6장 관세 데이터 기초 분석#
출처: UNCTAD (2012), A Practical Guide to Trade Policy Analysis, Chapter 2.
1. 관세#
관세란?#
무역 정책(Trade policy)은 정부가 국제 무역과 관련하여 채택하는 정책을 의미하며, 다양한 조치와 여러 도구를 활용할 수 있다. 이러한 도구에는 수입 또는 수출에 대한 세금, 국제 거래의 정량적 제한, 보조금, 비관세조치(NTMs) 등 다양한 조치들이 포함된다. 정부는 수입하거나 수출하는 수천 개의 제품에 대해 이러한 조치를 다양한 조합으로 적용한다. 예를 들어, 관세라는 동일한 조치라도 제품에 따라 다른 수준으로 설정되며, 이로 인해 무역에 매우 상이한 영향을 미칠 수 있다.
관세(tariff)는 국경에서 상품의 수입에 부과하는 세금이다. 관세의 효과는 수입 상품의 가격을 세계(국내) 시장 가격보다 높이는 것이다. 관세는 보통 세관 당국에 의해 징수되며 종가세(ad valorem) 또는 종량세(specific)일 수 있다. 종가세는 수입 상품의 가치, 보통 운임보험료 포함(CIF: Cost Insurance and Freight) 수입 가치의 일정 비율로 표시되며, 종량세는 상품 단위당 고정 통화 금액으로 표시된다.
종가세가 종량세보다 훨씬 더 널리 사용된다. 그 이유 중 하나는 집계하고 비교하기가 더 쉬워서 투명성이 높기 때문이다. 이는 특히 국가들이 관세 약속을 협상할 때 중요하다. 종량세는 상품이 측정되는 단위에 따라 다르기 때문에 상품 간 비교가 더 어렵다. 그러나 이를 비교하는 한 가지 방법은 종가세 환산치(ad valorem equivalent)을 계산하는 것이다.
관세 체제의 특징 중 간과해서는 안 되는 점은 최종 용도에 따른 면제(exemption)의 가능성이다. 특수 프로젝트, 수출가공구역(EPZ: export processing zone)에서 특수 지위를 가진 다국적 기업, 국제 기구 등이다. 공식적인 면제 외에도, 정부는 종종 현지 조사에 의해서만 알 수 있는 임시 면제를 부여한다. 면제가 중요할 때, 이를 간과하면 보호율을 과대평가하게 된다.
GATT/WTO와 관련된 두 가지 추가 구분을 고려해야 한다. 첫 번째 구분은 최혜국대우(MFN: most-favoured nation) 관세율과 특혜(preferential) 관세율 간의 차이이다. MFN 관세는 WTO 회원국이 특혜 협정을 체결하지 않은 모든 다른 WTO 회원국의 수입에 대해 부여하기로 약속한 관세이다. 특혜 관세는 자유무역협정(FTA), 관세동맹(customs union) 또는 기타 특혜무역협정(preferential trade agreement)에서 특혜 파트너의 수입에 대해 부여되는 관세로, 다른 관세보다 0에 가까운 경우가 많다.
두 번째 구분은 양허(bound) 관세와 실행(applied) 관세 간의 차이다. 정부가 GATT/WTO에서 관세 인하를 협상할 때, 그들의 약속은 MFN 관세 약정(양허) 형태를 취한다. 양허된 MFN 관세 수준은 국가의 관세율표에 나열돼있으며, 이는 정부가 실행 MFN 관세를 설정하기로 약속한 상한을 나타낸다.
주어진 관세품목(tariff line)에 대해 양허 관세는 실행 MFN 관세보다 높거나 같아야 하며, 특혜 관세가 있는 경우 특혜 관세보다 높거나 같다. 선진국의 경우, 양허 관세는 보통 실행 관세와 동일하거나 매우 가깝다. 그러나 개발도상국의 경우에는 종종 양허 관세가 실행 관세보다 높아 무역 흐름에 제약적인 영향을 미친다.
관세 양허(Concession of Tariff)란 국가 간 관세 적용에 관한 협상에서 협상 당사국이 특정 품목의 관세를 일정 수준 이상으로 부과하지 않겠다고 약속하는 것을 의미한다. 관세 양허의 결과는 당해 국가의 양허 관세율표(Tariff Schedule) 형태로 협정문에 부속시키며, 일단 관세 양허된 품목의 세율에 대해서는 상대방의 동의 없이는 변경할 수 없다.
2. 관세 데이터#
세계 전체의 관세 데이터에 접근할 수 있는 주요 포털은 세 가지며, 비관세조치에 대한 접근은 현재로서는 기본적으로 하나의 포털이 있다.
WTO는 양허 관세, 실행 관세, 특혜 관세에 대한 접근을 두 가지 시스템을 통해 제공한다. Tariff Analysis Online(TAO)과 Tariff Download Facility(TDF)이다. 또한 WTO 회원국들이 통보한 비관세조치(NTM) 정보를 담고있는 다양한 데이터베이스에도 접근할 수 있다.
세계은행 World Integrated Trade Solutions(WITS) 포털은 양허 관세, 실행 관세, 특혜 관세에 대한 접근을 제공하며, 전 세계적으로 유일한 비관세조치(NTM) 데이터베이스(TRAINS)에도 접근할 수 있다.
ITC(International Trade Centre)의 Market Access Map(MAcMap) 포털을 통해 양허, 실행, 특혜 관세와 관세쿼터, 반덤핑 관세, 원산지 규칙에 접근할 수 있다.
모든 세 가지 포털은 무역 데이터에도 접근할 수 있게 해준다. 이 외에도 특정 조치나 특정 부문에 대한 정보를 제공하는 여러 데이터베이스가 온라인에서 접근 가능하다.
WTO의 TAO 및 TDF#
WTO의 TAO(http://tariffanalysis.wto.org/)는 WTO 회원국이 제공하거나 승인한 공식 관세 데이터에 접근할 수 있는 두 가지 인터페이스 중 하나다. 이 관세 데이터는 두 개의 데이터베이스에 저장된다. Integrated Data Base(IDB)와 Consolidated Tariffs Schedules(CTS)이다.
IDB는 WTO 회원국이 WTO에 보고하기로 약속한 관세 및 무역 정보를 저장한다. IDB는 1996년부터 주로 8자리나 때로는 10자리의 관세품목 수준에서 WTO 회원국의 MFN 실행 관세 및 수입 데이터를 담고 있다.
CTS 데이터베이스는 모든 WTO 회원국의 양허 관세를 포함하고 있다. IDB와 동일한 시스템을 통해 무료로 접근할 수 있다.
TAO의 보완으로 TDF(http://tariffdata.wto.org/)가 있으며, 이는 HS 6자리 코드 수준의 정보를 포함한다.
세계은행의 WITS#
WITS(http://wits.worldbank.org/)는 세계은행이 유엔무역개발회의(UNCTAD)와 긴밀히 협력해 개발했다. 이는 다섯 가지 무역 및 관세 데이터베이스에 접근할 수 있게 한다.
WTO의 IDB 및 CTS 데이터베이스
UNSD의 COMTRADE 데이터베이스
UNCTAD의 TRAINS 데이터베이스
CEPII 및 IFPRI의 MAcMapHS6v2 데이터베이스
AMAD 데이터베이스
TRAINS(TRade Analysis and INformation System)는 1988년부터 국가 관세품목 수준에서 MFN(실행) 및 특혜 관세, 비관세조치(NTMs) 및 수입 데이터를 포함하고 있다. NTM 데이터는 공식 데이터 소스에서 수집된다. 이 데이터는 기업 설문조사 및 웹 포털을 통해 수집된 정보로 보완되며, 별도의 데이터베이스에 저장된다.
MAcMap 시스템#
국제무역센터(ITC)와 국제경제연구소(CEPII)가 공동 개발한 데이터베이스로, 실행 MFN 관세 및 특혜 관세, 그리고 WTO의 양허 관세(CTS 데이터베이스)를 관세품목 수준에서 제공한다. 또한, 비종가세(non-ad valorem tariff)를 종가세 환산치(AVE: ad valorem equivalents)로 변환한 정보를 포함하고 있으며, 관세율 쿼터(tariff-rate quota)에 대한 데이터도 포함돼있다(원본 데이터는 AMAD에서 제공).
3. WTO 관세 데이터#
출처: Tariffs: Comprehensive tariff data on the WTO website
TAO와 TDF#
WTO 웹사이트는 회원국의 관세율과 수입(import)에 대한 정보를 제공한다. Tariff Analysis Online (TAO)은 두 개의 데이터베이스를 활용하여 가장 상세한 수준에서 정의된 제품의 관세율, 수입 통계 및 이를 인터랙티브 방식으로 분석할 수 있는 기능을 제공한다. Tariff Download Facility (TDF)는 표준화된 관세 통계를 제공하며, 약간 덜 상세하지만 국가 간 즉각적인 비교가 가능하다.
이 두 서비스 모두에서 사용자는 두 가지 세트의 관세 데이터를 얻고 비교할 수 있다.
법적으로 양허된 관세율 약정, 이는 회원국 정부가 설정할 수 있는 관세의 상한선을 나타내며 “양허율(bound rate)”로 불린다.
실제로 수입에 부과되는 관세율, 이는 더 낮을 수 있으며 “실행율(applied rate)”로 불리며 무역에 직접적인 영향을 미친다.
관세는 “관세품목(tariff line)” 수준(8자리 이상의 HS 코드)에서 제공된다. 이 수준의 세부 정보에서는 국가들이 반드시 동일한 코드 번호로 제품을 정의하는 것은 아니기 때문에 국가 간 비교가 가능하지 않을 수도 있다.
TAO는 데이터 검색과 온라인 분석(관세, 관세쿼터, 수입 및 농업 보조금에 대한 국가 약정 포함)에 대한 다양한 옵션을 제공한다. 결과는 화면에서 확인하거나 다운로드 및 인쇄할 수 있다.
TDF는 더 간단한다. 양허, 실행, 특혜 관세와 수입 통계 데이터는 모든 국가에 표준화된 HS 코드의 최대 6자리까지 제공된다.
TAO 및 TDF는 두 개의 데이터베이스(IDB와 CTS 데이터베이스)를 기반으로 한다. IDB(Integrated Database)는 WTO 회원국과 가입 경제의 수입에 대해 실행된(applied) 관세의 시계열을 포함한다. 데이터는 가장 세부적인 제품 수준(보통 8자리에서 10자리 제품 수준 또는 관세품목 코드)에서 제공된다. 이 데이터베이스에는 수입 통계도 포함되어 있으며, 국가별 원산지 및 관세품목별로 수입의 가치와 양을 포함한다.
CTS(Consolidated Tariff Schedules) 데이터베이스는 WTO 회원국이 다른 WTO 회원국에서 수입된 제품에 부과할 수 있는 합의된 최대 관세(agreed maximum tariff)가 들어있다.
관세 코드와 표준화#
데이터베이스에서 제품(Product)은 세계관세기구(WCO: World Customs Organization)의 국제적으로 합의된 “HS(Harmonized System)”를 사용하여 식별된다.
HS 시스템에서는 가장 넓은 범주의 제품이 두 자리 “류(類: chapter)”로 식별된다(예: 04는 유제품, 계란 및 기타 식용 동물 제품). 그런 다음 자리를 추가하여 세분화된다. 자리 수가 많을수록 카테고리가 더 상세해진다. 예를 들어 4자리 코드 또는 “호(小號; heading)” 0403은 유제품에서 유래한 제품 그룹이다. 6자리에서 0403.10은 요구르트를 위한 “소호(小號; sub-heading)”다. 8자리 수준에서 0403.10.11은 저지방 요구르트 “관세품목”이다.
코드는 6자리까지 표준화되어 있으며, 이는 국제적으로 비교할 수 있는 가장 상세한 수준이다. 이는 TDF에서 사용된다. 그 이후에는 각 국가가 자신의 필요에 따라 자유롭게 정의를 사용할 수 있다.
TAO와 TDF는 모두 MS 엑셀 스프레드시트 및 기타 형식으로 데이터를 다운로드할 수 있다.
4. 관세 프로파일#
관세 프로파일(Tariff Profile)은 특정 국가의 관세 현황과 구조를 요약한 것을 말한다. 대표적으로 다음과 같은 지표들로 구성된다.
지표 |
설명 및 계산 방법 |
|---|---|
양허 범위(binding coverage) |
최소 하나의 양허 관세품목을 포함하는 HS 6자리 소호(subheading)의 비율. full 양허 범위는 소수점 없이 100으로 표시된다. 일부 관세품목이 양허되지 않았지만 결과가 여전히 100으로 반올림된다면, 소수점 한 자리를 유지하여 표시한다(예: 100.0). |
단순평균(Simple average) |
종가세(ad valorem) 또는 AVE(종가세 환산치) HS 6자리 관세 평균의 단순평균. |
무관세(duty-free) 비율 |
제품 그룹 내 소호 총 수에서 무관세 HS 6자리 소호의 비율. 부분적으로 무관세인 소호는 비율에 따라 고려된다. |
비종가 관세(Non-ad valorem duties) |
비종가 관세가 적용되는 HS 6자리 소호의 비율. HS 6자리 소호의 일부에만 비종가 관세가 적용되는 경우 해당 관세품목의 비율이 사용된다. |
관세 > 15% |
종가 관세 또는 AVE가 15%를 초과하는 HS 6자리 소호의 비율. HS 6자리 소호의 일부만 그러한 관세가 적용되는 경우 비율에 따라 계산된다. |
관세 > 3×AVG |
종가 관세 또는 AVE가 국가 평균의 세 배를 초과하는 HS 6자리 소호의 비율. HS 6자리 소호의 일부만 그러한 관세가 적용되는 경우 비율에 따라 계산된다. |
2023년에 아직 실행되지 않은 양허(concessions) |
2023년에 아직 실행되지 않은 HS 6자리 양허 소호의 비율. HS 6자리 소호의 일부만 이러한 관세가 적용되는 경우 비율에 따라 계산된다. |
최고 관세 |
관세품목 수준의 최대 종가 관세 또는 AVE. |
서로 다른 관세율의 수 |
서로 다른 관세율의 수. 비종가 관세는 항상 서로 다르게 취급되며 AVE 계산은 항상 서로 다른 AVE를 산출한다. 그러나 이 지표에서는 제공되지 않은 관세는 포함되지 않다. |
변동계수(coefficient of variation) |
관세품목 관세율의 표준 편차를 모든 관세율의 단순 관세품목 수준 평균으로 나눈 값. 종가 관세 또는 AVE만 포함된다. |
MFN 실행 관세품목의 수 |
총 MFN 실행 관세품목의 수. |
World Tariff Profiles#
World Tariff Profiles 2024: 170개 이상의 국가 및 관세 지역이 부과한 관세 및 비관세조치에 대한 포괄적인 정보를 제공한다. 이는 WTO와 UNCTAD의 공동 출판물이다.
Technical notes
HS 01–97 류(chapter)에 기록된 관세 및 수입만 고려된다. 각 실행 관세율표는 해당 연도의 국가에서 채택한 HS 버전의 HS 6자리 소호 수준의 표준 분류법을 기준으로 검증된다. 이 표준을 따르지 않는 국가 관세품목은 폐기되고 고려되지 않다(즉, 처음 6자리는 국가에서 사용한 HS 버전의 표준 소호 분류법을 기반으로 해야 한다). 반면에 누락된 소호는 추가된다. 따라서 모든 계산은 완전한 표준 분류법을 기반으로 한다. 모든 단순평균은 사전 집계된 HS 6자리 평균을 기반으로 한다. 사전 집계는 관세품목 수준의 관세가 먼저 HS 6자리 소호로 평균화된다는 것을 의미한다. 후속 계산은 이러한 사전 집계된 평균을 기반으로 한다. 가능한 한 비종가 관세는 종가세 환산치로 변환된다.
2024년 한국 관세 프로파일
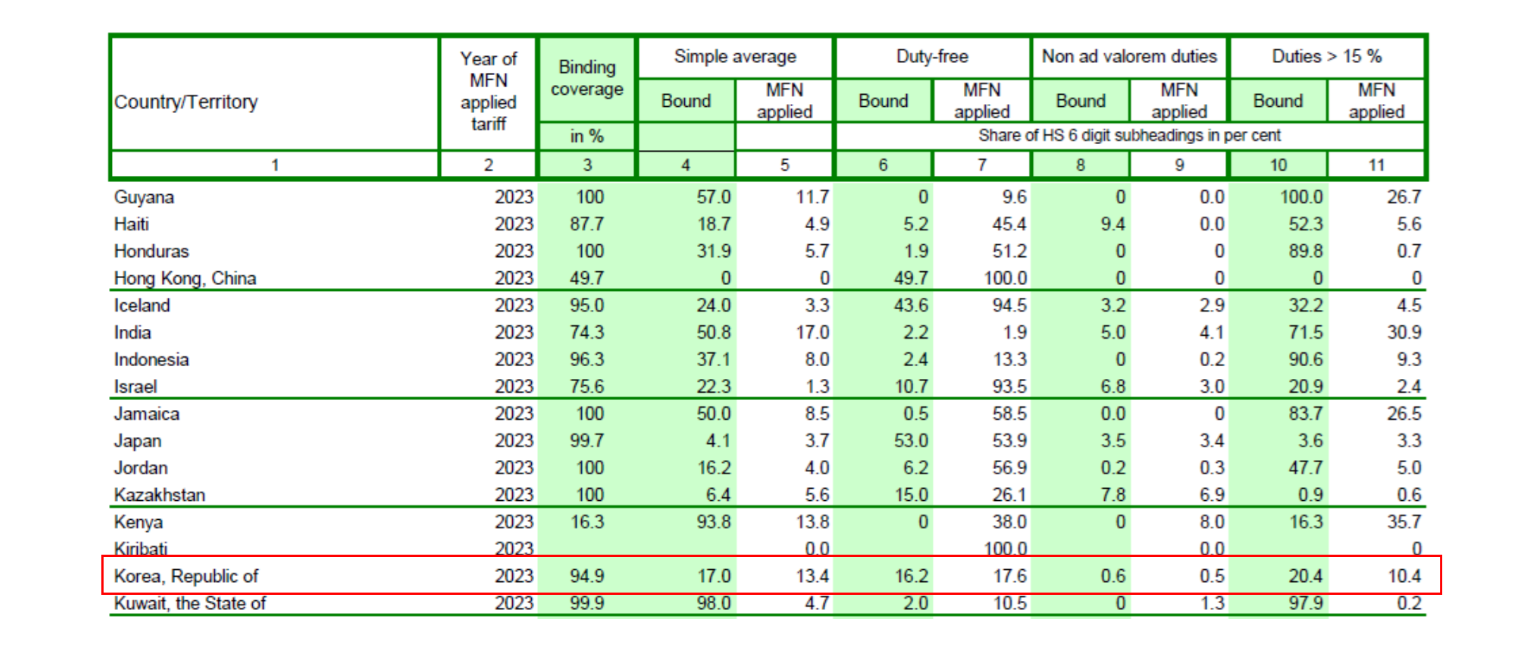
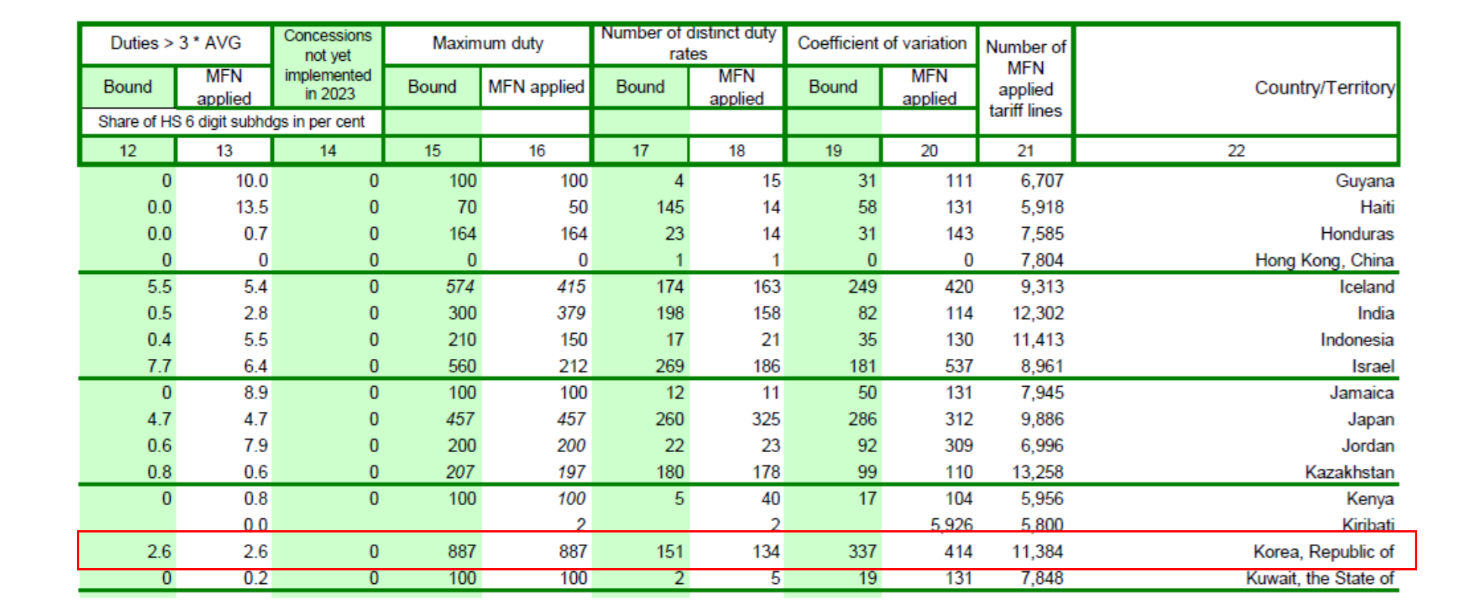
관세 프로파일 용어#
용어 |
설명 |
|---|---|
종가 관세(ad valorem, AV) |
가격의 일정 비율로 부과되는 관세율. |
실행 관세율(applied rates) |
실제로 수입에 부과되는 관세. 이는 양허 관세율보다 낮을 수 있음. |
양허 관세율(bound rates, tariff binding) |
합의된 수준을 초과하여 관세율을 인상하지 않겠다는 약속. 일단 관세율이 양허되면, 영향을 받는 당사자에게 보상을 제공하지 않는 한 인상할 수 없음. |
자리 수준(digit-level) |
제품을 식별하기 위해 사용되는 코드의 참조. 제품 범주는 자리를 추가하여 세분화됨. |
HS 시스템(Harmonized System) |
제품을 식별하기 위해 세계관세기구(WCO: World Customs Organization)에서 사용하는 코드 체계. 코드는 최대 6자리까지 표준화되어 있음. 그 이후에는 국가별로 관세 및 다양한 목적을 위해 국가별 구분을 도입할 수 있음. |
최혜국(MFN, most-favoured-nation) 관세 |
수입품에 부과되는 일반 비차별적 관세(자유무역협정 및 기타 프로그램에 따른 특혜 관세(preferential tariff) 또는 할당내 관세(tariffs charged inside quotas) 제외). |
양허관세율표(tariff schedule) |
(상품에 대한) 양허 관세율 목록. |
관세품목(TL, tariff line) |
관세 코드 체계에 의해 정의된 제품. |
평균 관세율 계산#
관세율표(tariff schedule)는 일반적으로 HS 8자리 수준의 세분화 또는 더 높은 수준(최대 HS 12)으로 정의되며, 주어진 국가에는 항상 5,000개 이상, 종종 그보다 훨씬 많은 관세품목(tariff line)이 있다.
관세는 단순평균 또는 가중치를 사용하는 방식으로 집계할 수 있다. 단순평균은 모든 관세품목의 관세를 다 더해서 그 관세품목 수로 나누어 계산한다. 가중평균의 경우, 다음과 같은 형태를 취한다.
여기서 \(k\)는 수입 상품을 나타내고 \(w_k\)는 관세 \(k\)에 주어진 가중치다. 널리 사용되는 접근 방식은 국가의 전체 수입에서의 해당 상품이 차지하는 비율을 가중치로 사용하는 것이다.
단순평균과 수입-가중평균은 계산하기 상대적으로 쉽다는 장점이 있지만, 이 두 가지 방법 모두 각각의 단점이 있다. 단순평균은 수입되지 않은 제품과 대량으로 수입되는 제품에 동일한 가중치를 부여한다는 문제점이 있다. 수입-가중평균의 경우, 이 편향을 어느 정도 수정하지만 높은 관세를 과소평가하며, 금지적 관세에는 0의 가중치가 부여된다는 문제점이 있다.
5. 사례: 2008년 캐나다 관세 프로파일#
2008년 기준, 캐나다의 양허 관세, 실행 관세, 수입 데이터를 관세품목 수준에서 다운로드한다(CAN_Bounds.dta). 캐나다의 경우, 관세품목은 8자리 또는 경우에 따라 10자리 수준으로 정의된다.
평균 양허관세율#
import pandas as pd
import numpy as np
# Load CAN_Bounds dataset
can_bounds = pd.read_stata("../Data/CAN_Bounds.dta")
# 일부 8자리 관세품목에는 '00', '01', '02', ... 와 같은 하위 품목이 있음.
# 여기서 '00'은 하위 제품의 평균으로서 독립된 품목이 아님.
can_bounds = can_bounds[can_bounds["tls"] != "'00'"] # tls 값이 '00'인 행을 삭제함
can_bounds.shape
(4555, 45)
print(can_bounds.columns)
Index(['queryname', 'basenomenclature', 'productclassification',
'reportercode', 'reporter', 'year', 'productcode', 'tl', 'tls', 'ex',
'certified', 'source', 'bounddutyav', 'bounddutyother',
'bounddutynature', 'boundnaturedescription', 'bounddutybindingstatus',
'boundbindingdescription', 'odcdutyav', 'odcdutyother', 'odcdutynature',
'odcdutynaturedescription', 'odctextualinformation', 'basedutyav',
'basedutyother', 'basedutynature', 'basenaturedescription',
'basedutybindingstatus', 'basebindingdescription', 'specialsafeguard',
'presentinstrument', 'presentinrtext', 'implementationfrom',
'implementationto', 'firstinstrument', 'earlierinrtext', 'v38',
'presenatureodcdutyuctdescription', 'presenatureodcdutyuctcodcduty',
'odcdutyctextualinformation', 'presenatureinstrumenature',
'presenatureinrtext', 'implemenatureationfrom',
'implemenatureationatureo', 'firstatusinstrumenature'],
dtype='object')
농업제품 더미변수 만들기
# Create agricultural product dummy
can_bounds["ag"] = np.where(
can_bounds["productclassification"] == "HS - WTO Agricultural Products Definition", 1, 0
)
HS 6자리 코드 만들기
HS 8자리 코드인
tl변수의 문자열 값을 앞에서부터(맨앞 따옴표부터) 7자리까지 자른 다음, 맨끝에 작은 따옴표(‘)를 추가
# Create hs6 classification
can_bounds["hs6"] = can_bounds["tl"].str[:7] + "'"
비종가세 더미변수 만들기
# Create non ad-valorem duty dummy
can_bounds["nav"] = np.where(can_bounds["bounddutynature"] != "A", 1, 0)
필요 변수만 남기기
# Keep only necessary columns and save the file
can_bounds_new = can_bounds[
["tl", "tls", "ex", "bounddutyav", "bounddutybindingstatus", "nav", "hs6", "ag"]
]
can_bounds_new
| tl | tls | ex | bounddutyav | bounddutybindingstatus | nav | hs6 | ag | |
|---|---|---|---|---|---|---|---|---|
| 0 | '01011000' | 0.0 | B | 0 | '010110' | 1 | ||
| 1 | '01019000' | 0.0 | B | 0 | '010190' | 1 | ||
| 2 | '01021000' | 0.0 | B | 0 | '010210' | 1 | ||
| 3 | '01029010' | 0.0 | B | 0 | '010290' | 1 | ||
| 4 | '01029090' | NaN | B | 1 | '010290' | 1 | ||
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4839 | '54021090' | '01' | Ex01 | 8.0 | B | 0 | '540210' | 0 |
| 4840 | '54022010' | '02' | Ex02 | 8.0 | B | 0 | '540220' | 0 |
| 4841 | '54022090' | '01' | Ex01 | 8.0 | B | 0 | '540220' | 0 |
| 4843 | '54071010' | '02' | Ex02 | 14.0 | B | 0 | '540710' | 0 |
| 4844 | '54076192' | 14.0 | B | 0 | '540761' | 0 |
4555 rows × 8 columns
tl(tariff line): 관세품목 코드. 국가별로 정의된 상세한 코드로, HS 코드보다 더 세부적으로 구성됨.tls(tariff line suffix): 일부 8자리 관세품목에는 ‘00’, ‘01’, ‘02’, … 와 같은 하위 품목이 있음.ex(exception): 특정 품목이 예외 조건에 해당하는지를 나타냄.bounddutyav(bound duty ad valorem): 종가세 양허 관세율(최대 허용 관세율).bounddutybindingstatus(bound duty binding status): 관세 양허 상태. “B”는 양허 관세, 그 외 값은 비양허 상태.nav(non ad valorem): 비종가 관세(예: 특정 금액/중량 등) 더미변수. 값이 1이면 비종가세, 0이면 종가세.hs6(6-digit HS code): HS 코드 체계의 6자리 수준에서의 품목 분류.ag(agriculture): 농업 제품 더미변수. 값이 1이면 농업 제품, 0이면 비농업 제품.
품목별 평균 관세율 계산
우선, 각각의 hs-6 수준과 농업 제품 여부별로 사전 집계를 수행한다. 즉, hs6와 ag의 각 고유 조합에 대해 데이터를 그룹화하여 bounddutyav의 평균값을 계산한다.
# Pre-aggregate at hs6 level
bound_aggregated = (
can_bounds_new.groupby(["hs6", "ag"])["bounddutyav"].mean().reset_index()
)
bound_aggregated
| hs6 | ag | bounddutyav | |
|---|---|---|---|
| 0 | '010110' | 1 | 0.00 |
| 1 | '010190' | 1 | 0.00 |
| 2 | '010210' | 1 | 0.00 |
| 3 | '010290' | 1 | 0.00 |
| 4 | '010310' | 1 | 0.00 |
| ... | ... | ... | ... |
| 2618 | '560210' | 0 | 14.00 |
| 2619 | '560221' | 0 | 9.35 |
| 2620 | '560229' | 0 | 14.00 |
| 2621 | '560290' | 0 | 14.00 |
| 2622 | '560311' | 0 | 14.00 |
2623 rows × 3 columns
전체 및 농업 제품 여부별로 bounddutyav의 평균값 계산
# Compute total, agricultural, and non-agricultural averages
total_avg = bound_aggregated["bounddutyav"].mean()
ag_avg = bound_aggregated.loc[bound_aggregated["ag"] == 1, "bounddutyav"].mean()
nonag_avg = bound_aggregated.loc[bound_aggregated["ag"] == 0, "bounddutyav"].mean()
# Save results to a DataFrame
summary_df = pd.DataFrame(
{
"Summary": ["Simple average final bound"],
"Total": [total_avg],
"Ag": [ag_avg],
"NonAg": [nonag_avg],
}
)
summary_df.round(2)
| Summary | Total | Ag | NonAg | |
|---|---|---|---|---|
| 0 | Simple average final bound | 4.47 | 3.66 | 4.74 |
Binding Coverage#
HS 6단위의 각 품목별로 양허 상태 관세품목의 비율을 계산함.
양허 관세 더미변수 생성
# Make an explicit copy of the DataFrame
can_bounds_new = can_bounds_new.copy()
# Compute binding coverage
can_bounds_new["bind"] = np.where(can_bounds_new["bounddutybindingstatus"] == "B", 1, 0)
can_bounds_new
| tl | tls | ex | bounddutyav | bounddutybindingstatus | nav | hs6 | ag | bind | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | '01011000' | 0.0 | B | 0 | '010110' | 1 | 1 | ||
| 1 | '01019000' | 0.0 | B | 0 | '010190' | 1 | 1 | ||
| 2 | '01021000' | 0.0 | B | 0 | '010210' | 1 | 1 | ||
| 3 | '01029010' | 0.0 | B | 0 | '010290' | 1 | 1 | ||
| 4 | '01029090' | NaN | B | 1 | '010290' | 1 | 1 | ||
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4839 | '54021090' | '01' | Ex01 | 8.0 | B | 0 | '540210' | 0 | 1 |
| 4840 | '54022010' | '02' | Ex02 | 8.0 | B | 0 | '540220' | 0 | 1 |
| 4841 | '54022090' | '01' | Ex01 | 8.0 | B | 0 | '540220' | 0 | 1 |
| 4843 | '54071010' | '02' | Ex02 | 14.0 | B | 0 | '540710' | 0 | 1 |
| 4844 | '54076192' | 14.0 | B | 0 | '540761' | 0 | 1 |
4555 rows × 9 columns
품목별 binding coverage 계산
각 관세품목별로 몇 퍼센트가 양허관세인지를 계산한다.
hs6와ag의 각 고유 조합에 대해 데이터를 그룹화하여 각 그룹 내bind열의 값을 합산하여bind_sum이라는 새 열을 만들고, 각 그룹 내bind열의 값의 개수를 세어bind_count라는 새 열을 만든다.
binding_coverage = can_bounds_new.groupby(["hs6", "ag"]).agg(
bind_sum=("bind", "sum"), bind_count=("bind", "count")
).reset_index()
binding_coverage["BindingCoverage"] = (
binding_coverage["bind_sum"] / binding_coverage["bind_count"] * 100
)
binding_coverage
| hs6 | ag | bind_sum | bind_count | BindingCoverage | |
|---|---|---|---|---|---|
| 0 | '010110' | 1 | 1 | 1 | 100.0 |
| 1 | '010190' | 1 | 1 | 1 | 100.0 |
| 2 | '010210' | 1 | 1 | 1 | 100.0 |
| 3 | '010290' | 1 | 2 | 2 | 100.0 |
| 4 | '010310' | 1 | 1 | 1 | 100.0 |
| ... | ... | ... | ... | ... | ... |
| 2618 | '560210' | 0 | 2 | 2 | 100.0 |
| 2619 | '560221' | 0 | 2 | 2 | 100.0 |
| 2620 | '560229' | 0 | 1 | 1 | 100.0 |
| 2621 | '560290' | 0 | 1 | 1 | 100.0 |
| 2622 | '560311' | 0 | 2 | 2 | 100.0 |
2623 rows × 5 columns
# Compute total, agricultural, and non-agricultural averages
total_avg = binding_coverage["BindingCoverage"].mean()
ag_avg = binding_coverage.loc[binding_coverage["ag"] == 1, "BindingCoverage"].mean()
nonag_avg = binding_coverage.loc[binding_coverage["ag"] == 0, "BindingCoverage"].mean()
# Save results to a DataFrame
summary_df = pd.DataFrame(
{
"Summary": ["Simple average binding coverage"],
"Total": [total_avg],
"Ag": [ag_avg],
"NonAg": [nonag_avg],
}
)
summary_df.round(2)
| Summary | Total | Ag | NonAg | |
|---|---|---|---|---|
| 0 | Simple average binding coverage | 99.68 | 100.0 | 99.56 |
비종가세 비율#
HS 6단위의 각 품목별로 비종가세의 비율을 구함.
품목별 비종가세 비율 계산
hs6와 ag의 각 고유 조합에 대해 데이터를 그룹화하여 각 그룹 내 nav 열의 값을 합산하여 total_nav이라는 새 열을 만들고, 각 그룹 내 nav 열의 값의 개수를 세어 nrtl라는 새 열을 만든다.
nav_share = can_bounds_new.groupby(["hs6", "ag"]).agg(
nav_sum=("nav", "sum"), nav_count=("nav", "count")
).reset_index()
nav_share["NAVshare"] = (
nav_share["nav_sum"] / nav_share["nav_count"] * 100
)
nav_share
| hs6 | ag | nav_sum | nav_count | NAVshare | |
|---|---|---|---|---|---|
| 0 | '010110' | 1 | 0 | 1 | 0.0 |
| 1 | '010190' | 1 | 0 | 1 | 0.0 |
| 2 | '010210' | 1 | 0 | 1 | 0.0 |
| 3 | '010290' | 1 | 1 | 2 | 50.0 |
| 4 | '010310' | 1 | 0 | 1 | 0.0 |
| ... | ... | ... | ... | ... | ... |
| 2618 | '560210' | 0 | 0 | 2 | 0.0 |
| 2619 | '560221' | 0 | 0 | 2 | 0.0 |
| 2620 | '560229' | 0 | 0 | 1 | 0.0 |
| 2621 | '560290' | 0 | 0 | 1 | 0.0 |
| 2622 | '560311' | 0 | 0 | 2 | 0.0 |
2623 rows × 5 columns
# Compute total, agricultural, and non-agricultural averages
total_avg = nav_share['NAVshare'].mean()
ag_avg = nav_share.loc[nav_share["ag"] == 1, "NAVshare"].mean()
nonag_avg = nav_share.loc[nav_share["ag"] == 0, "NAVshare"].mean()
# Save results to a DataFrame
summary_df = pd.DataFrame(
{
"Summary": ["Simple average nav share"],
"Total": [total_avg],
"Ag": [ag_avg],
"NonAg": [nonag_avg],
}
)
summary_df.round(2)
| Summary | Total | Ag | NonAg | |
|---|---|---|---|---|
| 0 | Simple average nav share | 5.21 | 17.85 | 0.69 |
MFN 평균 실행관세율#
CAN_DutyDetails.dta 불러들임.
캐나다 2008년 실행관세 데이터임.
# Load CAN_DutyDetails dataset
can_duty_details = pd.read_stata("../Data/CAN_DutyDetails.dta")
can_duty_details = can_duty_details[can_duty_details["tls"] != "'00'"]
can_duty_details.shape
(39417, 23)
최혜국(MFN) 실행관세율 추려내기
print(can_duty_details['nationaldescription'].unique())
['MFN applied duty rates'
'Preferential duty rates for Commonwealth Caribbean Countries'
'Least Developed Countries (LDC) duties'
'Free-trade agreement duty rate for Chile (CCFTA)'
'Free-trade area duty rate for the United States under the North American Free Trade Agreement (NAFTA)'
'Free-trade agreement duty rate for Costa Rica'
'Free-trade area duty rate for Mexico under the North American Free Trade Agreement (NAFTA)'
'Generalized System of Preferences (GSP) scheme'
'Preferential duty rates for Australia'
'Preferential duty rates for New Zealand'
'Free-trade area duty rate for Mexico-United States under the North American Free Trade Agreement (NAFTA)'
'Free-trade agreement duty rate for Israel (CIFTA)']
can_mfn = can_duty_details[
can_duty_details["nationaldescription"] == "MFN applied duty rates"
]
can_mfn
| queryname | basenomenclature | classification | reporter | reportercode | year | subid | tl | tls | dutytypecode | ... | dutynature | bindingcode | bindingcoverageflag | description1 | description2 | description3 | partnername | nationaldescription | dutydescription | v23 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | Harmonized System 2007 | HS - WTO Agricultural Products Definition | Canada | '124' | 2008 | 1 | '01011000' | '02' | ... | A | NaN | NaN | Pure-bred breeding animals | Not applicable/not available | Ad valorem duty | - | MFN applied duty rates | 02- MFN statutory (legal/autonomous) duty | NaN | |
| 1 | NaN | Harmonized System 2007 | HS - WTO Agricultural Products Definition | Canada | '124' | 2008 | 1 | '01019000' | '02' | ... | A | NaN | NaN | Other | Not applicable/not available | Ad valorem duty | - | MFN applied duty rates | 02- MFN statutory (legal/autonomous) duty | NaN | |
| 2 | NaN | Harmonized System 2007 | HS - WTO Agricultural Products Definition | Canada | '124' | 2008 | 1 | '01021000' | '02' | ... | A | NaN | NaN | Pure-bred breeding animals | Not applicable/not available | Ad valorem duty | - | MFN applied duty rates | 02- MFN statutory (legal/autonomous) duty | NaN | |
| 3 | NaN | Harmonized System 2007 | HS - WTO Agricultural Products Definition | Canada | '124' | 2008 | 1 | '01029000' | '02' | ... | A | NaN | NaN | Other | Not applicable/not available | Ad valorem duty | - | MFN applied duty rates | 02- MFN statutory (legal/autonomous) duty | NaN | |
| 4 | NaN | Harmonized System 2007 | HS - WTO Agricultural Products Definition | Canada | '124' | 2008 | 1 | '01031000' | '02' | ... | A | NaN | NaN | Pure-bred breeding animals | Not applicable/not available | Ad valorem duty | - | MFN applied duty rates | 02- MFN statutory (legal/autonomous) duty | NaN | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 39412 | NaN | Harmonized System 2007 | HS - WTO Non-agricultural Products Definition | Canada | '124' | 2008 | 1 | '97020000' | '02' | ... | A | NaN | NaN | Original engravings, prints and lithographs. ... | Not applicable/not available | Ad valorem duty | - | MFN applied duty rates | 02- MFN statutory (legal/autonomous) duty | NaN | |
| 39413 | NaN | Harmonized System 2007 | HS - WTO Non-agricultural Products Definition | Canada | '124' | 2008 | 1 | '97030000' | '02' | ... | A | NaN | NaN | Original sculptures and statuary, in any mate... | Not applicable/not available | Ad valorem duty | - | MFN applied duty rates | 02- MFN statutory (legal/autonomous) duty | NaN | |
| 39414 | NaN | Harmonized System 2007 | HS - WTO Non-agricultural Products Definition | Canada | '124' | 2008 | 1 | '97040000' | '02' | ... | A | NaN | NaN | Postage or revenue stamps, stamp-postmarks, f... | Not applicable/not available | Ad valorem duty | - | MFN applied duty rates | 02- MFN statutory (legal/autonomous) duty | NaN | |
| 39415 | NaN | Harmonized System 2007 | HS - WTO Non-agricultural Products Definition | Canada | '124' | 2008 | 1 | '97050000' | '02' | ... | A | NaN | NaN | Collections and collectors' pieces of zoologi... | Not applicable/not available | Ad valorem duty | - | MFN applied duty rates | 02- MFN statutory (legal/autonomous) duty | NaN | |
| 39416 | NaN | Harmonized System 2007 | HS - WTO Non-agricultural Products Definition | Canada | '124' | 2008 | 1 | '97060000' | '02' | ... | A | NaN | NaN | Antiques of an age exceeding one hundred years... | Not applicable/not available | Ad valorem duty | - | MFN applied duty rates | 02- MFN statutory (legal/autonomous) duty | NaN |
8432 rows × 23 columns
print(can_mfn.columns)
Index(['queryname', 'basenomenclature', 'classification', 'reporter',
'reportercode', 'year', 'subid', 'tl', 'tls', 'dutytypecode', 'partner',
'avdutyrate', 'specificdutyrate', 'dutynature', 'bindingcode',
'bindingcoverageflag', 'description1', 'description2', 'description3',
'partnername', 'nationaldescription', 'dutydescription', 'v23'],
dtype='object')
필요 변수 만들기
농업 제품 더미변수
비종가세 더미변수
HS 6자리 코드
# Make an explicit copy of the DataFrame
can_mfn = can_mfn.copy()
# Create agricultural product dummy for can_mfn
can_mfn["ag"] = np.where(
can_mfn["classification"] == "HS - WTO Agricultural Products Definition", 1, 0
)
# Create non ad-valorem duty dummy
can_mfn["nav"] = np.where(
can_mfn["description3"] != "Ad valorem duty", 1, 0
)
# Create hs6 classification
can_mfn["hs6"] = can_mfn["tl"].str[:7] + "'"
평균 실행관세율 계산
# Compute simple average MFN applied
mfn_aggregated = (
can_mfn.groupby(["hs6", "ag"])["avdutyrate"].mean().reset_index()
)
# Compute averages
total_avg = mfn_aggregated["avdutyrate"].mean()
ag_avg = mfn_aggregated.loc[mfn_aggregated["ag"] == 1, "avdutyrate"].mean()
nonag_avg = mfn_aggregated.loc[mfn_aggregated["ag"] == 0, "avdutyrate"].mean()
# Save results to a DataFrame
summary_df = pd.DataFrame(
{
"Summary": ["Simple average MFN applied"],
"Total": [total_avg],
"Ag": [ag_avg],
"NonAg": [nonag_avg],
}
)
summary_df.round(2)
| Summary | Total | Ag | NonAg | |
|---|---|---|---|---|
| 0 | Simple average MFN applied | 3.6 | 3.21 | 3.66 |
품목별 비종가세 비율 계산
hs6와 ag의 각 고유 조합에 대해 데이터를 그룹화하여 각 그룹 내 nav 열의 값을 합산하여 total_nav이라는 새 열을 만들고, 각 그룹 내 nav 열의 값의 개수를 세어 nrtl라는 새 열을 만든다.
nav_share = can_mfn.groupby(["hs6", "ag"]).agg(
nav_sum=("nav", "sum"), nav_count=("nav", "count")
).reset_index()
nav_share["NAVshare"] = (
nav_share["nav_sum"] / nav_share["nav_count"] * 100
)
nav_share
| hs6 | ag | nav_sum | nav_count | NAVshare | |
|---|---|---|---|---|---|
| 0 | '010110' | 1 | 0 | 1 | 0.0 |
| 1 | '010190' | 1 | 0 | 1 | 0.0 |
| 2 | '010210' | 1 | 0 | 1 | 0.0 |
| 3 | '010290' | 1 | 0 | 1 | 0.0 |
| 4 | '010310' | 1 | 0 | 1 | 0.0 |
| ... | ... | ... | ... | ... | ... |
| 5047 | '970200' | 0 | 0 | 1 | 0.0 |
| 5048 | '970300' | 0 | 0 | 1 | 0.0 |
| 5049 | '970400' | 0 | 0 | 1 | 0.0 |
| 5050 | '970500' | 0 | 0 | 1 | 0.0 |
| 5051 | '970600' | 0 | 0 | 1 | 0.0 |
5052 rows × 5 columns
# Compute total, agricultural, and non-agricultural averages
total_avg = nav_share['NAVshare'].mean()
ag_avg = nav_share.loc[nav_share["ag"] == 1, "NAVshare"].mean()
nonag_avg = nav_share.loc[nav_share["ag"] == 0, "NAVshare"].mean()
# Save results to a DataFrame
summary_df = pd.DataFrame(
{
"Summary": ["Share of non ad valorem duty in MFN applied"],
"Total": [total_avg],
"Ag": [ag_avg],
"NonAg": [nonag_avg],
}
)
summary_df.round(2)
| Summary | Total | Ag | NonAg | |
|---|---|---|---|---|
| 0 | Share of non ad valorem duty in MFN applied | 1.71 | 12.69 | 0.05 |
무역 가중평균 MFN 실행관세율#
CAN_TradeDetails.dta 파일과 병합하여 무역 가중평균을 계산한다.
“All Origins”의 총수입액(단위: 10억 달러)과 HS6 수준의 평균만 고려한다.
관세품목별 수입액 데이터 불러오기
“All Origins”의 총수입액
trade_details = pd.read_stata("../Data/CAN_TradeDetails.dta")
trade_details.shape
(121716, 20)
trade_details.columns
Index(['queryname', 'basenomenclature', 'classification', 'reporter',
'reportercode', 'year', 'subid', 'tl', 'tls', 'value', 'natvalue',
'quantity', 'abbreviation', 'share', 'rank', 'partner', 'name',
'unitvalue', 'recordstatus', 'v20'],
dtype='object')
can_imp = trade_details[trade_details['name'] == "All Origins"][['tl', 'name', 'value']]
can_imp.rename(columns={'value': 'import_values'}, inplace=True)
can_imp.sort_values(by='tl', inplace=True)
can_imp
| tl | name | import_values | |
|---|---|---|---|
| 3 | '01011000' | All Origins | 7414.230957 |
| 11 | '01019000' | All Origins | 60022.085938 |
| 19 | '01021000' | All Origins | 3528.814941 |
| 21 | '01029000' | All Origins | 5923.375000 |
| 23 | '01031000' | All Origins | 506.005005 |
| ... | ... | ... | ... |
| 121488 | '97020000' | All Origins | 14156.569336 |
| 121534 | '97030000' | All Origins | 40397.253906 |
| 121581 | '97040000' | All Origins | 3892.829102 |
| 121633 | '97050000' | All Origins | 19766.447266 |
| 121686 | '97060000' | All Origins | 29859.830078 |
8210 rows × 3 columns
MFN 실행관세율 데이터
avdutyrate
# Aggregate sub-products at hs8
can_mfn = can_mfn.groupby(['tl', 'hs6', 'ag']).agg({'avdutyrate': 'mean', 'nav': 'mean'}).reset_index()
can_mfn
| tl | hs6 | ag | avdutyrate | nav | |
|---|---|---|---|---|---|
| 0 | '01011000' | '010110' | 1 | 0.0 | 0.0 |
| 1 | '01019000' | '010190' | 1 | 0.0 | 0.0 |
| 2 | '01021000' | '010210' | 1 | 0.0 | 0.0 |
| 3 | '01029000' | '010290' | 1 | 0.0 | 0.0 |
| 4 | '01031000' | '010310' | 1 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... |
| 8427 | '97020000' | '970200' | 0 | 0.0 | 0.0 |
| 8428 | '97030000' | '970300' | 0 | 0.0 | 0.0 |
| 8429 | '97040000' | '970400' | 0 | 0.0 | 0.0 |
| 8430 | '97050000' | '970500' | 0 | 0.0 | 0.0 |
| 8431 | '97060000' | '970600' | 0 | 0.0 | 0.0 |
8432 rows × 5 columns
MFN 실행관세율 + 수입액 병합
# Merge with the duty data
can_imp = can_imp.merge(can_mfn, on='tl', how='inner')
can_imp.sort_values(by='hs6', inplace=True)
can_imp
| tl | name | import_values | hs6 | ag | avdutyrate | nav | |
|---|---|---|---|---|---|---|---|
| 0 | '01011000' | All Origins | 7414.230957 | '010110' | 1 | 0.0 | 0.0 |
| 1 | '01019000' | All Origins | 60022.085938 | '010190' | 1 | 0.0 | 0.0 |
| 2 | '01021000' | All Origins | 3528.814941 | '010210' | 1 | 0.0 | 0.0 |
| 3 | '01029000' | All Origins | 5923.375000 | '010290' | 1 | 0.0 | 0.0 |
| 4 | '01031000' | All Origins | 506.005005 | '010310' | 1 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 8205 | '97020000' | All Origins | 14156.569336 | '970200' | 0 | 0.0 | 0.0 |
| 8206 | '97030000' | All Origins | 40397.253906 | '970300' | 0 | 0.0 | 0.0 |
| 8207 | '97040000' | All Origins | 3892.829102 | '970400' | 0 | 0.0 | 0.0 |
| 8208 | '97050000' | All Origins | 19766.447266 | '970500' | 0 | 0.0 | 0.0 |
| 8209 | '97060000' | All Origins | 29859.830078 | '970600' | 0 | 0.0 | 0.0 |
8210 rows × 7 columns
HS6 소호별로 합산
평균 실행관세율(
avdutyrate)평균 비종가세 더미변수(
nav)총 수입액(
import_values)
# Aggregate at HS6-subheading
agg = can_imp.groupby(['hs6', 'ag']).agg(
avdutyrate=('avdutyrate', 'mean'),
nav=('nav', 'mean'),
value=('import_values', 'sum')
).reset_index()
총수입액 계산
단위: 10억 달러
Mtot: 총수입액MtotAg: 농업제품 총수입액MtotNonAg: 비농업제품 총수입액
agg['Mtot'] = agg['value'].sum()
agg['MtotAg'] = agg.loc[agg['ag'] == 1, 'value'].sum()
agg['MtotNonAg'] = agg.loc[agg['ag'] == 0, 'value'].sum()
agg
| hs6 | ag | avdutyrate | nav | value | Mtot | MtotAg | MtotNonAg | |
|---|---|---|---|---|---|---|---|---|
| 0 | '010110' | 1 | 0.0 | 0.0 | 7414.230957 | 397087232.0 | 26136516.0 | 370950720.0 |
| 1 | '010190' | 1 | 0.0 | 0.0 | 60022.085938 | 397087232.0 | 26136516.0 | 370950720.0 |
| 2 | '010210' | 1 | 0.0 | 0.0 | 3528.814941 | 397087232.0 | 26136516.0 | 370950720.0 |
| 3 | '010290' | 1 | 0.0 | 0.0 | 5923.375000 | 397087232.0 | 26136516.0 | 370950720.0 |
| 4 | '010310' | 1 | 0.0 | 0.0 | 506.005005 | 397087232.0 | 26136516.0 | 370950720.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 5013 | '970200' | 0 | 0.0 | 0.0 | 14156.569336 | 397087232.0 | 26136516.0 | 370950720.0 |
| 5014 | '970300' | 0 | 0.0 | 0.0 | 40397.253906 | 397087232.0 | 26136516.0 | 370950720.0 |
| 5015 | '970400' | 0 | 0.0 | 0.0 | 3892.829102 | 397087232.0 | 26136516.0 | 370950720.0 |
| 5016 | '970500' | 0 | 0.0 | 0.0 | 19766.447266 | 397087232.0 | 26136516.0 | 370950720.0 |
| 5017 | '970600' | 0 | 0.0 | 0.0 | 29859.830078 | 397087232.0 | 26136516.0 | 370950720.0 |
5018 rows × 8 columns
df = agg[['Mtot', 'MtotAg', 'MtotNonAg']].drop_duplicates() / 1e6
# Save results to a DataFrame
summary_df = pd.DataFrame(
{
"Summary": ["Imports in billion US$"],
"Total": df['Mtot'],
"Ag": df['MtotAg'],
"NonAg": df['MtotNonAg']
}
)
summary_df.round(2)
| Summary | Total | Ag | NonAg | |
|---|---|---|---|---|
| 0 | Imports in billion US$ | 397.089996 | 26.139999 | 370.950012 |
수입액 기준 가중평균 계산
전체 가중평균 실행관세율
농업제품 가중평균 실행관세율
비농업제품 가중평균 실행관세율
agg['Total'] = (
agg['avdutyrate'] * agg['value']
).sum() / agg['Mtot']
agg['Ag'] = (
agg.loc[agg['ag'] == 1, 'avdutyrate'] * agg.loc[agg['ag'] == 1, 'value']
).sum() / agg['MtotAg']
agg['NonAg'] = (
agg.loc[agg['ag'] == 0, 'avdutyrate'] * agg.loc[agg['ag'] == 0, 'value']
).sum() / agg['MtotNonAg']
df = agg[['Total', 'Ag', 'NonAg']].drop_duplicates()
# Save results to a DataFrame
summary_df = pd.DataFrame(
{
"Summary": ["Trade weighted average MFN applied"],
"Total": df['Total'],
"Ag": df['Ag'],
"NonAg": df['NonAg']
}
)
summary_df.round(2)
| Summary | Total | Ag | NonAg | |
|---|---|---|---|---|
| 0 | Trade weighted average MFN applied | 2.73 | 3.2 | 2.7 |
품목별 비종가세 비율 계산
hs6와 ag의 각 고유 조합에 대해 데이터를 그룹화하여 각 그룹 내 nav 열의 값을 합산하여 total_nav이라는 새 열을 만들고, 각 그룹 내 nav 열의 값의 개수를 세어 nrtl라는 새 열을 만든다.
nav_share = can_imp.groupby(["hs6", "ag"]).agg(
nav_sum=("nav", "sum"), nav_count=("nav", "count")
).reset_index()
nav_share["NAVshare"] = (
nav_share["nav_sum"] / nav_share["nav_count"] * 100
)
nav_share
| hs6 | ag | nav_sum | nav_count | NAVshare | |
|---|---|---|---|---|---|
| 0 | '010110' | 1 | 0.0 | 1 | 0.0 |
| 1 | '010190' | 1 | 0.0 | 1 | 0.0 |
| 2 | '010210' | 1 | 0.0 | 1 | 0.0 |
| 3 | '010290' | 1 | 0.0 | 1 | 0.0 |
| 4 | '010310' | 1 | 0.0 | 1 | 0.0 |
| ... | ... | ... | ... | ... | ... |
| 5013 | '970200' | 0 | 0.0 | 1 | 0.0 |
| 5014 | '970300' | 0 | 0.0 | 1 | 0.0 |
| 5015 | '970400' | 0 | 0.0 | 1 | 0.0 |
| 5016 | '970500' | 0 | 0.0 | 1 | 0.0 |
| 5017 | '970600' | 0 | 0.0 | 1 | 0.0 |
5018 rows × 5 columns
# Compute total, agricultural, and non-agricultural averages
total_avg = nav_share['NAVshare'].mean()
ag_avg = nav_share.loc[nav_share["ag"] == 1, "NAVshare"].mean()
nonag_avg = nav_share.loc[nav_share["ag"] == 0, "NAVshare"].mean()
# Save results to a DataFrame
summary_df = pd.DataFrame(
{
"Summary": ["Share of non ad valorem duty in imports"],
"Total": [total_avg],
"Ag": [ag_avg],
"NonAg": [nonag_avg],
}
)
summary_df.round(2)
| Summary | Total | Ag | NonAg | |
|---|---|---|---|---|
| 0 | Share of non ad valorem duty in imports | 1.57 | 11.66 | 0.06 |
6. 관세 범위별 빈도 분포#
groupby mapping 예시
# 예시 데이터프레임 생성
example = {
'ag': ['1', '1', '0', '0', '0', '0'],
'range': ['A', 'A', 'A', 'B', 'B', 'NAV'],
'bounddutyav': [10, np.nan, 30, 40, 50, np.nan]
}
example = pd.DataFrame(example)
# 각 그룹의 크기를 계산해서 시리즈로 변환
group_sizes_a = example.groupby("ag").size()
group_sizes_ra = example.groupby(["range", "ag"]).size()
# 인덱스를 기준으로 크기를 매핑
example["nr_a"] = example["ag"].map(group_sizes_a)
example["nr_ra"] = example.set_index(["range", "ag"]).index.map(group_sizes_ra)
print(example)
ag range bounddutyav nr_a nr_ra
0 1 A 10.0 2 2
1 1 A NaN 2 2
2 0 A 30.0 4 1
3 0 B 40.0 4 2
4 0 B 50.0 4 2
5 0 NAV NaN 4 1
can_bounds#
df = can_bounds_new
df.shape
(4555, 9)
# Create range for frequency distribution
conditions = [
df["bounddutyav"] == 0,
(df["bounddutyav"] > 0) & (df["bounddutyav"] <= 5),
(df["bounddutyav"] > 5) & (df["bounddutyav"] <= 10),
(df["bounddutyav"] > 10) & (df["bounddutyav"] <= 15),
(df["bounddutyav"] > 15) & (df["bounddutyav"] <= 25),
(df["bounddutyav"] > 25) & (df["bounddutyav"] <= 50),
(df["bounddutyav"] > 50) & (df["bounddutyav"] <= 100),
df["bounddutyav"] > 100,
df["bounddutyav"].isna()
]
ranges = [
"Duty-free", "0 <= 5", "5 <= 10", "10 <= 15",
"15 <= 25", "25 <= 50", "50 <= 100", "> 100", "NAV"
]
df["range"] = np.select(conditions, ranges, default="N.A.")
# Compute frequency distribution
group_sizes = df.groupby("ag").size()
df["nr_a"] = df["ag"].map(group_sizes)
group_sizes = df.groupby(["range", "ag"]).size()
df["nr_ra"] = df.set_index(["range", "ag"]).index.map(group_sizes)
df["freqAg"] = np.where(df["ag"] == 1, df["nr_ra"] / df["nr_a"] * 100, np.nan)
df["freqNonAg"] = np.where(df["ag"] == 0, df["nr_ra"] / df["nr_a"] * 100, np.nan)
# Drop duplicates and save
final_bounds = df.groupby("range").agg({
"freqAg": "max",
"freqNonAg": "max"
}).reset_index()
final_bounds['range'] = pd.Categorical(final_bounds['range'], categories=ranges, ordered=True)
final_bounds = final_bounds.sort_values('range').reset_index(drop=True)
final_bounds.round(2)
| range | freqAg | freqNonAg | |
|---|---|---|---|
| 0 | Duty-free | 32.80 | 34.92 |
| 1 | 0 <= 5 | 11.30 | 6.99 |
| 2 | 5 <= 10 | 18.47 | 46.30 |
| 3 | 10 <= 15 | 5.44 | 10.73 |
| 4 | 15 <= 25 | 0.69 | 0.32 |
| 5 | 25 <= 50 | 0.48 | NaN |
| 6 | 50 <= 100 | 0.14 | NaN |
| 7 | > 100 | 0.28 | NaN |
| 8 | NAV | 30.39 | 0.74 |
can_mfn#
df = can_mfn
df.shape
(8432, 5)
# Create range for frequency distribution
conditions = [
df["avdutyrate"] == 0,
(df["avdutyrate"] > 0) & (df["avdutyrate"] <= 5),
(df["avdutyrate"] > 5) & (df["avdutyrate"] <= 10),
(df["avdutyrate"] > 10) & (df["avdutyrate"] <= 15),
(df["avdutyrate"] > 15) & (df["avdutyrate"] <= 25),
(df["avdutyrate"] > 25) & (df["avdutyrate"] <= 50),
(df["avdutyrate"] > 50) & (df["avdutyrate"] <= 100),
df["avdutyrate"] > 100,
df["avdutyrate"].isna()
]
ranges = [
"Duty-free", "0 <= 5", "5 <= 10", "10 <= 15",
"15 <= 25", "25 <= 50", "50 <= 100", "> 100", "NAV"
]
df["range"] = np.select(conditions, ranges, default="N.A.")
# Compute frequency distribution
group_sizes = df.groupby("ag").size()
df["nr_a"] = df["ag"].map(group_sizes)
group_sizes = df.groupby(["range", "ag"]).size()
df["nr_ra"] = df.set_index(["range", "ag"]).index.map(group_sizes)
df["freqAg"] = np.where(df["ag"] == 1, df["nr_ra"] / df["nr_a"] * 100, np.nan)
df["freqNonAg"] = np.where(df["ag"] == 0, df["nr_ra"] / df["nr_a"] * 100, np.nan)
# Drop duplicates and save
final_bounds = df.groupby("range").agg({
"freqAg": "max",
"freqNonAg": "max"
}).reset_index()
final_bounds['range'] = pd.Categorical(final_bounds['range'], categories=ranges, ordered=True)
final_bounds = final_bounds.sort_values('range').reset_index(drop=True)
final_bounds.round(2)
| range | freqAg | freqNonAg | |
|---|---|---|---|
| 0 | Duty-free | 39.04 | 53.82 |
| 1 | 0 <= 5 | 10.67 | 11.47 |
| 2 | 5 <= 10 | 15.86 | 22.88 |
| 3 | 10 <= 15 | 5.41 | 6.21 |
| 4 | 15 <= 25 | 0.73 | 5.45 |
| 5 | 25 <= 50 | 0.51 | NaN |
| 6 | 50 <= 100 | 0.15 | NaN |
| 7 | > 100 | 0.29 | NaN |
| 8 | NAV | 27.34 | 0.17 |
can_imp#
df = can_imp
# Create range for frequency distribution
conditions = [
df["avdutyrate"] == 0,
(df["avdutyrate"] > 0) & (df["avdutyrate"] <= 5),
(df["avdutyrate"] > 5) & (df["avdutyrate"] <= 10),
(df["avdutyrate"] > 10) & (df["avdutyrate"] <= 15),
(df["avdutyrate"] > 15) & (df["avdutyrate"] <= 25),
(df["avdutyrate"] > 25) & (df["avdutyrate"] <= 50),
(df["avdutyrate"] > 50) & (df["avdutyrate"] <= 100),
df["avdutyrate"] > 100,
df["avdutyrate"].isna()
]
ranges = [
"Duty-free", "0 <= 5", "5 <= 10", "10 <= 15",
"15 <= 25", "25 <= 50", "50 <= 100", "> 100", "NAV"
]
df["range"] = np.select(conditions, ranges, default="N.A.")
# Compute frequency distribution
group_sums = df.groupby("ag")["import_values"].sum()
df["tot_a"] = df["ag"].map(group_sums)
group_sums = df.groupby(["range", "ag"])["import_values"].sum()
df["tot_ra"] = df.set_index(["range", "ag"]).index.map(group_sums)
df["freqAg"] = np.where(df["ag"] == 1, df["tot_ra"] / df["tot_a"] * 100, np.nan)
df["freqNonAg"] = np.where(df["ag"] == 0, df["tot_ra"] / df["tot_a"] * 100, np.nan)
# Drop duplicates and save
final_bounds = df.groupby("range").agg({
"freqAg": "max",
"freqNonAg": "max"
}).reset_index()
final_bounds['range'] = pd.Categorical(final_bounds['range'], categories=ranges, ordered=True)
final_bounds = final_bounds.sort_values('range').reset_index(drop=True)
final_bounds.round(2)
| range | freqAg | freqNonAg | |
|---|---|---|---|
| 0 | Duty-free | 50.860001 | 59.040001 |
| 1 | 0 <= 5 | 5.940000 | 5.380000 |
| 2 | 5 <= 10 | 15.110000 | 31.700001 |
| 3 | 10 <= 15 | 10.030000 | 0.950000 |
| 4 | 15 <= 25 | 0.120000 | 2.910000 |
| 5 | 25 <= 50 | 2.000000 | NaN |
| 6 | 50 <= 100 | 0.000000 | NaN |
| 7 | > 100 | 0.000000 | NaN |
| 8 | NAV | 15.940000 | 0.010000 |