap_temp['x11'] + overlap_temp['x22']
overlap_temp['nn'] = overlap_temp.groupby('pcode')['numer'].transform('max')
# Overlap Trade 지수 계산: overlap = nn / dd
overlap_temp['overlap'] = overlap_temp['nn'] / overlap_temp['dd']
# 최종적으로 ccode, pcode, year, overlap만 남기기
overlap_final = overlap_temp[['ccode', 'pcode', 'year', 'overlap']]
# ccode, pcode, year 기준으로 유사성 지수와 outer merge
overlap_merged = pd.merge(overlap_final, sim_index, on=['ccode', 'pcode', 'year'], how='outer', indicator=True)
# 중복 행 제거
overlap_merged = overlap_merged.drop_duplicates()
# 데이터 확인
overlap_merged
| ccode | pcode | year | overlap | simil_index | _merge | |
|---|---|---|---|---|---|---|
| 0 | DEU | ABW | 2004 | 0.021219 | NaN | both |
| 340 | DEU | AFG | 2004 | 0.099273 | NaN | both |
| 1186 | DEU | AGO | 2004 | 0.159785 | 0.012751 | both |
| 1844 | DEU | AIA | 2004 | 0.036243 | NaN | left_only |
| 2094 | DEU | ALB | 2004 | 0.321109 | 0.004862 | both |
| ... | ... | ... | ... | ... | ... | ... |
| 314956 | DEU | YEM | 2004 | 0.215132 | 0.011226 | both |
| 315921 | DEU | ZAF | 2004 | 0.737773 | 0.135191 | both |
| 319191 | DEU | ZAR | 2004 | 0.027718 | 0.005078 | both |
| 319982 | DEU | ZMB | 2004 | 0.027383 | 0.004005 | both |
| 320401 | DEU | ZWE | 2004 | 0.072978 | NaN | both |
230 rows × 6 columns
그래프: Overlap Trade와 유사성 지수#
# 분석을 위해 필요한 데이터만 (simil_index와 overlap 값이 존재하는) 선택
plot_data = overlap_merged.dropna(subset=['simil_index', 'overlap'])
# 산점도와 선형 회귀선 (linear fit) 그리기
plt.figure(figsize=(8,6), dpi=500)
plt.scatter(plot_data['simil_index'], plot_data['overlap'], color='skyblue')
# 각 데이터 포인트에 pcode 레이블 표시
offset = 0.006 # 필요에 따라 조정
for idx, row in plot_data.iterrows():
plt.text(row['simil_index'] + offset, row['overlap'], str(row['pcode']), fontsize=8, va='center')
# 선형 회귀선 계산 및 플롯
coeffs = np.polyfit(plot_data['simil_index'], plot_data['overlap'], 1)
x_fit = np.linspace(plot_data['simil_index'].min(), plot_data['simil_index'].max(), 100)
y_fit = np.polyval(coeffs, x_fit)
plt.plot(x_fit, y_fit, color='red', label="Linear fit")
plt.xlabel("Similarity index")
plt.ylabel("Share of overlap trade")
plt.title("Overlap trade and country-similarity index vis-à-vis Germany, 2004")
plt.legend()
plt.tight_layout()
plt.show()
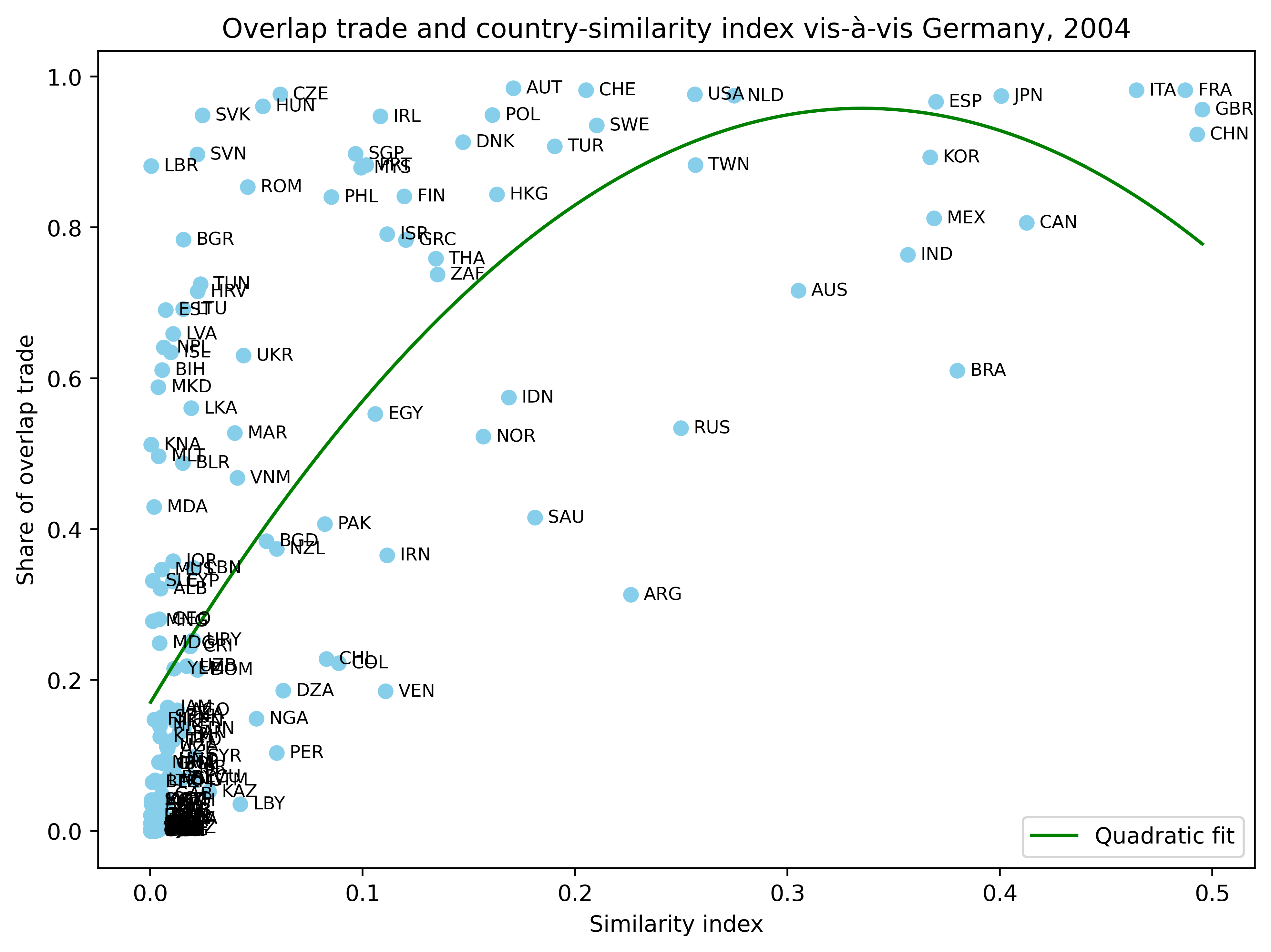
# 2차식(quadratic fit) 회귀선을 그린 그래프
plt.figure(figsize=(8,6), dpi=500)
plt.scatter(plot_data['simil_index'], plot_data['overlap'], color='skyblue')
# 각 데이터 포인트에 pcode 레이블 표시
offset = 0.006 # 필요에 따라 조정
for idx, row in plot_data.iterrows():
plt.text(row['simil_index'] + offset, row['overlap'], str(row['pcode']),
fontsize=8, va='center')
quad_coeffs = np.polyfit(plot_data['simil_index'], plot_data['overlap'], 2)
y_quad = np.polyval(quad_coeffs, x_fit)
plt.plot(x_fit, y_quad, color='green', label="Quadratic fit")
plt.xlabel("Similarity index")
plt.ylabel("Share of overlap trade")
plt.title("Overlap trade and country-similarity index vis-à-vis Germany, 2004")
plt.legend()
plt.tight_layout()
plt.show()
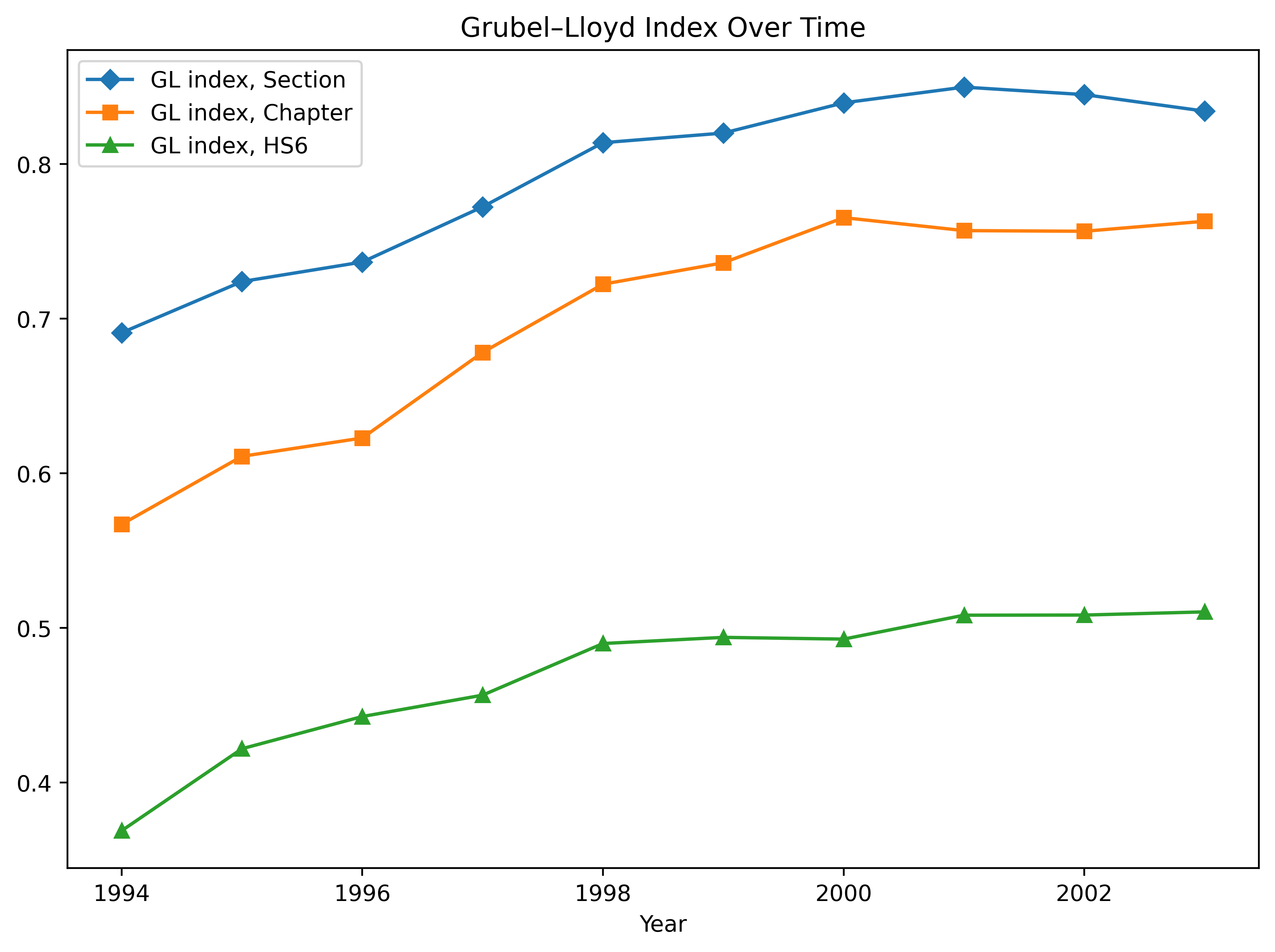
3. 집계 수준별 산업내무역 지수#
Grubel-Lloyd(GL) 지수는 산업내무역의 정도를 측정하는 유용한 지표지만, 이 지수는 집계 수준에 따라 민감하게 변동하는 문제가 있다. 아래에서는 유럽연합(EU) 국가들의 GL 지수를 세 가지 다른 집계 수준에서 계산한다.(모든 목적지로부터의 수출 및 수입 데이터를 사용함.)
계산 결과를 보면, 더 높은 수준에서 집계할수록 GL 지수가 더 높아지는 경향을 보인다.
예시 데이터#
GL 지수가 집계 수준이 높아질수록 기계적으로 증가하는 이유를 이해하기 위해, 아래 예시 데이터를 생각해보자. 이 표는 독일이 체코에 자동차 엔진과 기어박스를 수출하고, 체코에서 이를 조립하여 자동차를 다시 독일로 수출하는 상황을 나타낸다.
소호(subheading) 수준(표의 첫 두 행)에서는 “자동차 부품(Car parts)”과 “조립된 자동차(Assembled cars)”가 서로 다른 상품이므로, 산업내무역은 0이다(마지막 열). 반면, 류(chapter) 수준에서는 “자동차 부품”과 “조립된 자동차” 모두 HS 코드 87에 속하므로 산업내무역이 0.75의 아주 높은 양(+)의 값을 가지게 된다.
일반적으로, 집계 수준이 낮을수록 산업내무역의 측정값이 낮게 나타난다. 이러한 값들은 실제 산업내무역 수준에 더 가까우며, 반면 높은 집계 수준에서의 높은 값들은 통계적 착시(statistical illusion)에 불과할 수 있다.
항목 |
수출(X) |
수입(M) |
abs(X - M) |
X + M |
GL |
|---|---|---|---|---|---|
자동차 부품 |
600 |
600 |
600 |
0 |
|
조립된 자동차 |
1000 |
1000 |
1000 |
0 |
|
류(chapter) 87 |
1000 |
600 |
400 |
1600 |
0.75 |
EU 데이터#
유럽연합 전체의 GL 지수를 산업 또는 제품 수준의 무역 비중을 가중치로 하여 집계하는 방식으로 계산한다. 이는 총수출 및 총수입을 사용하는 방식보다 바람직하다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 데이터 불러오기: trade_6digit.dta
df = pd.read_stata("../Data/trade_6digit.dta")
df
| year | product | exp_eu | exp_wl | imp_eu | imp_wl | ce | |
|---|---|---|---|---|---|---|---|
| 0 | 1994 | 10111 | 511536.0 | 634545.0 | 614444.0 | 834992.0 | 1.0 |
| 1 | 1994 | 10119 | 1196798.0 | 1319424.0 | 29344.0 | 53345.0 | 1.0 |
| 2 | 1994 | 10120 | 626.0 | 3688.0 | NaN | NaN | 1.0 |
| 3 | 1994 | 10210 | 26890988.0 | 27184104.0 | 11267391.0 | 11899005.0 | 1.0 |
| 4 | 1994 | 10290 | 10615080.0 | 17989604.0 | NaN | 5420297.0 | 1.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 276973 | 2003 | 970200 | NaN | 5328.0 | 35299.0 | 57861.0 | 6.0 |
| 276974 | 2003 | 970300 | NaN | 603.0 | 8828.0 | 21932.0 | 6.0 |
| 276975 | 2003 | 970400 | 110704.0 | 153890.0 | 17090.0 | 73842.0 | 6.0 |
| 276976 | 2003 | 970500 | NaN | 4674.0 | NaN | 55986.0 | 6.0 |
| 276977 | 2003 | 970600 | 9880.0 | 9880.0 | 35726.0 | 36939.0 | 6.0 |
276978 rows × 7 columns
변수 설명
year: 연도product: 제품 코드(HS)exp_eu: 유럽(EU)으로의 수출액exp_wl: 세계(World)로의 수출액imp_eu: 유럽(EU)으로부터의 수입액imp_wl: 세계(World)로부터의 수입액ce: 특정 조건을 나타내는 변수 (1.0은 특정 조건 충족 여부를 의미할 가능성이 있음)
HS1 수준 집계#
# 변수 'product'를 'hs6'로 변경
df = df.rename(columns={"product": "hs6"})
# hs6 값을 기준으로 'section' 변수 생성
conditions = [
df['hs6'] < 60000,
(df['hs6'] >= 60000) & (df['hs6'] < 150000),
(df['hs6'] >= 150000) & (df['hs6'] < 160000),
(df['hs6'] >= 160000) & (df['hs6'] < 250000),
(df['hs6'] >= 250000) & (df['hs6'] < 280000),
(df['hs6'] >= 280000) & (df['hs6'] < 390000),
(df['hs6'] >= 390000) & (df['hs6'] < 410000),
(df['hs6'] >= 410000) & (df['hs6'] < 440000),
(df['hs6'] >= 440000) & (df['hs6'] < 470000),
(df['hs6'] >= 470000) & (df['hs6'] < 500000),
(df['hs6'] >= 500000) & (df['hs6'] < 640000),
(df['hs6'] >= 640000) & (df['hs6'] < 680000),
(df['hs6'] >= 680000) & (df['hs6'] < 710000),
(df['hs6'] >= 710000) & (df['hs6'] < 720000),
(df['hs6'] >= 720000) & (df['hs6'] < 840000),
(df['hs6'] >= 840000) & (df['hs6'] < 860000),
(df['hs6'] >= 860000) & (df['hs6'] < 900000),
(df['hs6'] >= 900000) & (df['hs6'] < 930000),
(df['hs6'] >= 930000) & (df['hs6'] < 940000),
(df['hs6'] >= 940000) & (df['hs6'] < 970000),
(df['hs6'] >= 970000) & (df['hs6'] < 980000),
(df['hs6'] >= 980000)
]
choices = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22]
df['section'] = np.select(conditions, choices, default=0)
# 연도와 section별로 수출 및 수입 금액 합계 집계
df_sector = df.groupby(['year', 'section'], as_index=False)\
[['exp_eu', 'exp_wl', 'imp_eu', 'imp_wl']].sum()
df_sector
| year | section | exp_eu | exp_wl | imp_eu | imp_wl | |
|---|---|---|---|---|---|---|
| 0 | 1994 | 1 | 1.322055e+09 | 2.058855e+09 | 6.486129e+08 | 1.154001e+09 |
| 1 | 1994 | 2 | 9.500778e+08 | 1.629440e+09 | 8.465851e+08 | 2.135366e+09 |
| 2 | 1994 | 3 | 4.727788e+07 | 2.211453e+08 | 2.317530e+08 | 3.649722e+08 |
| 3 | 1994 | 4 | 7.571672e+08 | 2.586353e+09 | 1.596599e+09 | 3.100346e+09 |
| 4 | 1994 | 5 | 2.510219e+09 | 4.543348e+09 | 1.353761e+09 | 1.019264e+10 |
| ... | ... | ... | ... | ... | ... | ... |
| 205 | 2003 | 17 | 2.156628e+10 | 2.903545e+10 | 1.808135e+10 | 2.473098e+10 |
| 206 | 2003 | 18 | 2.037365e+09 | 2.851254e+09 | 3.068689e+09 | 5.123016e+09 |
| 207 | 2003 | 19 | 2.580094e+07 | 8.836896e+07 | 4.645092e+07 | 8.103078e+07 |
| 208 | 2003 | 20 | 8.358265e+09 | 1.073537e+10 | 2.579269e+09 | 4.472797e+09 |
| 209 | 2003 | 21 | 1.396499e+07 | 3.580712e+07 | 7.220165e+07 | 9.039225e+07 |
210 rows × 6 columns
# Grubel–Lloyd 지수 계산:
df_sector['gl_eu'] = 1 - (np.abs(df_sector['exp_eu'] - df_sector['imp_eu']) /
(df_sector['exp_eu'] + df_sector['imp_eu']))
df_sector['gl_wl'] = 1 - (np.abs(df_sector['exp_wl'] - df_sector['imp_wl']) /
(df_sector['exp_wl'] + df_sector['imp_wl']))
# 연도별로 exp_eu 가중평균을 이용해 gl_eu 계산
df_gl_section = df_sector.groupby('year')[['gl_eu', 'exp_eu']].apply(
lambda g: np.average(g['gl_eu'], weights=g['exp_eu'])
).reset_index(name='gl_eu_section')
df_gl_section
| year | gl_eu_section | |
|---|---|---|
| 0 | 1994 | 0.690926 |
| 1 | 1995 | 0.724051 |
| 2 | 1996 | 0.736687 |
| 3 | 1997 | 0.772390 |
| 4 | 1998 | 0.813877 |
| 5 | 1999 | 0.820110 |
| 6 | 2000 | 0.839653 |
| 7 | 2001 | 0.849829 |
| 8 | 2002 | 0.844976 |
| 9 | 2003 | 0.834292 |
HS6 수준 집계#
# 데이터 다시 불러오기
df_hs6 = pd.read_stata("../Data/trade_6digit.dta")
# 연도와 product 수준에서 합계 집계
df_hs6 = df_hs6.groupby(['year', 'product'], as_index=False)\
[['exp_eu', 'exp_wl', 'imp_eu', 'imp_wl']].sum()
# GL 지수 계산
df_hs6['gl_eu'] = 1 - (np.abs(df_hs6['exp_eu'] - df_hs6['imp_eu']) /
(df_hs6['exp_eu'] + df_hs6['imp_eu']))
df_hs6['gl_wl'] = 1 - (np.abs(df_hs6['exp_wl'] - df_hs6['imp_wl']) /
(df_hs6['exp_wl'] + df_hs6['imp_wl']))
# 연도별 exp_eu 가중평균으로 gl_eu 계산
df_gl_hs6 = df_hs6.groupby('year')[['gl_eu', 'exp_eu']].apply(
lambda g: np.average(
g['gl_eu'].dropna(),
weights=g['exp_eu'][g['gl_eu'].notna()]
)
).reset_index(name='gl_eu_hs6')
df_gl_hs6
| year | gl_eu_hs6 | |
|---|---|---|
| 0 | 1994 | 0.368801 |
| 1 | 1995 | 0.421852 |
| 2 | 1996 | 0.442684 |
| 3 | 1997 | 0.456525 |
| 4 | 1998 | 0.489915 |
| 5 | 1999 | 0.493899 |
| 6 | 2000 | 0.492769 |
| 7 | 2001 | 0.508242 |
| 8 | 2002 | 0.508331 |
| 9 | 2003 | 0.510380 |
HS2 수준 집계#
# 데이터 다시 불러오기
df_hs2 = pd.read_stata("../Data/trade_6digit.dta")
# a = int(product/10000) 계산
df_hs2['a'] = (df_hs2['product'] // 10000).astype(int)
# product 변수 삭제
df_hs2 = df_hs2.drop(columns=['product'])
# 연도와 a(HS2 digit)별로 합계 집계
df_hs2 = df_hs2.groupby(['year', 'a'], as_index=False)\
[['exp_eu', 'exp_wl', 'imp_eu', 'imp_wl']].sum()
# GL 지수 계산
df_hs2['gl_eu'] = 1 - (np.abs(df_hs2['exp_eu'] - df_hs2['imp_eu']) /
(df_hs2['exp_eu'] + df_hs2['imp_eu']))
df_hs2['gl_wl'] = 1 - (np.abs(df_hs2['exp_wl'] - df_hs2['imp_wl']) /
(df_hs2['exp_wl'] + df_hs2['imp_wl']))
# 연도별 exp_eu 가중평균으로 gl_eu 계산
df_gl_chapter = df_hs2.groupby('year')[['gl_eu', 'exp_eu']].apply(
lambda g: np.average(g['gl_eu'], weights=g['exp_eu'])
).reset_index(name='gl_eu_chapter')
df_gl_chapter
| year | gl_eu_chapter | |
|---|---|---|
| 0 | 1994 | 0.566985 |
| 1 | 1995 | 0.611008 |
| 2 | 1996 | 0.622856 |
| 3 | 1997 | 0.678234 |
| 4 | 1998 | 0.722344 |
| 5 | 1999 | 0.736181 |
| 6 | 2000 | 0.765399 |
| 7 | 2001 | 0.757010 |
| 8 | 2002 | 0.756582 |
| 9 | 2003 | 0.763069 |
GL 지수 그래프 작성#
# 세 GL 지수 파일(Section, HS6, Chapter)을 'year' 기준으로 병합
df_gl = df_gl_chapter.merge(df_gl_hs6, on='year', how='outer')\
.merge(df_gl_section, on='year', how='outer')
# GL 지수를 연도별로 선 그래프로 출력
plt.figure(figsize=(8,6), dpi=500)
plt.plot(df_gl['year'], df_gl['gl_eu_section'], marker='D', label="GL index, Section")
plt.plot(df_gl['year'], df_gl['gl_eu_chapter'], marker='s', label="GL index, Chapter")
plt.plot(df_gl['year'], df_gl['gl_eu_hs6'], marker='^', label="GL index, HS6")
plt.xlabel("Year")
plt.title("Grubel–Lloyd Index Over Time")
plt.legend(ncol=1)
plt.tight_layout()
plt.show()